

Traffic Dynamics Testbed
Authors: M. Mathis (PSC), G.L. Huntoon (PSC), K. Claffy (CAIDA)
Abstract
Historically, network testbeds have focused on issues relating to either high bandwidth or advanced services. For various reasons nearly all testbeds carry little traffic beyond a few chosen applications. Networks that carry heavy "routine" traffic are off limits to network researchers. This deep dichotomy in network usage has prevented nearly all effective research in traffic dynamics. We need to have a way to study how traffic is affected by other traffic, in the presence of advanced services. Specifically, we are proposing the development of a Traffic Dynamics Testbed (TDT). This testbed would not only provide very high bandwidth links based on leading edge technologies, but also allow for the broader study of how all layers of this infrastructure interact and support a wide range of traffic types and services. Traffic restrictions associated with previous testbed initiatives have created an artificial traffic-less environment. A critical component of the Traffic Dynamics Testbed would be the inclusion of real, operational traffic over the testbed infrastructure. The Traffic Dynamics Testbed would be parallel to existing standard (either Research and Education or even Commercial) networks, with "knife switches" to allow real user traffic can be routed over either the production infrastructure or the TDT. The TDT would be built using leading edge networking infrastructure and technologies at high bandwidths than existing networks. There would be significant intervals when the TDT carried no real user traffic. The purpose of these intervals would be to allow network researchers the opportunity to deploy, test and experiment with new technologies, services, and applications over the unloaded TDT. There would also be intervals when the TDT carried real, production quality traffic. By operating the TDT in both modes, issues such as understanding the traffic behavior over new technologies in the presence of network congestion could be addressed.
Introduction
Historically, network testbeds have focused on issues relating to either high bandwidth or advanced services. For various reasons nearly all testbeds carry little traffic beyond a few chosen applications. Networks that carry heavy "routine" traffic are off limits to network researchers. This deep dichotomy in network usage has prevented nearly all effective research in traffic dynamics. We do not understand network congestion or how advanced services affect other users or even how to effectively fill a large network with diverse traffic. We need to have a way to study how traffic is affected by other traffic, in the presence of advanced services.
Specifically, we are proposing the development of a Traffic Dynamics Testbed (TDT). This testbed would not only provide very high bandwidth links for investigating advanced services and leading edge technologies, but also allow for the broader study of how all layers of the infrastructure behave under a wide range of traffic types and services. The primary new feature of the TDT is ability to interpose research infrastructure under heavily aggregated production traffic.
In the past, testbeds have been aimed at solving the specific problem of achieving higher data rates for single applications. The proposed testbed address this issue, while also addressing the issue of getting heavy aggregated traffic to work over the same links as well.
Traffic Dynamics Testbed
All past testbeds have experienced a constant tension in regards to, who is the actual audience for the testbed: the users whose applications are being developed and tested, or the network researchers who are developing the underlying infrastructure? The goal of the Traffic Dynamics Testbed is to provide a facility that meets the needs of both groups. The applications people want stable and predictable network properties while the while the network researchers want to change things. These conflicting needs are met by relying on parallel infrastructure.
Critical technological components of the TDT include:- High bandwidth links based on leading edge technologies;
- Parallel, or co-located with existing production, production-like infrastructure or a second testbed;
- Full capacity interconnects between the parallel infrastructures;
- Fast IP-routing and/or switching "knife switches" to transparently move the traffic between the two networks.
- A mix of real traffic types, from single high bandwidth applications, to large aggregated traffic flows from large communities of non-researchers..
Critical policy components of the TDT include:
- An Appropriate Usage Policy (AUP) that permits all traffic to use the TDT as long as that usage is intermittent and there is other parallel infrastructure for which the traffic is permitted.
- Site connectivity policies that require that connected sites retain sufficient non-TDT connectivity to approximately match their TDT connectivity.
- Site connectivity policies that require that connected sites be able to route the majority of their traffic over the TDT.
The above technical and policy components support an environment where heavily aggregated non-research traffic can be routed over either the TDT or other comparable parallel infrastructure. This can protect users and applications people from changes in the TDT. Since the TDT can be unloaded, the network researchers have opportunity to make changes without disrupting users.
This testbed will support a broad study of how all the layers of the network infrastructure interact and support a wide range of traffic types and services. Below is a detailed description of all the primary components for the TDT.
Definitions
- User (networks /traffic /applications): all nominally 24*7 operational infrastructure and it is use. Includes commodity, federal agency, HPCC, I2, Abilene and other high performance networks.
- Collaborator(s /applications /traffic): Application developers (and their applications and traffic), which have some sort of privileged access to the network subject to limited schedules.
- Network Researchers /Research networks: Researchers and their networks primarily used to explore research questions in networking. Network researchers may either have their own diagnostic applications or work with collaborators for test traffic.
We distinguish between "user" and "collaborator" solely on the basis of expected operational schedules.
Technical Components
The TDT would be built using leading edge networking infrastructure and technologies at high bandwidths than existing networks. The TDT will have locations where it is parallel (or co-located) with user networks. User traffic loads can then be placed on the testbed infrastructure in a controlled manner using "knife switches" that allow real user traffic to be routed over either the production infrastructure or the TDT. Thus, a critical component of the Traffic Dynamics Testbed is the inclusion of authentic operational traffic over the testbed infrastructure.
Clearly, the TDT is not meant as a replacement for the existing Research and Education or Commercial Internet networks. The TDT operational environment will include significant time intervals when the testbed carries no user traffic, but is instead available to network researchers to deploy, test, and experiment with new network technologies, services, and applications over the unloaded TDT. Other time intervals will be dedicated to carrying real, production quality traffic over experimental infrastructure. By operating the TDT in both modes, issues such as understanding the traffic behavior over new technologies in the presence of network congestion could be addressed.
One of the key technical components of the TDT is the "knife switch". These "switches", which can be implemented in hardware, software or both, must be capable of switching traffic in a fast and clean manner so that routine switch transitions are transparent to the applications (and end-users). The TDT infrastructure must contain sufficient monitoring and measuring infrastructure so that TDT failures are quickly detected and the traffic is automatically switched back to the original network infrastructure. Possible guidelines for the switches are less than 100 ms to switch the traffic in either direction under routine conditions and less than 10 seconds to detect TDT failures and switch back the traffic. In general, the TDT must include mechanisms for providing a wide range of traffic mixes over the infrastructure - from high bandwidth applications in a lightly loaded environment, to a large aggregate traffic mix, which produces congestion on the links. Thus, one desirable TDT feature is a mechanism to associate specific collaborator application traffic to the TDT, allowing the application to be tested over the TDT during lightly loaded periods. Similarly, another mechanism could protect particularly sensitive user traffic from the uncertainties of the TDT infrastructure.
Problems to be Addressed and Types of Experiments
The TDT is designed to support a wide range of networking experiments as well as the investigating interaction between real applications and the underlying network infrastructure. In this section we describe some problems that could be investigated.
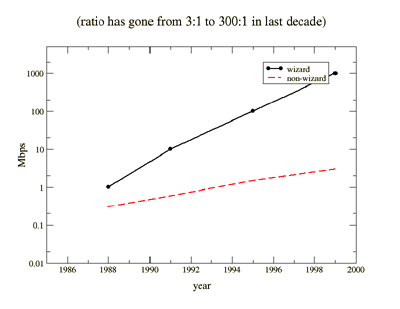
The "wizard" gap.
Figure 1 illustrates what we refer to as the "wizard" gap - the difference between the bandwidth a user (or application) can get over a testbed network where the application and network stack has been tuned by a network "wizard" and what a normal user will see. Notice that the ratio between the gap was about 3:1 in 1988 and is now more than 300:1. This wizard gap is due to two very large effects: end-systems (hosts) are optimized for relatively low bandwidth public markets; and the network itself does extremely well at hiding its own bugs.
The web100 project will directly address end-system tuning and indirectly address the hidden bugs problem. See http://www.web100.org. Although beyond the scope of this paper, if web100 is successful it will permit non-wizards to attain full network data rates on many paths. This will push potential Internet loads to unprecedented levels. Historically, ISPs have nearly always been able to out pace their traffic growth. What will happen if this is no longer true? What will happen if there are a significant number of end-systems that can always go faster than the network? We do not understand sustained congestion. We do not understand how today's Internet (nearly all drop tail queues) drops sufficient packets to throttle TCP, without long queues. We now have data points (from web100 and others) that suggest that on many paths a single well-tuned TCP can completely change the delay statistics. In some cases a single well-tuned TCP connection can make the path is unusable for interactive traffic (much less real time).
This implies that there are very few well-tuned TCP flows in the Internet today, and that wide deployment of well-tuned TCP may cause service disruptions to all delay sensitive applications. We desperately need to study how well tuned TCP interacts with bottlenecks in the core of the Internet.
The lack of deployed QoS
Although QoS has received huge attention in the research community, it has yet to be generally deployed the public Internet. Will this become a crisis with higher loads? The lack of convergence in the research community begs the meta-question, are we even addressing the right problem? Current arguments in the standards community show a clear lack of real information on the nature of traffic and the needs of the ISPs or applications.
Pervasive broken link layers
There is a recurrent problem that link designers repeatedly build link layers that do not behave well under windowed protocols such as TCP. Examples of problematic link layers include Ethernet (capture effect), Committed Access Rate (needs pacing), and Various wireless channel acquisition algorithms. The general issue that the link designers do not understand is that TCP derives all of the packet timings from the network it self, and that it is imperative that if the a link requires a specific packet timing the link must alter the timing to be consistent with it's own needs.
Many link of these problematic link layers function well in some environments but very poorly in others.
There does not exist a method to test if a link layer exhibits this property. We also do not have a theory to describe these phenomena in general.
No models for traffic sharing
We do not currently understand how many small flows (web clicks, etc) interact with long running high rate flows. It is observed that short flows take bandwidth away from long flows. Short flows seem to be "stiffer" than long flows, being less affected by network conditions or other traffic. However, we have no theory describing this effect, nor method to quantify it. We do not understand how long large flows share bandwidth with short flows.
No performance specifications in Service Level Agreements
This is the inverse of the previous problem: We do not know how to specify, implement or validate a SLA that assures a specific performance level for large flows in the presence of heavily aggregated small flows. Ideally some future version of the NGI could be implemented as formal performance requirements in a RFQ for a shared commodity service. We have no idea how to write such a requirement today. Without it we will always be building expensive dedicated networks to support large users, even when these users are small compared to the aggregate loads in the public Internet. Technology to support data transfer performance in an RFQ would revolutionize network purchasing.
The Common Theme
We do not understand how traffic behaves in a full network. We do not understand how the network and cross traffic affect protocols. We do not even have a glimmer of understanding of the network equivalence of turbulence. We do not understand congestion.
Conclusion
The real problem we need to address is not filling yet another faster, empty link, but understanding traffic dynamics so that we can build networks that can deliver high performance, even when fully loaded.
To attain this understanding we need a Traffic Dynamics Testbed that with the technical and policy machinery necessary to inflict research infrastructure on heavily aggregated research infrastructure.