

Configuration Challenges in a Global Cache Hierarchy
Evolution of the NLANR Cache Hierarchy:
Global Configuration Challenges
UC, San Diego
abstractWorld-Wide Web caches are designed to alleviate some of the problems imposed by ever-increasing Internet traffic growth. Caching is noticeably different from mirroring or replicating; It is mostly transparent to end users, and because caches are client-driven, they automatically adjust to accommodate popular objects based on user access patterns.
The National Science Foundation has provided funding to develop a prototype hierarchy of World-Wide Web caches, which have been in operation since December 1995. This paper describes our initial experiences and observations while operating the caches. In particular we focus on the administrative requirements for configuring and tuning a cache for its best performance in the global hierarchy.
Keywords: tradeoffs, caching, www.nlanr.net/Cache/
Background
The Internet's sustained explosive growth calls for an architected solution to the problem of scalable wide area information dissemination. While increasing network bandwidths help, the rapidly growing populace will continue to outstrip network and server capacity as they attempt to access widely popular pools of data throughout the network. The need for more efficient bandwidth and server utilization transcends any single protocol such as ftp, http, or whatever next becomes popular.
Fundamentally, the Web operates as a standard client-server system. A clients makes a network connection to a server and issues a request for a world wide web (WWW) object referenced by a Uniform Resource Locators (URL). A URL refers to a location, incorporating an Internet host name and filename on that host. Thus, to a first approximation, there is only a single source for a WWW object.
Extending this model to traditional print media suggests the equivalent of each reader having to deal directly with the publisher of each book, magazine, or newspaper he wanted to read. Obviously suboptimal for both the information consumer and provider, such a technique would also impose extraordinary burdens on other components of the system, e.g., the transportation or postal service used to get each piece of information to the consumer.
On the Internet, information moves and changes a lot faster than in traditional print media, but the architecture outlined above is no less relevant. Indeed, `middle men' provide an even greater payoff, to a potentially larger number of people, for electronic information. An even more appropriate metaphor for a cache than a bookstore, where each reader buys his own copy of the document, might be a library, where numerous individuals can read the same document, albeit one at a time. Also similar to the web, by allowing books to be `cached' in a library, a publisher forgoes not only ostensible potential revenue, but also access statistics., i.e., how many people are reading the library copy.
We imagine that within a few years a practical web caching system will be able to support both the bookstore and library models.
NLANR cache architecture
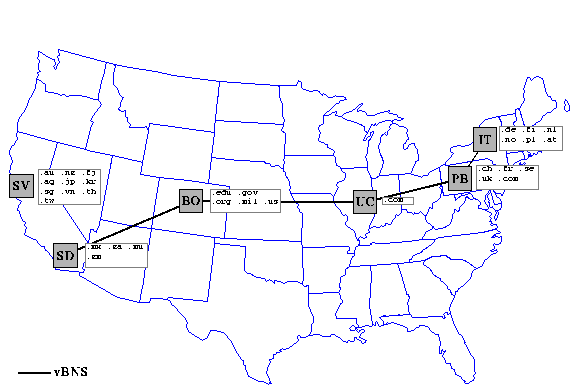
The National Science Foundation is sponsoring NLANR, the National Laboratory for Applied Network Research, to develop and deploy a prototype of a global web caching hierarchy. With root caches located at each node of the NSF's high speed backbone service, the vBNS, the NLANR web caching hierarchy has experienced a steady increase in usage since its inception in December 1995. We currently receive requests from over 100 cache clients in dozens of countries and serve between 15-20 Gbytes per day.
Our caches run on DEC Alphaserver 1000 systems at each of the five NSF-sponsored supercomputer center sites, and at a NASA-sponsored exchange point on the west coast. We note that these sites are not topologically optimal locations for our intended root caches, which would be more strategically placed at large interconnect points or at borders of large backbone networks. However, the SCC locations do have the advantage of the high speed vBNS network that connects them, through which the root caches can communicate with each other.
As the cache relays objects between clients and servers, it monitors the data streams in each direction and decides which objects it should retain a copy of based on expected future popularity. The cache saves these documents `worth holding' indexed by the URL, so that it can satisfy future requests from clients without needing to connect again to the origin server.
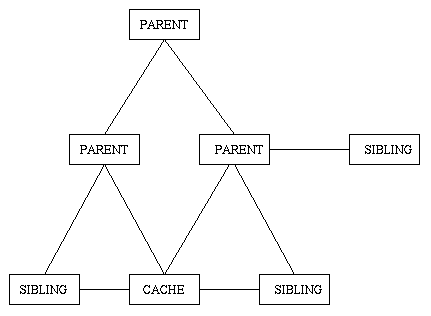
The figure above shows a hierarchical configuration of caches. A cache may make use of neighbor caches. A neighbor is either a parent or a sibling. A cache will send ICP (Internet Cache Protocol) queries to its neighbors and collect the replies. Each reply should be either a hit indicating the neighbor already has the requested object, or a miss indicating it does not. When the cache knows which of its neighbors (if any) have the requested object, it will select a neighbor from which to retrieve it. A cache can retrieve hits from either a parent or sibling cache, but can resolve misses only through parent caches. A cache will fetch an object from the origin server if it has no parents, if the neighbor caches do not respond quickly enough, or if it has reason to believe that none of the neighbors will have it.
Our software has configuration options to restrict the use of neighbor caches for a certain class of objects. It is most common to restrict queries from a neighbor cache to URLs belonging to a set of domain names. For example, one cache may handle all requests of URLs in the .com domain, while another handles URLs in the .edu domain.
Administering a distributed worldwide caching hierarchy involves a number of challenges, mostly related to the substantial manual configuration still required for construction and maintenance of the hierarchy. As we gain more experience with the caching system we expect to learn which parameters the system can modulate based on its own experience, and how it should keep track of that experience so that it can make productive decisions. Nonetheless, for a variety of reasons, the foreseeable future will involve the continued need for careful configuration of caches to optimize system performance.
In the remainder of this paper we focus on the administrative requirements for configuring web caches for effective system performance. We will discuss the major parameters of the system that require specific configuration or coordination with other sites, and our experience with them in the NLANR hierarchy.
General Cache Administration
Administering a single cache
In terms of system administration, WWW caches and http servers are similar. The cache can generate huge log files, which the administrator needs to regularly examine for possible configuration errors. As with almost any other application, the administrator should monitor its performance and consumption of system resources (such as memory and disk space). We currently spend extensive effort managing our logfile data, typically around 100MB per day per cache, which prohibits copying them to a single host for centralized processing. Instead we distill the logs to a more manageable subset of useful data (approximately 100KB worth) on each cache machine; thus each cache host must have identical copies of the processing software, identical directory layout, etc. We then use a trusted machine to automatically pull the summary files nightly from the root caches. Secure transfer of data between machines requires additional administration effort.
The cache software is still evolving rapidly. In our case, we release new versions for testing at least once per week. Administrators trying to keep up with the latest features may spend a lot of time installing new software and checking for bugs.
In some situations, getting web users to utilize a cache or proxy involves a bit of marketing. The only real incentive for an individual to use a cache proxy is the potential for faster retrieval time while browsing. Administrators or operators may have other motivations for supporting caches, such as reducing bandwidth on their connection to the rest of the Internet. The presence of firewalls also can make using a cache proxy desirable if not necessary. In many cases where bandwidth is scarce, network administrators may block direct access to the default http port, thereby forcing people to use the cache. In any case, cache administrators will likely have to educate users on the tradeoffs of using a cache before getting substantial proactive cooperation.
Administering a group of caches
An organization may need to operate a group of internal caches, which will also likely require some central administration. For example, for our seven-cache root system, we use one machine to do software builds and version testing, from there distributing it to the others. Geographically distributed cache machines will also require some support from on-site staff to reboot the machines, upgrade hardware, etc.
In addition, logfile analysis across multiple caches requires centralized and automated collection. If for some reason data for any cache fails to arrive, the administrator must manually determine what went wrong, fix it, and repeat the analysis of the complete data set.
Cache administrators may be interested in network connectivity among all caches in the group. For example, a group of caches might share a certain configuration based on the under or overutilization of a given link. Changes in the underlying network and/or workload characteristics that inspired the parameter setting will affect cache behavior as well, so administrators must regularly monitor such characteristics.
Administering a cache hierarchy
Joining a caching hierarchy offers many advantages, all related to the ability of caches to leverage off the work of each other. The strongest disadvantage of participation in a hierarchy is that every cache will be subject to any bugs or misfeatures of the other caches. A bug at one cache in the hierarchy can adversely affect all other caches underneath it.
Multi-platform robustness
A good example of such a bug occurred a few months ago. One Friday afternoon we installed an updated version of the cache software, complete with a serious bug that caused every request requiring a dns lookup to result in an `unknown host' message to the user. All the caches ran with this bug for about a day and a half; we did not even know about the problem until receiving email from a cache administrator in another country. The situation points to another critical aspect of administering the caches: multi-platform performance. We developed and tested the software on one machine, which did not experience the problem. (Without going into detail, the bug occurred only on systems which have 64-bit long integers, whereas most other systems use 32-bits.)
Incompatible version
In a related circumstance, our software module for executing ftp requests did not return the Date header that is standard in http replies. The problem was not exposed until we enhanced the cache to reject from its neighbors any objects that did not include a Date header. Fixing the ftp module was not a problem, but many sites were still running the old version, so sites running the newer version of the software would not cache ftp objects retrieved from neighbors running older versions. We are now stuck with two fielded versions that are incompatible, with little power to coerce sites to upgrade to a current version.
Network failures do not generally affect a cache hierarchy, since the underlying architecture of the software is robust to the unreachability of neighbor caches. Before making a request from any neighbor cache, the software sends that neighbor a small UDP ping packet, and does not request actual documents from the neighbor unless it receives a reply.
Joining a Cache Hierarchy
In order to participate in the cache hierarchy, a new cache administrator must first locate nearby caches as potential neighbors. Putting off for a moment that we need a definition of `nearby', we explain the default procedure for neighbor assignment within the current system.
Today NLANR maintains a cache registration database at http://www.nlanr.net/Cache/Tracker/caches/. While this database provides a lot of useful information, it unfortunately requires manual browsing by cache administrators trying to find other caches running near them. Upon determining the existence of a potential neighbor(s), the administrator will usually use ping and traceroute to determine where the other cache lies in the network topology. Some administrators choose to send into the Tracker registration database additional information such as terms of use, hardware configuration, etc.
Note that asking permission before neighboring with another cache is more than just a matter of courtesy. Significant costs and security concerns have led many caches to use access controls, so using a remote cache will typically require explicit configuration on their end. Extrapolating this policy to an Internet-wide scale implies an ominous administrative task: each new member must procure the explicit configuration of access from every other cache it will use. In the future we are considering adding support for centralized administration of access control list (ACL) groups, so that adding someone to a group in one centralized database location would cause the information to propagate, automatically providing them with the access capabilities of the rest of the group.
Identities and Statistics
Most users do not mind that a proxy hides the identity of the user, but servers often rely on these identities for market analysis purposes. On more than one occasion we have received mail to squid@uc.cache.nlanr.net from companies attempting to send followup messages to the address listed in their http access log file as having downloaded trial software.
Servers also often rely on the identity of an incoming requestor to determine whether he has access to the page requested. Consider a Web server that allowed access to certain data from only educational sites, as indicated by an .edu domain name. A person browsing from a .com site may become frustrated until he realizes that he can send the request through a cache operating within a .edu site. In this case, the cache allows the end user to trick the server into thinking that the request originated at the .edu site. We note that there are already several operating anonymous web proxies, analogous to anonymous remailers for electronic mail. These are only a few factors that negatively affect the utility of log statistics.
Given these ramifications, many content providers (CPs) are completely hostile toward caching activities because they lose their ability to determine exactly who has downloaded material, typically valuable information for marketing and advertising behaviors. We have yet to develop a realistic mechanism for getting access counts back to CPs, and this feature will likely be necessary before most CPs come to embrace caching. We also note that information server operators have goals that compete with their desire for marketing-related information, in particular the need to minimize costs for server hardware and line charges. If caches can meet them at least part of the way in accommodating their advertising and marketing information needs, they are more likely to prefer caching rather than try to actively circumvent it.
The desire of information providers for hit statistics, and maybe other data, does pose a dilemma for cache administrators whose customers may be using the cache precisely because it does provide anonymity. Similar to the motivation for anonymous mailers that originated in Finland, it is ostensibly easier to find one cache operator you trust to keep your log files private than worrying about every site you visit that might be publishing/using log file information. The situation is somewhat similar to POTS services for caller ID and caller ID blocking.
Cache Routing Above IP
One can also utilize proxies to force web requests along specific paths. For example, if the link between the U.S. and U.K. is congested, we can web-route http requests via a faster pipe in Norway. is a legitimate use of the infrastructure is not clear. (Well, it is to us.) One could also use this facility to dedicate a long-haul pipe to only Web caching traffic, analogous to a carpool lane.
We have also encountered problems in trying to route http requests based on the domain of the requested URL as alluded to earlier. Our configurations incorporate the assumption that .com or .org sites were located within the U.S., which is not always the case.
Encouraging a Rational Cache Hierarchy
Initially the top level NLANR caches were openly available for anyone to use, and within 7 months we were receiving requests from approximately 70 different clients and serving between five and six Gbytes per day. It became clear that we needed to encourage a more logical hierarchy in order to keep the system manageable and growth healthy.
Australia is notably suboptimal in terms of hierarchy configuration. There are currently 14 separate Australian sites using the two west coast NLANR caches. The pricing structure for bandwidth within Australia is such that none of these sites is willing to be a parent cache for Australia, and the sites would rather peer directly with the US than with each other. More specifically, the main backbone provider, Telstra, charges the same for traffic regardless of its source or destination. One pays the same to retrieve an object from across Sydney (or Perth in this case), from the U.S., or from Russia. This pricing structure is hostile to cache operators; a large cache could only operate in Australia on the basis of charging extra for a higher-speed service. We hope that Geoff Huston of Telstra will be able to ameliorate this situation by having Telstra operate a parent cache for all their customers.
Initially, a number of the caches were directly utilizing all six NLANR caches, so that every request to the NLANR system would result in sending six ICP query packets, one to each cache. Although this behavior may maximize the client's chance of getting a HIT response quickly, it is not in the best interests of either the user or the system as a whole. What really matters is how long it takes to retrieve the entire document, not just the single packet acknowledging the HIT.
Since the NLANR caches are connected via the vBNS, the very High Speed Backbone Network Service sponsored by the National Science Foundation, they effectively behave as a single distributed cache with six access points. Therefore, even if a document is only in a west coast NLANR cache, a cache client in Europe will get better response time by retrieving it via an east coast NLANR cache, which can leverage the relatively uncongested vBNS rather than having to use the often overloaded commodity Internet.
Disassembly Required
Top down We invested some attention to visualizing the cache hierarchy in order to highlight suboptimal configurations. http://www.nlanr.net/Cache/cacheviz.html has visualizations of the caching hierarchy structure and details on the methodology used. On the same page we also provide daily updates of these views that reflect the current NLANR caching neighbor relationships.
Based on our findings, in early May we encouraged the administrators of NLANR peers to configure their caches to use the system more efficiently. A few voluntarily did so. On July 10 1996, we implemented access controls to force coherence to an architecturally more sound hierarchy. The figures below show the dramatic decrease in the less efficient configurations after that date; the access controls (9 and 10 July 96; the access controls were activated at midnight between the days.) Note that the activating the controls did not affect substantial users of the system, drawn in red. Paths that disappeared were mostly low volume ones, shown in blue.
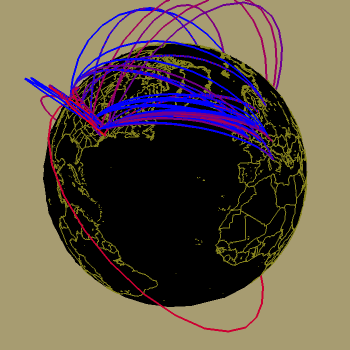
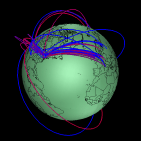
NLANR cache hierarchy before and after access controls.
The color of each tunnel represents the volume of traffic
downloaded from an NLANR parent cache, ranging from
low (blue) to high (red) volume. The color ramp
is scaled non-linearly, to adjust for the fact that
a large proportion of traffic within the caching system
is going between the NLANR root caches themselves.
Bottom Up
In some cases we saw a relative trickle of requests from a number of smaller cache sites in countries that already have larger national caches. We needed to have these low volume clients establish parent relationships with caches already operating in their own country.Guidelines
Specifically, we proposed these administrative guidelines for U.S. root level caches:- NLANR should peer with only one or two large caches in each foreign country.
- We would allow peer and child caches to use two, but no more than three NLANR caches as parents. Because most of the NLANR caches are connected via the vBNS (which currently provides plenty of bandwidth), there is little reason to send ICP queries to all six NLANR caches simply to maximize the chance of getting a HIT.
- We recommend that child and peer caches treat the NLANR cache system as a black box instead of trying to predict where objects are most likely to exist based on our configuration files. Otherwise whenever we had to modify our domain routing configuration rules, the child and peer caches would have configurations that did not make sense.
Recruiting Root Caches
While there are many international caches that tie into the NLANR hierarchy, few of them are root caches. We try to find cache operators who are willing to be the root for external requests of URLs in their country, e.g., our caches send all requests for .uk URLs to wwwcache.doc.ic.ac.uk. Many cache administrators are reluctant to begin the formation of a regional cache hierarchy because they do not want to be at the top, fearing it implies giving free transit resources to other providers in a highly competitive market.
This is an especially acute problem in countries where bandwidth is expensive. ISPs in Asian countries often have abjectly poor domestic connectivity, and in fact in many cases have better connectivity to the U.S. than within their own country. We often find the United States in the position of being a traffic hub, even between countries that are both on the other side of the planet.
Security Issues
We have discussed how the use of caches and proxies alters the apparent identity of web requesters. In fact, forming cache hierarchies merits careful consideration to this issue. The access controls are useful in limiting who may or may not use a cache, but it only takes one "weak link" to break the whole chain. In other words, when a cache trusts a neighbor, it implicitly also trusts that neighbor's neighbors, etc.
Unresolved Issues in WWW Caching
Who is in Control
The use of network caches presents an interesting issue of who can decide how long to cache an object. In other words, who gets control over web objects in caches and clients?
Even ignoring caches for the moment, if a user downloads a web object to his local machine, how long is it `safe' for him to use that object. Once a server emits an object, what sort of control does the server still maintain over it? If the server says that an object expires at time T, what are the implications for using that version after specified time T?
Bringing caches into the equation causes only more confusion. Instead of a simple two party client/server transaction, three or more parties are now involved.
Content providers (CPs) are justified in their need to control object TTLs in order to ensure that viewers always receive valid information. A large class of information, e.g., stock price quotations, is of little, even potentially negative, value unless very fresh. Some CPs will abuse the ability to set specific TTLs to defeat caching. By making objects from their server expire immediately, they can prevent any http-compliant cache from caching them.
Many infrastructures now charge for Internet service on a per-packet or per-byte basis. Users and ISPs in these situations have a very real incentive to cache. When the consumer pays to retrieve some object, what right does the CP have to insist on a certain TTL? If micropayments ever become a reality, the right to set the TTL should ostensibly be an inherent part of paying for downloading the object in the first place. If CPs insisted on zero or very low TTLs they should bear the cost and perhaps to some extent finance infrastructure upgrades of under provisioned ISPs.
Expires: statistics
Some might argue that a strict interpretation of the http specification requires caches to disregard any objects without an explicit Expires header. On the NLANR caches, we have observed that the use of the Expires header is still scant: only 2-6% of objects retrieved have an Expires header. Obviously, if caches did not store the other objects, there would be little point to web caching at all.
The next steps for our caching project include more automatic load balancing and (both configured and dynamic) selection of parents, routing, multicast cache-to-cache communication, and better recognition of URLs that are not worth caching.
copyright
Is it legal to cache copyrighted work? If not, who should be responsible to ensure copyrighted data stays out of a cache?
The Web presents a number of interesting issues for copyrights. The combination of computers and networks renders effortless the duplication of information. Before the invention of photocopiers, the interpretation of copyright law was pretty clear. We seem to have only recently come to an understanding of what is considered fair use in a world of copiers. Networked computer systems bring us again to a frustrating disequilibrium.
While a number of people are vehemently opposed to the notion of storing copyrighted works at numerous locations throughout the Internet, we can think of no good reason that there should be a direct correlation between copyright and cachability.
We note that the intended purpose of the system of copyrights was to encourage innovation and expression and allow copyright holders to be duly compensated for their work. We believe that people who are afraid of caching copyrighted material are actually afraid of caching revenue-generating information. There is certainly a whole class of copyrighted information that is given away for free. We see no reason to prohibit caching of such information.
There is one interesting difference between information dissemination on the web and in more traditional media such as books or film. While consumers always pay for books and movies, information on the Internet is mostly given away freely. Of course some web sites do require subscriptions, but by far the majority are free, many in fact seem to beg for people to visit. We certainly do not expecting this situation to remain true indefinitely, but rather want to point out that traditional ways of thinking about information and consumers may not apply to the Internet.
Right now copyright laws give the author of any document full rights whether the author includes a copyright notice or not. Other guidelines cache administrators might want to use
- don't cache documents with the string "copyright"
- cache documents with recognizable public license (e.g., gnu)
- cache documents with the string ok-to-cache
- cache documents that don't mention copyright
- cache gif and jpg files unless ascii copyright string in comment
Those who insist on uncacheable documents will simply be slower than everyone else on the net, although admittedly they impact the general bandwidth requirements of the net.
. . .In a more perfect world, we'd be wise to declare a moratorium on
litigation, legislation, and international treaties
in this area until we had a clearer sense of the terms
and conditions of enterprise in Cyberspace.
Ideally, laws ratify already developed social consensus. They are less
the Social Contract itself than a series of memoranda expressing a
collective intent derived from millions of human interactions.
. . .Humans have not inhabited Cyberspace long enough or in sufficient
diversity to have developed a Social Contract which conforms to the
strange new conditions of that world. Laws developed prior to
consensus usually serve the already established few who can get them
passed and not society as a whole.
Perhaps those who are part of the problem will simply quarantine
themselves in court while those who are part of the
solution will create a new society based,
at first, on piracy and freebooting. It may well be that
when the current system of intellectual
property law has collapsed, as seems inevitable,
that no new legal structure will arise in its place.
-John Perry Barlow
The riddle is this: if our property can be infinitely reproduced
and instantaneously distributed all
over the planet without cost, without our knowledge,
without its even leaving our possession, how can we protect it?
How are we going to get paid for the work we do with our minds?
And, if we can't get paid, what will assure the continued
creation and distribution of such work?
|
|
future areas to explore
There are several research areas that we hope to use the NLANR system to explore:- animated visualizations of how the architecture has changed over time
- mapping and path characterization of the unicast topology underneath each neighbor path
- analysis of if-modified-since requests (what percent of requests are IMS requests, how many of those receive a not modified, should the cache handle IMS requests directly or to pass them to a parent cache?)
- assess the tradeoffs of push caching
- develop mechanisms for server administrators to obtain statistics on hit counts for cache objects from their server
- develop a better understanding of optimal document expiration values
conclusions
We have described the NLANR caching system architecture and the challenges of administering a caching hierarchy within a globally meshed caching system. We described the analogy of caches to print media, which people get from bookstores rather than directly from the publishers. The caches are configured to distribute the load amongst themselves so that each one handles an appropriate subset of top level domains.The use of web caching software has gained wider acceptance internationally than in the United States, where bandwidth is scarcer and often charged on a usage basis at a finer granularity. Nonetheless, the Squid software we use has allowed us to build a reasonably fast, reliable U.S. component of a global caching hierarchy.
For more information please see http://www.nlanr.net/Cache/
Appendix (technical details on cache administration)
Configuration
The caching software we use is highly configurable, so much so as to be overwhelming for most new users. Since it seems that most people expect plug-and-play software, choosing default values for the software package required insight into cache administrator behavior.
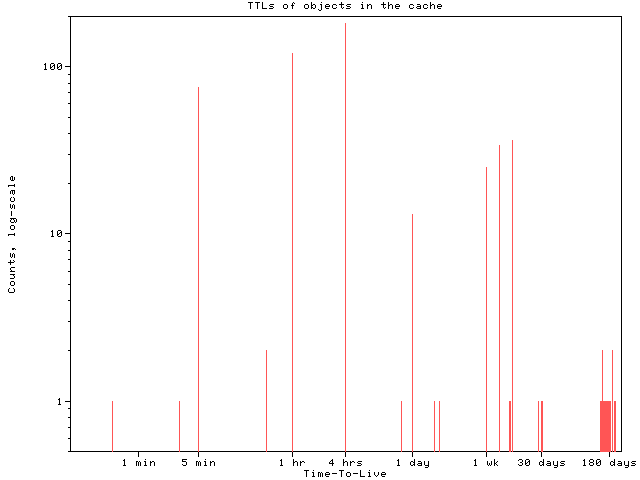
Document time-to-live (TTL) parameter
Configuration values for one node in a hierarchy will affect all nodes and users underneath. Cache object (document) lifetime values are a good example. Since users, particularly international ones, are connected with a wide range of link speeds and quality, finding a set of parameters that reasonably addresses everyone's needs is difficult.
Consider a top-level cache T configured to cache ftp objects for two weeks and a lower-level cache L that uses three days. When a request for an object first arrives at L, L will forward the request to T, and T will request the object from the source. Both L and T will keep a copy of the object. Three days later, the object will expire from L but will remain in T. If L receives a request for the object, L will forward the request to T, who will return the object from its cache without contacting the source server.
Users of cache L may want to be sure that all objects served through their cache are no more than three days old. But, because their parent cache T uses an object TTL of two weeks, they could end up receiving objects more than three days old. Since most likely a different organization administers cache T, cache L has little power to change the situation, except by complaining to the administrator of cache T.
Finding a balance when multiple users have different personal browsing objectives is difficult. While some may be willing to pay the costs, either financial or performance, to ensure receiving current data, others may favor fast, cheap access over freshness.
To a certain extent, this dilemma points to a deficiency with http: the client can not specify an acceptable degree of staleness. One can't request: `Don't get a new version unless the cached one is more than X days old.'
Sibling caches should use roughly the same TTL values. A sibling cache is essentially a virtual extension of your own cache and confusing behavior may result if a sibling has quite different configuration parameters. The optimal relationship between parent and child caches is less clear; it depends on their relative sizes. If they are roughly the same size, and assuming the parent cache is busier than its child caches, the parent cache should have shorter TTLs than its children since objects are added to a busy cache at a higher rate. If the cached objects do not expire as quickly as new ones arrive, the cache must expel some objects to make room for new ones.
On the other hand, if the parent cache is bigger than its children, the parent should have longer TTL values, to maximize the chances that a parent cache still retains a copy of an object that the child cache had to remove to regain space.
Troubleshooting
Our software currently lacks a convenient mechanism for a cache administrator to observe overall TTL behavior, e.g, to verify that configuration parameters are correct and not causing unanticipated side effects. Indeed, currently the only way to verify that a cache is behaving properly is to watch its logfile. In a couple of cases, users reported software bugs based on noticing strange logfile entries, but not everyone has that kind of time.
Objects with no inherent TTL
There are other TTL-related difficulties. While http servers can provide specific TTL values, other protocols (e.g., ftp, gopher) do not. Caches must assign the TTL value to such objects. Perhaps more importantly, there is no If-Modified-Get method for gopher and ftp. Fortunately, gopher traffic comprises an almost insignificant percent of Web traffic and ftp objects tend to be more stable and permanent than http objects.Negative TTLs
Negative TTLs are another controversial aspect of our software. The software saves information regarding certain failures in http requests or dns lookups for a brief period, e.g., 5 minutes, This negative caching occurs for 404 Not Found responses, since we do not expect that a subsequent request for the same object will result in suddenly being able to find it. Note that the reload button on a browser will always override cached objects, including those which are negatively cached.
The basic disadvantage to negative caching is that people do not really expect it. We have heard about many situations in which someone tries to access a web page and receives an error from the cache (e.g. connection refused or host unknown). If they try again in 30 seconds (without using the reload button), they may receive the exact same error message. Out of curiosity or despair, they try the same page without using the cache, and it works perfectly. The natural conclusion is that the cache software is severely broken and should never be used again. Feedback from cache administrators leads us to believe that relatively few think that negative caching is a net win, given the inconsistencies with current browsing behavioral assumptions. A situation similar to the one described above probably needs to occur only once before an administrator will disable negative caching to eliminate it as the source of any potential problems, rather than deal with trying to explain it to their users.
Operating system parameters
As with any other application, the cache software requires a stable underlying operating system in order to be useful. Some interesting operating system problems caused us considerable grief during the month of May 1996.
It began slowly, with our busiest cache site, at NCSA in Urbana-Champaign, Illinois. Approximately once or twice per week, the host computer would become unresponsive, both to network access and to keyboard input at the console. Whenever this happened, we would phone the machine room operators in Illinois and ask them to reboot the computer. We also asked if there were any interesting messages on the console to indicate the problem. In most cases, the console had the message "out of mbufs."
We opened problem reports with the vendor technical support organization, but with very little data to go on. The vendor occasionally sent us newer versions of some network drivers, but they did not help. Slowly, the problem intensified, as the other caches approached the utilization threshold where the busiest one had problems, they all began to exhibit the same behavior. At one point all of our root cache machines were crashing several times a day. With some trial-and-error investigation, we came to suspect that the problem was related to transferring large objects into the cache.
The continued increase in usage of our cache system was frightening at this point because the vendor had no solutions for our problem. To make the situation worse, when one cache machine went down, the others would need to absorb the load, thereby hastening the inevitable demise of the next busiest cache. Since we claimed to be building a scalable, robust web caching architecture, having to tell our participants to `stop using our caches because they can not handle the load' was not an attractive thought. On the other hand, the machine room operators were growing irritated with our phone calls having to reboot the machines often several times a day. We decided that we should stop handling requests for large objects such as ftp files, movies, and sounds. This measure somewhat alleviated the situation, but not completely.
After our problem was escalated to outside of the technical support organization, it was finally resolved. The root cause turned out to be an operating system bug which apparently had never before been subjected to behavior that would expose it. The behavior of our cache software and the ultimate resolution of the problem spawned fruitful discussion on our project mailing list regarding how virtually every hardware vendor had faults, that no one had yet offered the ultimate Internet server machine, certainly not affordably.
Misbehaving sources
Early in the project we were excited to see cache traffic from Hewlett Packard, identified by their network number (15.x.x.x). We contacted administrators at Hewlett Packard, only to find their confusion at the particular participating address, which did not exist anywhere on entire network. We initially suspected someone trying IP spoofing, a router bug, or an HP address leaking out into the Internet.We noticed that we only received ICP queries from this site, and never any actual http requests, which made sense since ICP replies would never arrive, since they were being sent to a non-existent address within the Hewlett Packard address space. We were able to finally track down the source of the bad address by correlating ICP requests for www.nlanr.net with the actual requests logged by the NLANR http server. The http were coming from a site in Australia. Email contact confirmed that this was our mystery site, a company that apparently was previously a part of HP and had continued to use the HP address space internally.
last updated 4 nov 1996
questions or comments: info@nlanr.net.