

CAIDA's Annual Report for 2006
Mission Statement: CAIDA investigates both practical and theoretical aspects of the Internet, with particular focus on topics that:
- are macroscopic in nature and provide enhanced insight into the function of Internet infrastructure worldwide,
- improve the integrity of the field of Internet science,
- improve the integrity of operational Internet measurement and management,
- inform science, technology, and communications public policies.
Executive Summary
This annual report covers CAIDA's activites in 2006, summarizing highlights from our research, infrastructure, and outreach activities. Our current research projects, primarily funded by the U.S. National Science Foundation (NSF), include several measurement-based studies of the Internet's core infrastructure, with focus on the health and integrity of the global Internet's topology, routing, addressing, and naming system. Our infrastructure activities, funded by NSF and DHS as well as other government and industry sources, include building a catalog of Internet measurement data sets, contributing to the (DHS-funded) PREDICT repository of datasets to support the (U.S.-based) network research community, and developing and deploying active and passive measurement infrastructure that cost-effectively supports the global Internet research community. We also lead and participate in tool development to support measurement, analysis, indexing, and dissemination of data from operational global Internet infrastructure. Finally, we engage in a variety of outreach activities, including web sites, peer-reviewed papers, technical reports, presentations, blogging, animations, and workshops. CAIDA's program plan for 2007-2010 will be available in July 2007.
Background and recent history
For just over ten years CAIDA has undertaken various approaches to narrowing a gap that now impedes the field of network research as well as telecommunications policy: a dearth of available empirical data on the public Internet since the infrastructure privatized. We have managed to grow and maintain a research group through increasingly difficult science funding periods, yet over the last decade our ability to get data from the commercial Internet has gradually diminished, as has the quality of science in the field of Internet research.
As an Internet data analysis and research group largely supported with public funding to apply measurement and analysis toward understanding and solving globally relevant Internet engineering problems, we accept a responsibility to seek, analyze, and communicate the salient features of the best available data about the Internet. And of course, we want better answers to the oft-asked question by graduate students: ``What Internet research problems are important to work on?'?
In 2003, frustrated with both the lack of access to data and the lack of progress in the Internet research community on a number of important problems in the last ten years, we began a survey to find answers to three questions: (1) What are the top operational and engineering problems in the Internet?; (2) Are we making measurable progress toward solving them?; (3) For problems that we're not making progress on, what is blocking progress?
These problems span four dimensions of the Internet as emerging critical infrastructure: safety, scability, sustainability, and stewardship. Measurement made the list of problems, no surprise there. At CAIDA we have experienced how difficult measurement of operational infrastructure has been, but the biggest problems with measurement had long been economic (cost of instrumentation and data management), ownership (legal access to data), and trust (privacy and security obstacles to measurement). More surprising was that measurement was not unique in this regard: all persistently unsolved operational problems of the Internet are similarly blocked on issues of economics, ownership, and trust (EOT).
Expansion of research agenda into policy and economics
This lesson meant a change in strategy for CAIDA. We recognize it is no longer appropriate to pursue solutions to the Internet's problems without tackling the EOT issues. CAIDA's activities have spanned the four S's (security, scalability, sustainability, stewardship) for years, but we have begun to re-focus current projects, and pursue new projects, that specifically recognize and openly navigate the economic and policy issues via activities that cross the boundaries between technology and policy. The table below lists examples of how we have expanded our horizons in the last couple of years. Most current projects will continue into 2007.
| In addition to | we expanded our efforts to |
|---|---|
| collecting topology for use in modeling and simulation activities, | use the same data to provide a current ranking of Internet service providers according to sample observations of AS topology coverage (ASrank). |
| launching DatCat, for use by researchers to index data sets into a common catalog, | reach out to policymakers to show them how such a catalog could support informed policy making. |
| upgrading our measurement infrastructure and data curation tools to keep pace with technology changes and research community needs, | propose a project to provide otherwise non-existent incentive for operational networks to use these tools to contribute network measurements to the research community. |
| simulating routing protocols that could scale to billions of nodes, | simulate IPv4 address consumption scenarios for ARIN to support immediate policy needs. |
| providing the largest simultaneous collection of traffic to DNS root servers in support of the research community, | do macroscopic surveys of the health of the current DNS, and participate on two of ICANN's subcommittees (SSAC and RSSAC). |
If you have comments or questions, please do not hesitate to contact us at info at caida dot org.
Research Projects
CAIDA's research projects span numerous domains related to network science and engineering. We hope to make a tangible impact on the field of (Inter)networking research by providing researchers with increased access to real world data sets for validation of scientific models and the promotion of reproducible science.
Infrastructure Projects
Several of CAIDA's infrastructure projects cut across scientific and funding domains as they strive to provide long-term provision of data, services, and measurement infrastructure. In addition to raw data collection, distribution and archival efforts, the DatCat project offers improved metadata searching and indexing. Further, the PREDICT project develops legal and policy infrastructures for data sharing amongst data providers, data hosting sites, and researchers, respectively.
In 2006, CAIDA took over operational stewardship for all NLANR machines and data. CAIDA gracefully decommissioned obsolete hardware and data and attempted to apply the remaining resources to projects of similar intent and spirit.
DatCat: the Internet Measurement Data Catalog
The goal of this project is to build an Internet Measurement Data Catalog (IMDC) that will facilitate access, archiving, and long-term storage of Internet data as well as sharing the data among Internet researchers. After 3.5 years of development we finally launched the catalog in June 2006. Funding for the project also ended in 2006, so we are currently seeking funding to maintain and extend it.
Goals
CAIDA had three goals for the creation of the IMDC database:
- provide a searchable index of Internet data available for research
- enhance documentation of datasets via a public annotation system
- enable reproducible research in network science
Activities
In 2006, the Trends project completed its final year.
- DatCat
-
Our main priority was the development of DatCat, the Internet Measurement Data Catalog. This searchable catalog archives meta-data for Internet measurement data sets and provides information on data locations and access. We opened DatCat for public viewing on June 12, 2006 and continued to index new data sets and to improve user interfaces throughout the year.
CAIDA hosted the CRAWDAD: a Community Resource for Archiving Wireless Data At Dartmouth team for a small workshop aimed at inter-operation between these two NSF-funded catalogs. We hope to be able to automatically share data and meta-data between the DatCat and CRAWDAD catalogs in Fall of 2007.
- 1st DatCat Community Contribution (DCC 1) Workshop
-
We created this workshop series, and hosted the 1st DatCat Community Contribution (DCC 1) Workshop, to provide community members with the resources they need to contribute data to DatCat. At the time of writing, the First DatCat Community Contribution Workshop (DCC 1) Collection contains 1,239 files from 9 subcollections and 4 publications.
- Data Collection and Software Development
-
We collected and distributed data from passive monitors and 22 active monitors. 310 requests for data have been answered, with more than 220 research groups accessing our data.
We developed a new report generator tool that produces easily configurable, comprehensive, real-time summaries of network traffic on monitored links. The following traffic characteristics can be reported: packet, byte, and flow volume, number of source and destination IP addresses and Autonomous Systems, the geographic regions exchanging traffic, and the types of applications used. This metadata is also ideal information to index in DatCat.
- Data Analysis
-
We continued ongoing efforts to characterize the applications used for peer-to-peer file-sharing exchange and their prevalence on the Internet. We expect to publish new results in this area in 2007.
Major Milestones
- DatCat
-
- Opened DatCat to public viewing on June 12, 2006, initially with 12 collections of data from 3 organizations.
- Created browse interface that complements search interface by allowing users to view catalog contents without specific criteria in mind.
- Developed a comprehensive user Help section including a screen-shot based tutorial
- Augmented advanced search with additional query capabilities and made it more user friendly
- Added ability for users to add "note" annotations to any object
- Added BibTex citations to every DatCat object's detail page
- Releasing CAIDA data to the community
-
- Prepared and released six new datasets:
- Witty Worm Dataset (January 11, 2006)
- Code-Red Worms Dataset (February 1, 2006)
- Backscatter-2004-2005 Dataset (February 15, 2006)
- Backscatter 2006 Dataset (April 7, 2006)
- AS Taxonomy Dataset (April 14, 2006)
- DNS Root Server/gTLD RTT Dataset (August 3,2006)
- Prepared and released six new datasets:
- New traffic report generator
-
- Added geographic analysis of traffic.
- Added a flexible display so that users can view a variety of graphs and tables displaying different time periods.
- Added the ability to collect statistically valid sampled flows on high speed (OC49, OC192, 10GigE) links and display the sampled reports.
PREDICT: Network Traffic Data Repository to Develop Secure IT Infrastructure
Goals
The Protected Repository for the Defense of Infrastructure against Cyber Threats (PREDICT) was designed to provide sensitive security datasets to qualified researchers, while preserving privacy and preventing data misuse. PREDICT offers a secure technical and policy framework to process applications for data sharing from network providers, which includes tools for collection, processing, and hosting of data that will eventually be available through the program as well as secured infrastructure to support serving datasets to researchers. (Note that the PREDICT project has yet to launch, see www.predict.org for details.)
Activities
CAIDA's involvement in the effort, called the Protected Repository for the Defense of Infrastructure against Cyber Threats (PREDICT), includes assisting with: the technical framework to process applications for data; development of communications between Data Providers, Data Hosting Sites, and Researchers; collection and processing of data that will eventually be available through the program; developing and deploying infrastructure to allow CAIDA to serve datasets to researchers; and providing input for the development of a legal framework to support the project. In 2006, CAIDA helped develop Memoranda of Agreements to allow CAIDA to participate in the launch of the PREDICT program as a data provider and a data hosting site, serving OC48 backbone peering link data, denial-of-service backscatter data, Internet worm data, Network Telescope data, and IP topology data to approved researchers.
Major Milestones
- Macroscopic Topology Data Collection
-
- We collected 623 GB (9,181 files) of macroscopic topology measurements for distribution via PREDICT, bringing our total macroscopic topology data collection to 3.5 TB.
- Security Data Collection
-
- We collected 19.4 TB (8,545 files) of security measurements from the UCSD network telescope for distribution via PREDICT, bringing our total security data collection to 52.8 TB.
- New Datasets Released
-
- Witty Worm Dataset (January 11, 2006)
- Code-Red Worms Dataset (February 1, 2006)
- Backscatter-2004-2005 Dataset (February 15, 2006)
- Backscatter-2006 Dataset (April 7, 2006)
- AS Taxonomy Repository (April 14, 2006)
- the DNS Root Server/gTLD RTT Dataset (August 3, 2006)
Archipelago (Ark): A Coordination-Oriented Measurement Infrastructure
Goals
This year, CAIDA began development of Archipelago (Ark), our next generation active measurement infrastructure supporting the Macroscopic Topology Project. We intend for Ark to eventually replace the previous skitter-based infrastructure. Inspired by the Community-Oriented Network Measurement Infrastructure (CONMI) Workshop Report, Ark aspires to achieve greater scalability and flexibility than our current measurement infrastructure and provides steps toward a community-oriented network measurement infrastructure intended to eventually allow collaborators to run their vetted measurement tasks on a security-hardened distributed platform.
We designed Ark with macroscopic topology as its first target application, using the scamper tool to measure topology and latency to large numbers of IPv4 and IPv6 addresses. Once Ark is established and stable, CAIDA intends for the infrastructure to support numerous other types of data collection, measurements and experiments, e.g., one-way loss, bandwidth estimation, DNS performance, router alias resolution, and more. Although geared toward active measurement, Ark could also enable some types of passive measurement.
Ark's design represents a new approach to coordinating the activities of a measurement infrastructure, including supporting multiple researchers attempting different types of measurements. Archipelago's coordination facility is called Marinda, loosely inspired by David Gelernter's tuple-space based Linda coordination language. Archipelago extends Gelernter's tuple space model with features needed to support a globally distributed measurement infrastructure that hosts heterogeneous measurements by a community of researchers.
Activities
The need to extend our aging active measurement architecture to support a wider variety of measurements spurred Ark's design and development. We upgraded the infrastructure to probe a broader range of dynamically generated IP addresses covering all /24 prefixes in the IPv4 address space. We also improved our mechanisms for signaling file and cycle completion.
Major Milestones
In its first year, the Ark project met the following milestones.
- complete initial architecture and design of Archipelago, including security features, communication and coordination facilities, software configuration and installation, and data storage and management.
- initial implementation and testing
- Presentation:
-
-
Young Hyun presented The Archipelago Measurement Infrastructure at the 7th CAIDA-WIDE Workshop, Nov 2006.
-
National Laboratory for Advanced Network Research (NLANR) Resource Stewardship
Goals
The National Laboratory for Applied Network Research (NLANR) Project officially ended February 28, 2006. The funding for the NLANR project expired June 30, 2006 and the National Science Foundation has no plans to continue support. Starting in July 2006, CAIDA took over operational stewardship for all NLANR machines and data. Some of the NLANR data and resources still offer value to the network science, research and development communities, and can help support other forms of network research. Since much of the equipment is too old to maintain, CAIDA conducted a careful audit, gracefully decommissioned obsolete hardware and data, and attempted to apply the remaining resources to similar projects at CAIDA. As we performed this audit, we informed the community of changes to operations of the machines at the sites. At any time hosting sites may decline participation in our measurement activities, but so far many have found our proposed use sufficiently relevant to continue hosting a measurement platform.
NLANR Resources
- The NLANR.NET Domain and Services
CAIDA (temporarily) stewards the NLANR.NET domain, originally registered by Hans-Werner Braun, as well as eleven servers used to serve the various mail, web, application, and database services for the project, including serving the data collected by the Active Measurement Project (AMP) and Passive Measurement and Analysis (PMA) projects.
- PMA Project Resource Reuse
Of 33 original passive collection sites, fourteen appear to have been decommissioned by NLANR staff prior to July 2006. CAIDA has decommissioned five sites with outdated hardware. Seven sites have sufficiently modern equipment that we hope to repurpose them for passive data collection and reporting. Of the remaining nine monitors, eight were connected to a router located at the Indianapolis Internet2 site. This router is no longer part of the Internet2 infrastructure, however, the instruments are capable of measuring oc192/10Gb links so we hope to repurpose them. The final site in Los Angeles hosts the lambdaMON optical network tap, but we have yet to revive it. CAIDA is still working with sites with viable hardware to get acceptable use policies in place to continue to conduct measurement experiments.
- AMP Project Resource Reuse
Of over 150 original active collection sites, approximately 30 have hardware that CAIDA may be able to reuse for its Macroscopic Topology Measurements Project, specifically in the Archipelago infrastructure. We have carefully decommissioned other hosts previously associated with the extensive AMP mesh. To date, CAIDA has directly decommissioned over 100 hosts, and continues to work with sites on another 36 that are not reachable and/or we plan to physically remove from service.
Major Milestones
- July 24, 2006, CAIDA ceased data collection at the PMA sites.
- On approximately August 31, 2006, CAIDA ceased data collection on most of the AMP mesh. (It took several days to track down and disable all of the boxes).
- The PRAGMA project made use of a subset of nodes we left operational for a demonstration presented in October 2006.
Further Requests for Information
CAIDA will happily provide more specific details regarding the status of any of the NLANR sites and data. If sites have questions or comments on these changes, or input regarding future measurement experiments, please send the queries to nlanr-info at caida dot org.
Tools
CAIDA's mission includes providing access to tools for Internet data collection, analysis and visualization to facilitate network measurement and management.
2006 Tool Development
CoralReef
The CoralReef Software suite, developed by CAIDA, provides a comprehensive software solution for data collect and analysis from passive Internet traffic monitors, in real time or from trace files. Real-time monitoring support includes system network interfaces (via libpcap), FreeBSD drivers for a number network capture cards, including the popular Endace DAG (OC3 and OC12, POS and ATM) cards. The package also includes programming APIs for C and perl, and applications for capture, analysis, and web report generation. This package is maintained by CAIDA developers with the support and collaboration of the Internet measurement community.
In 2006, CAIDA continued to develop CoralReef Software adding capabilities to collect realtime flow data on high speed (OC48, OC192/10GigE) links. New routines allow the software to adapt the sampling rate to the traffic mix thus providing provably accurate sampled flows while staying within fixed memory and reporting budget for all possible traffic mixes. Our approach is described in papers "Building a Better NetFlow" and "A Robust System for Accurate Real-time Summaries of Internet Traffic".
We also updated and improved a realtime traffic report generator that allows dynamic selection of displayed reports. We expect to release CoralReef version 3.8 in summer 2007.
Cuttlefish
Cuttlefish produces animated GIFs that reveal the interplay between the diurnal and geographical patterns of displayed data. By showing how the Sun's shadow covers the world map, cuttlefish yields a direct feeling for the time of day at a given geographic region, while moving graphs illustrate the relationship between local time and the visualized events. We released Cuttlefish early in 2006.
CAIDA acknowledges WIDE for their generous support of cuttlefish development.
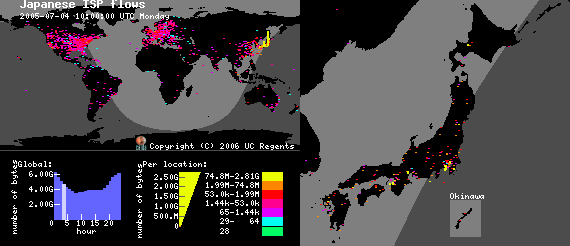
This visualization depicts the traffic volume to and from residential broadband customers of a major Japanese ISP between 7:00 am May 4th and 7:00 am May 5th 2005 UTC. Please refer to the Cuttlefish home page for more information about this visualization. (Click the image for a larger version.) See the Cuttlefish home page for more information, Cuttlefish examples or to download the software.
CAIDA Tools Download Report
The table below displays all the CAIDA developed tools distributed via our home page at https://catalog.caida.org/software and the number of downloads during 2006.
-
Currently Supported Tools
Tool Description Downloads coralreef A software suite to collect and analyze data from passive Internet traffic monitors. 813 dsc A system for collecting and exploring statistics from DNS servers. 127 dnsstat An application that collects DNS queries on UDP port 53 to report statistics. 313 dnstop is a libpcap application that displays tables of DNS traffic. 3141 sk_analysis_dump A tool for analysis of traceroute-like topology data. 224 walrus A tool for interactively visualizing large directed graphs in 3D space. 4288 libsea A file format and a Java library for representing large directed graphs. 493 Chart::Graph A Perl module that provides a programmatic interface to several popular graphing packages. Note: Chart::Graph is also available on CPAN.org. The numbers here reflect only downloads directly from caida.org, as download statistics from CPAN are not available. 359 plot-latlong A tool for plotting points on geographic maps. 213 -
Past Tools (Unsupported)
Tool Description Downloads Mapnet A tool for visualizing the infrastructure of multiple backbone providers simultaneously. 19895 GeoPlot A light-weight java applet creates a geographical image of a data set. 740 GTrace A graphical front-end to traceroute. 1543 otter A tool used for visualizing arbitrary network data that can be expressed as a set of nodes, links or paths. 1997 plotpaths An application that displays forward and reverse network path data. 177 plankton A tool for visualizing NLANR's Web Cache Hierarchy 107
Data
Data Collected in 2006
In 2006, CAIDA continued its data collection activities, adding over 20 terabytes of new data and bringing the total holdings to over 56 terabytes (uncompressed) of data.
Data Type File count First date Last date Total size (compressed) Total size (uncompressed) Macroscopic Topology Measurements 9181 2006-01-01 2007-01-01 N/A 629 GB Network Telescope 8545 2006-01-01 2007-01-01 6.5 TB 19.4 TB
Data Distributed in 2006
We process the raw data into specialized datasets to increase its utility to researchers and to satisfy security and privacy concerns. In 2006, we released the following datasets:
- Witty Worm Dataset (January 11, 2006)
- Code-Red Worms Dataset (February 1, 2006)
- Backscatter-2004-2005 Dataset (February 15, 2006)
- Backscatter-2006 Dataset (April 7, 2006)
- AS Taxonomy Repository (April 14, 2006)
- the DNS Root Server/gTLD RTT Dataset (August 3, 2006)
While some of the resulting datasets are available to anyone without restriction, the access to others is restricted to academic, government, and non-profit researchers and CAIDA members. We ask for-profit companies to sponsor CAIDA in order to gain access to these restricted datasets. All data access is subject to Acceptable Use Policies (AUP) designed to protect the privacy of monitored communications, ensure security of network infrastructure, and comply with the terms of our agreements with data providers.
-
Publicly Available Data
These datasets require that users agree to an Acceptable Use Policy, but are otherwise freely available.
Data Set Unique visitors Number of Visits Data Downloaded AS Rank 5,933 13,431 9.8 GB AS Adjacencies 2,323 9,209 5.3 GB AS Relationships 1,294 3,505 5.8 GB Router Adjacencies 357 392 955 MB Witty Worm Dataset 256 435 323 MB Code-Red Worms Dataset 222 350 4.6 GB AS Taxonomy** 134 135 63 MB ** AS Taxonomy dataset is included in a mirror of the GA Tech main AS Taxonomy site, and thus does not represent all access to this data.
-
Restricted Access Data
These datasets require that users:
- be academic or government researchers, or join CAIDA
- request an account and provide a brief description of their intended use of the data
- agree to an Acceptable Use Policy
Data Set Unique visitors Number of Visits Data Downloaded Raw Topology Traces 249 2879 7.4 TB Anonymized OC48 Peering Link Traces 198 636 2.2 TB 2003 Internet Topology Data Kit 107 242 39 GB Backscatter Datasets* 77 407 1 TB Witty Worm Dataset 65 148 165 GB DNS Root/gTLD server RTT Dataset 9 18 25.4 MB * The Backscatter-2004-2005 and Backscatter-2006 datasets were released in 2006.
-
Restricted Access Data
This data was collected by the NLANR project. When this project came to an end in July 2006, CAIDA inventoried NLANR equipment and took over curation and distribution of NLANR data. CAIDA now maintains both the NLANR AMP and PMA public data repositories.
Data Set Unique visitors Number of Visits Data Downloaded NLANR PMA Data 973 3,119 8.3 TB NLANR AMP Data 298 2,422 10.68 GB
-
Total Data Distributed in 2006
Unique visitors Number of Visits Data Downloaded All Data Distributed 4,907 35,678 72.1 TB
Workshops
As part of our mission to investigate both practical and theoretical aspects of the Internet, CAIDA staff actively attend, contribute to, and host workshops relevant to research and better understanding of Internet infrastructure, trends, topology, routing, and security.
CAIDA Workshops
In 2006, CAIDA hosted the following workshops:- CAIDA-WIDE Workshops
- The 6th CAIDA/WIDE Workshop was held on March 17-18, 2006 in Marina del Rey, CA and the 7th CAIDA/WIDE Workshop was held on November 3 - 4, 2006 in San Diego Supercomputer Center, La Jolla, CA. These biannual invitation-only workshops traditionally cover IPv6/IPv4 topology studies and DNS, as well as miscellaneous research and technical topics of mutual interest for CAIDA and WIDE participants.
- ISMA Workshop on the Internet Topology (WIT)
- On May 10-12, 2006, CAIDA hosted the first ISMA Workshop on the Internet Topology (WIT) supported by NSF, CAIDA and SDSC. The attendance at the workshop was by invitation only. The workshop produced a final report that appeared in ACM SIGCOMM Computer Communication Review (CCR), v.37, n.1, pp. 69-73, 2007.
- 2nd DNS-OARC Workshop
- CAIDA and ISC organized and Microsoft hosted the 2nd DNS-OARC Workshop on November 16-17, 2006 in Redmond, WA. The focus of this workshop included DNS-related Internet measurements and research, operational co-ordination and trusted communication between root, TLD and other DNS and Internet operators, and the future evolution and governance of OARC. Participation was open to OARC members and by invitation to other parties interested in DNS research and operations.
- 1st COMMONS Workshop
- The 1st COMMONS workshop (by invitation only) was held on December 12-13, 2006 at the San Diego Supercomputer Center in La Jolla, CA. This Workshop brought together representatives from industry, community and municipal networks, regional and state networks, as well as Internet researchers, community organizers, and developers building next-generation data communications technologies. Workshop participants also included heads of research, infrastructure, media, and policy organizations, as well as telecommunications lawyers. This unique event produced the COMMONS Workshop Final Report.
Attended meetings
In 2006 CAIDA staff attended the following workshops and conferences and made presentations there:
- ACM SIGCOMM Special Interest Group on Data Communications
- The OECD ICCP Workshop "The Future of the Internet"
- The 3rd Annual Workshop on Flow Analysis (FloCon 2006)
- Internet Engineering Task Force (67th IETF) and corresponding meeting of the Internet Engineering Planning Group
- The Intimate 2006 Network Anomaly Diagnosis Workshop
- The North American Network Operators' Group (NANOG36)
- The Alternative Telecommunications Policy Forum
- Unofficial DNS Root Server System Advisory Committee Site (RSSAC)
- Passive and Active Measurement (PAM) Workshop
- The Quilt 2006 Workshop, Muni Wireless Conference
- Digital Inclusion Day
- 5th System Administration and Network Engineering Conference (SANE)
Publications
The following table contains the papers published by CAIDA for the calendar year of 2006. Please refer to Papers by CAIDA on our web site for a comprehensive listing of publications.
| Year | Author(s) | Title | Publication | Unique Hits |
|
2006
|
Huffaker, B. Friedman, T. claffy, k. |
Approche Récursive d'Etiquetage des Chemins Alternatifs au Niveau IP | Colloque Francophone d'Ingénierie des Protocoles (CFIP) |
0
|
|
2006
|
Huffaker, B. Friedman, T. claffy, k. |
Evaluation of a Large-Scale Topology Discovery Algorithm | IEEE International Workshop on IP Operations & Management |
0
|
|
2006
|
Krioukov, D. Fall, K. Vahdat, A. |
Systematic Topology Analysis and Generation Using Degree Correlations | SIGCOMM |
825
|
|
2006
|
Shang, H. Fomenkov, M. Hyun, Y. claffy, k. |
The Windows of Private DNS Updates | ACM SIGCOMM Computer Communications Review (CCR) |
1379
|
|
2006
|
Shannon, C. Brown, D. Voelker, G. Savage, S. |
Inferring Internet Denial-of-Service Activity | ACM Transactions on Computer Systems |
2432
|
|
2006
|
Riley, G. |
Modeling Autonomous System Relationships | Principles of Advanced and Distributed Simulation (PADS) |
667
|
|
2006
|
Crovella, M. Friedman, T. Shannon, C. Spring, N. |
Community-Oriented Network Measurement Infrastructure (CONMI) Workshop Report | ACM SIGCOMM Computer Communications Review (CCR) |
1365
|
|
2006
|
Huffaker, B. Friedman, T. claffy, k. |
Implementation and Deployment of a Distributed Network Topology Discovery Algorithm | arXiv cs.NI/62 |
0
|
|
2006
|
Krioukov, D. Riley, G. claffy, k. |
Revealing the Autonomous System Taxonomy: The Machine Learning Approach | Passive and Active Network Measurement Workshop (PAM) |
1504
|
|
2006
|
Krioukov, D. Fomenkov, M. Huffaker, B. Dimitropoulos, X. claffy, k. Vahdat, A. |
The Internet AS-Level Topology: Three Data Sources and One Definitive Metric | ACM SIGCOMM Computer Communications Review (CCR) |
2693
|
Presentations
The following table contains the presentations and invited talks published by CAIDA for the calendar year of 2006. Please refer to Presentations by CAIDA on our web site for a comprehensive listing.
Web Site Usage
In 2006, CAIDA's web site continued to attract considerable attention from a broad, international audience. Visitors seem to have particular interest in CAIDA's tools and analysis.
The table below presents the monthly history of traffic to www.caida.org for 2006.
| Month | Unique visitors | Number of visits | Pages | Hits | Bandwidth |
|---|---|---|---|---|---|
| Jan 2006 | 123,644 | 274,068 | 1,312,791 | 3,254,556 | 92.29 GB |
| Feb 2006 | 123,912 | 330,929 | 1,443,084 | 3,807,364 | 120.28 GB |
| Mar 2006 | 109,712 | 421,473 | 2,039,879 | 3,914,781 | 128.43 GB |
| Apr 2006 | 97,168 | 241,669 | 1,171,131 | 2,712,955 | 138.25 GB |
| May 2006 | 82,183 | 236,902 | 1,158,110 | 2,698,210 | 114.66 GB |
| Jun 2006 | 114,924 | 218,982 | 954,935 | 3,429,410 | 97.45 GB |
| Jul 2006 | 70,616 | 164,026 | 789,864 | 2,105,385 | 80.12 GB |
| Aug 2006 | 72,364 | 140,401 | 548,868 | 1,799,446 | 73.74 GB |
| Sep 2006 | 76,076 | 173,234 | 557,594 | 1,849,575 | 69.04 GB |
| Oct 2006 | 119,373 | 184,137 | 575,048 | 2,843,483 | 149.63 GB |
| Nov 2006 | 71,563 | 172,279 | 516,079 | 1,892,643 | 71.29 GB |
| Dec 2006 | 64,831 | 176,216 | 758,431 | 2,010,967 | 69.00 GB |
| Total | 1,126,366 | 2,734,316 | 11,825,814 | 32,318,775 | 1,204.13 GB |
Organizational Chart
CAIDA would like to acknowledge the many people who put forth great effort towards making CAIDA a success in 2006. The image below shows the functional organization of CAIDA. Please check the home page For more complete information about CAIDA staff.
![[Image of CAIDA Functional Organization Chart]](./images/caida_organization_2006.png)
CAIDA Functional Organization Chart
Funding Sources
CAIDA thanks our 2006 sponsors, members, and collaborators.
The charts below depict funds received by CAIDA during the 2006 calendar year.
| Funding Source | Allocations | Percentage of Total |
|---|---|---|
| GIFT | $200,000 | 11.9% |
| ARIN | $100,000 | 6.0% |
| DHS PREDICT | $348,926 | 20.8% |
| NSF DNS | $11,000 | 0.7% |
| NSF Trends | $343,440 | 20.4% |
| UCSD/SDSC | $80,356 | 4.8% |
| NSF Infrastructure | $583,900 | 34.8% |
| NSF NeTS | $12,000 | 0.7% |
| Total | $1,679,622 | 100.0% |
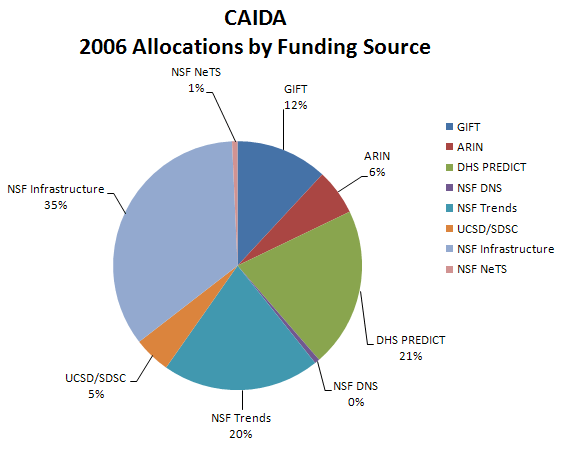
Figure 1. Allocations by funding source received during 2006.
| Program Area | Allocations | Percentage of Total |
|---|---|---|
| Data Sharing | $692,366 | 37.6% |
| DNS | $11,000 | 0.6% |
| Infrastructure | $723,256 | 39.2% |
| Outreach | $2,500 | 0.1% |
| Policy | $100,000 | 5.4% |
| Routing | $12,000 | 0.7% |
| Security | $102,534 | 5.6% |
| Sponsors | $200,000 | 10.8% |
| Total | $1,843,656 | 100.0% |
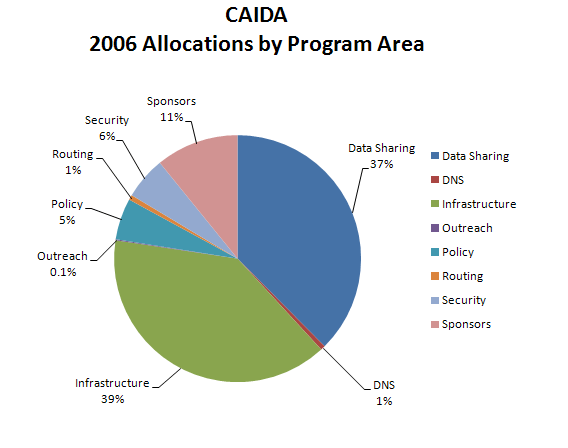
Figure 2. Allocations by program area received during 2006.
Operating Expenses
The charts below depict CAIDA's Annual Expense Report for the 2006 calendar year.
| LABOR | Salaries and benefits paid to staff and students | ||
| IDC | Indirect Costs paid to the University of California, San Diego including grant overhead (52-54%) and telephone, Internet, and other IT services. | ||
| SUBCONTRACTS | Subcontracts to the Internet Systems Consortium (ISC) and Georgia Institute of Technology | ||
| SUPPLIES & EXPENSES | All office supplies and equipment (including computer hardware and software) costing less than $5000. | ||
| TRAVEL | Trips to conferences, PI meetings, operational meetings, and sites of remote monitor deployment. | ||
| EQUIPMENT | Computer hardware or other equipment costing more than $5000. | ||
| TRANSFERS | Exchange of funds between groups for recharge for IT desktop support and Oracle database services. |
| Program Area | Expenses | Percentage of Total |
|---|---|---|
| Labor | $1,434,383 | 59.4% |
| IDC | $624,789 | 25.9% |
| Subcontract | $29,781 | 1.2% |
| Supplies & Expenses | $106,829 | 4.4% |
| Travel | $76,640 | 3.2% |
| Equipment | $131,499 | 5.4% |
| Transfers | $9,193 | 0.4% |
| Total | $2,413,114 | 100.0% |
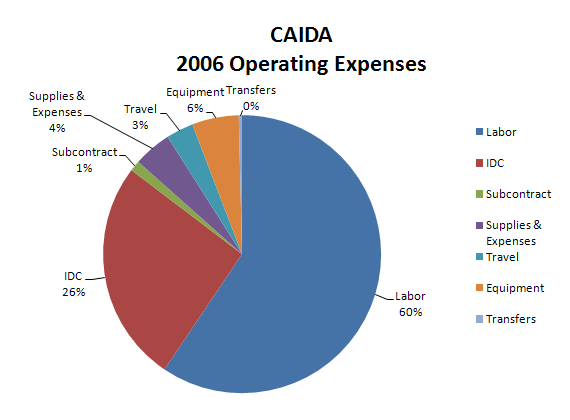
Figure 3. 2006 Operating Expenses
These numbers do not include salaries or expenses paid by the Computer Science & Engineering Department of the Jacobs School of Engineering at the University of California, San Diego.
| Program Area | Expenses | Percentage of Total |
|---|---|---|
| Data Sharing | $770,571 | 31.9% |
| DNS | $495,780 | 20.5% |
| Infrastructure | $155,134 | 6.4% |
| Outreach | $34,526 | 1.4% |
| Policy | $192,934 | 8.0% |
| Routing | $473,310 | 19.6% |
| Security | $247,919 | 10.3% |
| Topology | $42,940 | 1.8% |
| Total | $2,413,114 | 100.0% |
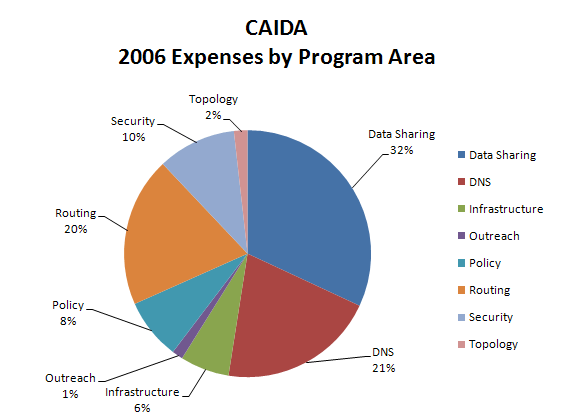
Figure 4. 2006 Expenses by Program Area
| Funding Source | Expenses | Percentage of Total |
|---|---|---|
| NSF-Trends | $526,142 | 21.8% |
| NSF-Nets | $481,002 | 19.9% |
| NSF-DNS | $378,415 | 15.7% |
| NSF-Trusted Computing | $82,385 | 3.4% |
| NSF-CRI | $15,778 | 0.7% |
| NSF-Other | $244,390 | 10.1% |
| Gift | $350,895 | 14.5% |
| DHS | $245,533 | 10.2% |
| UCSD/CNS | $88,574 | 3.7% |
| Total | $2,413,114 | 100.0% |
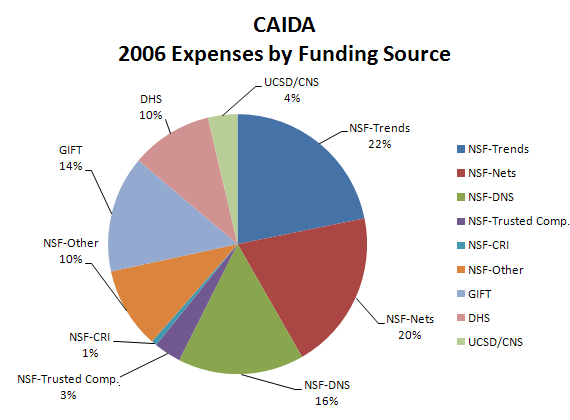
Figure 5. 2006 Expenses by Funding Source