

Curated AI-ready Network telescope datasets for Internet Security (CANIS)
CANIS is a suite of modules to transform the applicability of UCSD-NT in AI contexts.
Principal Investigators: Ka Pui Mok Kimberly Claffy
Funding source: OAC-2531134 Period of performance: October 1, 2025 - September 30, 2028.
Project Summary
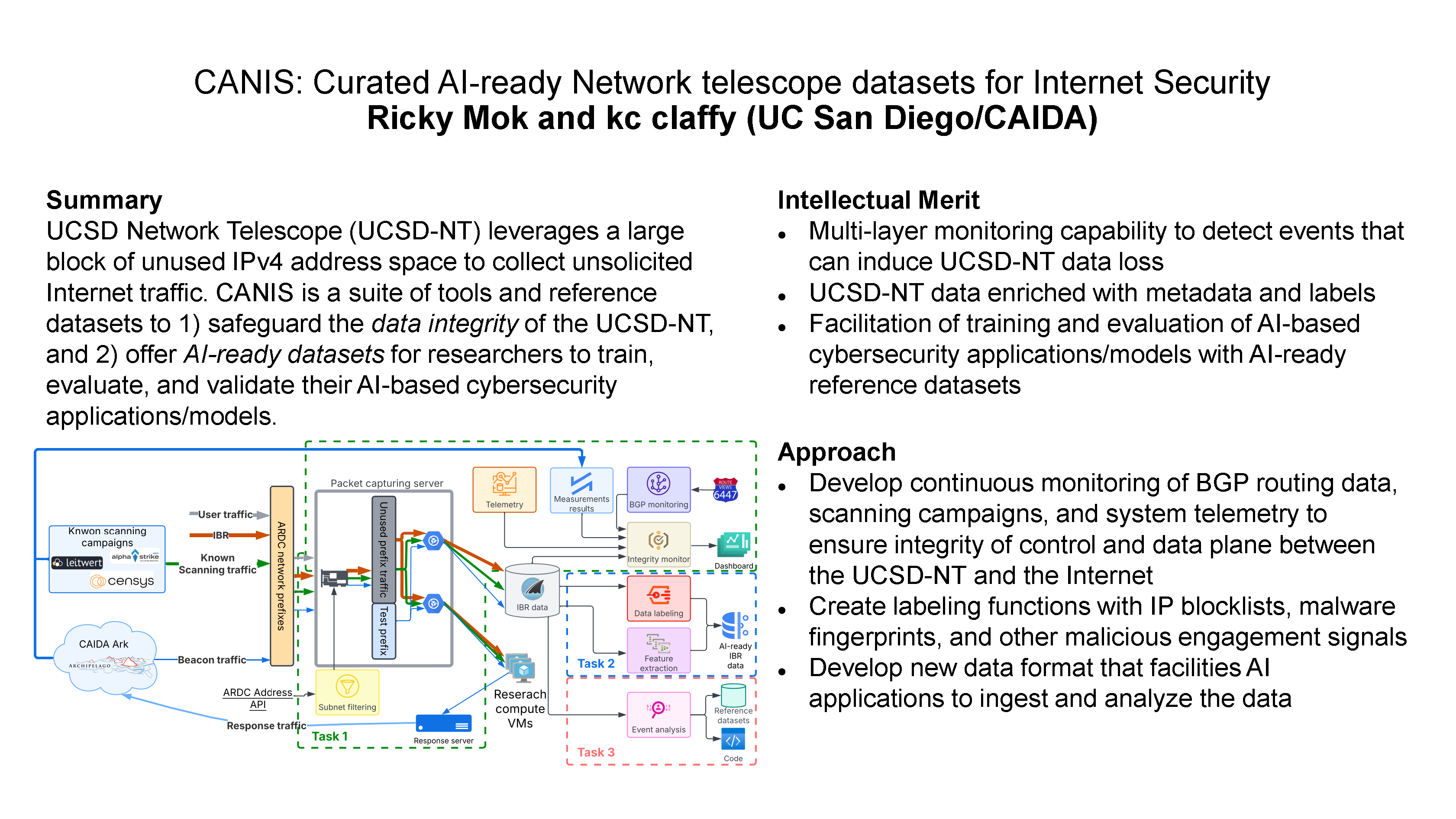
The UCSD network telescope (UCSD-NT) has been a long-standing NSF-funded scientific cyberinfrastructure (CI), supporting the collection of unsolicited Internet (IPv4) traffic (Internet background radiation or IBR). Researchers use IBR data to detect a variety of malicious activities. But applying AI to UCSD-NT data is a double-edged sword. Advanced ML/AI models excel at identifying threats in IBR, but their success hinges on the integrity, provenance, and authenticity of the underlying data. Emerging risks to the integrity of the UCSD-NTdata have coincided with exploding use of AI tools in cybersecurity research, creating an urgent challenge. This project directly tackles this challenge, with the ultimate goal of delivering high-quality, large-scale labeled datasets to safely train, validate, and benchmark AI models. But it requires infrastructure innovation.
The UCSD-NT faces mounting operational hurdles as usage of the underlying address space grows in magnitude and scope. The data’s integrity also faces two external risks. First, IBR traffic growth increasingly strains UCSD-NT’s packet-capture capacity, leading to data loss. Second, Internet routing disruptions, like misconfigurations and hijacks, impair connectivity to the UCSD-NT monitored address space, undermining the completeness of the data. Without constant monitoring, UCSD-NTis at risk of capturing legitimate (non-IBR) traffic and/or of reduced visibility. Increasing use of AI tools and models that rely on this data amplifies the urgency of re-architecting its collection and curation infrastructure. Conventional cybersecurity datasets are used to train models to isolate rare malicious traffic from mostly legitimate flows, a process ill-suited for IBR’s unique anomaly detection needs. The scarcity of large-scale, labeled IBR reference datasets stifles accurate AI model training and evaluation. UCSD-NTgenerates the largest such data set in the world, and as its use with AI tools expands to those with less expertise in the underlying network traffic characteristics, the integrity challenges become crucial to overcome.
To tackle these challenges, we propose CANIS, a suite of modules to transform the applicability of UCSD-NT in AI contexts through three complementary tasks. First, we will develop and deploy a new monitoring framework to safeguard cybersecurity research workflows. We will leverage CAIDA’s active measurement infrastructure and public BGP data to monitor its connectivity, and use IBR generated by known scanning campaigns to continuously verify the data integrity of UCSD-NT. We will develop a new data format to disseminate information on status of the platform, lowering the risk of research use of inaccurate data in AI applications. Second, we’ll enhance metadata by tagging IPs on blocklists or associated with network abuse or malware probes. We will also log system and network data, letting researchers trace whether their findings rest on flawed inputs. Third, we’ll curate a library of curated, labeled reference datasets-snapshots of real-world events like malware outbreaks and scans-paired with AI-generated analyses, empowering researchers to efficiently benchmark and validate models.
Broader Impacts
This project will yield curated datasets that facilitate anomaly detection, threat intelligence, and attack mitigation, ultimately strengthening global cybersecurity and workforce training efforts. Moreover, by bridging AI infrastructure and cybersecurity, CANIS sets a precedent for data-intensive fields, aligning research pipelines with transparency and accountability in AI innovation.
Project Tasks
| Pillar | Task # | Task Title | Target Date | Subtasks |
|---|---|---|---|---|
| T1: Data Integrity | 1.1 | Migrate PCAP generation to bare-metal containerized architecture using Open vSwitch and DPDK | Jun 2026 | (1) Configure Open vSwitch with DPDK on bare-metal server to poll packets from SmartNIC and mirror to Docker containers (2) Build traffic collection container with PF_RING for kernel bypass capture and direct storage to CAIDA cluster (3) Build traffic streaming container to encapsulate and multicast packets to VM network for live IBR distribution (4) Run parallel validation comparing containerized system against legacy VM system during traffic surges (5) Transition production capture to new architecture and decommission legacy VM system |
| 1.2 | Deploy full-stack telemetry monitoring with explicit I/O and memory tracking | Aug 2026 | (1) Deploy and configure Telegraf agents to collect packet statistics from SmartNIC, Open vSwitch, container interfaces, and system metrics (CPU, disk I/O, memory) (2) Set up InfluxDB instance to store telemetry data (3) Create monitoring dashboards with packet loss and traffic visualizations and configure alerts for drops and bottlenecks |
|
| 1.3 | Develop data format to disseminate platform status information to researchers | Aug 2026 | (1) Design data format and implement pipeline to aggregate platform status from telemetry, BGP monitors, and filter synchronization | |
| 1.4 | Implement platform status system | Oct 2026 | (1) Develop dissemination mechanism with automated updates, catalog integration, and researcher documentation | |
| 1.5 | Deploy active measurement response framework with dedicated /24 subnet | Sep 2026 | (1) Allocate dedicated /24 subnet (2) Deploy response server for traceroute probes and isolate response traffic from IBR collection (3) Implement traceroute measurements from CAIDA Ark VPs and configure packet loss monitoring |
|
| 1.6 | Implement passive scanner validation using known scanning campaigns | Sep 2026 | (1) Cross-validate scanning results from Alpha Strike, Leitwert, and Censys against UCSD-NT baseline (2) Develop software to analyze UCSD-NT data daily with spatial and temporal validation and anomaly alerting |
|
| 1.7 | Monitor BGP control plane and detect prefix hijacks using RouteViews data | Dec 2026 | (1) Integrate RouteViews BGP streams to monitor AMPRNet prefix visibility (2) Validate announced prefixes against AMPRNet allocation API (3) Deploy hijack detection with alerting for unauthorized announcements and routing anomalies |
|
| T2: AI-Ready Pipelines | 2.1 | Migrate IBR data from FlowTuple to Apache Parquet format | Dec 2026 | (1) Design Parquet schema and conversion pipeline from FlowTuple with one-minute resolution (2) Validate Python, R, and Spark compatibility and benchmark performance against legacy format (3) Deploy production pipeline and publish researcher documentation |
| 2.2 | Identify scanner IP ranges using LLMs | Jun 2027 | (1) Develop LLM prompts to identify IP ranges and ASNs for known and undocumented research scanners (2) Implement human-in-the-loop validation and curate verified scanner IP and ASN lists for Label Mapping Files |
|
| 2.3 | Generate Label Mapping and Traffic Statistics Files with automated metadata tagging | Nov 2027 | (1) Integrate blocklists (FireHOL, AbuseIPDB) and cloud provider IP ranges for automated hourly tagging (2) Implement malware fingerprinting and scanner detection engines (3) Generate hourly Label Mapping Files in Parquet linking IPs to tags (4) Generate five-minute Traffic Statistics Files in Parquet with packet and destination counts indexed by source IP and destination port |
|
| T3: Reference Datasets | 3.1 | Curate reference event datasets and pair with AI-generated analyses | Jan 2028 | (1) Define event criteria and identify representative security events (malware outbreaks, scans, DDoS) (2) Extract curated IBR snapshots with PCAP and flow data (3) Document datasets and publish through CAIDA catalog with metadata and access controls |
| 3.2 | Re-implement published algorithms for HPC benchmarking on SDSC Expanse | Aug 2026 | (1) Select representative algorithm classes (statistical, graphical, Word2Vec, time-series, deep learning) (2) Re-implement for HPC efficiency on SDSC Expanse (3) Benchmark runtime, CPU, memory, and scalability metrics (4) Publish HPC-compatible code with execution instructions |
|
| 3.3 | Develop reproducible downsampling toolkit | Sep 2026 | (1) Design bias-aware downsampling methodology to preserve statistical properties (2) Validate distributions against full UCSD-NT dataset (3) Publish scripts and best practices for reproducible dataset generation |
Acknowledgment of awarding agency’s support
This material is based on research sponsored by the National Science Foundation (NSF) grant OAC-2531134. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of NSF.
Additional Content
Curated AI-ready Network telescope datasets for Internet Security (CANIS)
Proposal for CICI: Curated AI-ready Network telescope datasets for Internet Security (CANIS)