Report Generator Tutorial
Introduction
The report generator is a collection of scripts which process flow files
(such as those created by
crl_flow)
and creates graphs and tables to allow users to more easily understand the
traffic on a monitored link (or collection of links). The reports are
displayed by an interactive web page which organizes different views of the
traffic data. The basic flow is shown below (sections in boxes can be run
on separate machines if desired):

Data from crl_flow are stored by store_monitor_data into database files (using RRDtool). These RRD files are then periodically read by create_report to generate graphs and tables summarizing the processed data, which are copied into directories for viewing via the web page. This page is a CGI script named display_report and will display graphs and tables using predetermined configurations and/or allowing the end user to choose what to display.
For the purpose of this example, we will make several simplifying assumptions. The collection of flow data, processing/storage, and web display will all take place on the same machine, and only one link will be monitored. In practice, these three functions can be split across multiple machines. More information about how these scripts work can be found here. We will also be only storing/displaying protocol and application information, but pointing out what's required to display other data aggregations, including Autonomous Systems (AS) and countries.
Prerequisites
The most important prerequisite for running the report generator is RRDtool. If it is not already installed on your machine, it can be downloaded from http://oss.oetiker.ch/rrdtool/download.en.html and installated by following the instructions at http://oss.oetiker.ch/rrdtool/doc/rrdbuild.en.html
In order to create pie charts, you will also need GD::Graph (http://search.cpan.org/~bwarfield/GDGraph-1.44/), which itself requires GD.pm (http://search.cpan.org/dist/GD/) and GDTextUtil (http://search.cpan.org/dist/GDTextUtil/).
Country lookups are currently done via the CAIDA NetGeo database (https://www.caida.org/catalog/software/netgeo/) and require LWP::UserAgent (http://search.cpan.org/~gaas/libwww-perl/). NetGeo is deprecated and has not been updated in over five years, but it's currently the only publicly available country lookup code that is supported by CoralReef. For simplicity, our example report generator will not display countries, and so it will not do country lookups.
Generation of maps showing traffic sources and destinations requires GD.pm (see above) and a CAIDA tool, plot-latlong, which can be found at https://www.caida.org/catalog/software/plot-latlong/. However, this is not required if no maps are created.
Displaying the final page will require a web server with the ability to run CGI scripts. Most servers have this ability, but more information can be found in the Apache documentation.
Installing CoralReef
The report generator is a part of the CoralReef suite; CoralReef must be installed in order to run the report generator. The latest release can be found at https://www.caida.org/catalog/software/coralreef/status
The package must first be unarchived, for example with: tar xzf coral-3.8.1.tar.gz
The current version of CoralReef software has been tested on:
- FreeBSD 4.x
- Linux 2.4
- SunOS 5.8
- MacOS Darwin 6.6 (OS X)
- FreeBSD (2.x, 3.x, and 4.x)
- Linux (2.0.36 and 2.2 pre*)
- Solaris 2.5
Please read the INSTALL file, as it explains how to build and install
CoralReef. If using the defaults, you just need to run ./configure && make && make install. Important flags (for the report generator) to configure are:
-
--with-rrd(set to path to RRDtool libs if they aren't in perl's default path) -
--with-gd(set to path to GD libs if they aren't in perl's default path)
Note that CPAN installs modules in a site_perl directory that might not be found by perl unless specified explicitly. Therefore, the path to non-default libraries installed in ~/lib might be need to be given as ~/lib/perl5/site_perl, for example.
Report Configuration
Before running the report generator, several things need to be configured first. First, directories will need to be created to store flow files, RRD files, and generated graphs. These examples will make several assumptions about directory structure, please modify to fit your own setup. We assume that there is a /data directory for storing large files, that web server CGI scripts are stored in /www/cgi-bin and image files are stored in /www/images.
mkdir /data/flow_files mkdir /data/report_files
Several config files are used to set up the running of the report generator. CoralReef provides example files in the doc/doc directory where it was installed.
The main report config file is report.conf. It must be updated to fit your setup, however.
Change the "name" field in the monitor stanza from "sdnap" to whatever you wish to name your monitor. We will call our monitor "campus_inbound".
Comment out the following fields:
- netacq
- ports
- delay
- make_map
If you want to store information about
Autonomous
Systems (or AS for short), the "routes" field will need to be changed to
point to a parsed BGP table, created by running
parse_bgp_dump
-g on a BGP dump, such at those from
Route Views.
Otherwise, it should also be commented out.
Edit the transfer fields to match your setup:
- cp_cmd (the command used to transfer data)
- server (the name of the web server)
- cgi_dir (the directory on the web server that serves CGI scripts)
- html_dir (the directory on the web server that serves static content)
mkdir /www/cgi-bin/campus_inbound mkdir /www/images/campus_inbound mkdir /www/images/campus_inbound/big
For our example, we will have
shared {
name: transfer
cp_cmd: rsync -qa
# server: (commented out because transfers occur on same machine)
cgi_dir: /www/cgi-bin
html_dir: /www/images
}
Edit the generated directory fields to match your setup:
- graph_dir (the directory that normal-sized graphs will be put into)
- big_dir (the directory that larger version of graphs will be put into)
- table_dir (the directory that table data files will be put into)
- rrd_dir (the directory that RRD files will be put into)
graph_dir: /data/report_files/graphs
big_dir: /data/report_files/big_graphs
table_dir: /data/report_files/tables
rrd_dir: /data/report_files/rrds
Edit the "tables" and "cat_map" fields to match your reporting needs. The available table types for storage are:
For a basic setup, we recommend only using Proto Table and App Table. Note that these table names are currently case-sensitive. The "cat_map" field is used to give descriptions to the different categories, which are derived from the table names as described in report.conf. It is also case-sensitive. It is a list of pairs of categories and long names, such as:- proto, Protocol
- app, Application
- src_as, Source AS
- dst_as, Destination AS
- src_country, Source Country
- dst_country, Destination Country
tables: Proto Table, App Table
cat_map: proto, Protocol, app, Application
Storing AS information will require a parsed BGP
table (as mentioned above) and requires more disk space than protocols and
applications. (In our experience, with the default RRD settings,
applications can require around 1GiB of storage, whereas source and
destination ASes will require around 12GiB.) Storing country data can slow
down processing (for NetGeo queries) and as mentioned above, NetGeo results
can often be incorrect.
One thing to note is that with the current release, the colors used to represent different RRDs (such as HTTP, STMP, SSH, etc) are randomly generated each interval (which defaults to 5 minutes in crl_flow). This can be overridden with the "colors" stanza, where you can specify colors for known RRDs in #RRGGBB format.
An important (but small) file that needs editing is subif_map.conf. It maps interface/subinterface numbers to a monitor name. The most common case of subinterface numbering is 0[0], which represents a single interface with no subinterfaces, but some links will have multiple subinterfaces, which will be listed in the headers of the flow files. The subinterface represents different things for different links; for instance on an ATM link, it will represent a VPI/VCI pair, whereas on ethernet it could represent a VLAN ID. One output file of crl_flow can contain multiple different subinterfaces. For more information, see the documentation on CoralReef command usage. The current release is missing an open curly bracket after the word "shared", and must have one to work properly. Otherwise, all that needs changing is the name of the monitor to match the name in report.conf ("campus_inbound"). This will look like:
shared {
name: subif_map
0[0]: campus_inbound
}
The next config file to edit is cgi.conf. The most important field to change here is the monitor name, from "monitor1" to "campus_inbound", and we also change the description to "Inbound Traffic". This file will be placed in the web server's cgi-bin directory, which is /www/cgi-bin in our example.
group {
name: monitors
campus_inbound: Inbound Traffic
}
The last config file is monitor.conf. One of these is needed for each monitor, but for our example we will only have one. This file needs to have its "base_url" field changed to point to the URL where images will be stored. In our example, it will be "images" (or given in absolute form, http://machinename/images/), which corresponds to the /www/images directory we created earlier. Since we aren't storing information about countries or Autonomous Systems, we will comment out those fields in the "sources" stanza, and we also comment out the "map" field. We will place this file in /www/cgi-bin/campus_inbound.
base_url: images
group {
name: general
base_url: images
}
group {
name: sources
proto: Protocol
app: Application
# src_country: Source Country
# dst_country: Destination Country
# src_as: Source AS
# dst_as: Destination AS
}
group {
name: graphs
ts: timeseries graphs (abs)
ts_perc: timeseries graphs (%)
pie: pie graphs
table: tables
# map: maps
}
Running the Report Generator
This assumes that we are listening to an interface namedeth0
which has access to the link we are measuring.
First, start collection with:
crl_flow -I -O/data/flow_files/%s.t2 if:eth0
Some other useful options to consider are -Calignint, which
enables
interval alignment,
and -b, to output in binary format, which takes up less disk space
(at the cost of easy readability).
Next, process and store the flow files:
spoolcat -d '/data/flow_files/*.t2' | store_monitor_data report.conf subif_map.confThis example assumes that report.conf and subif_map.conf are in the current directory, and that spoolcat and store_monitor_data are in the user's PATH.
spoolcat is a simple script included in CoralReef that waits
indefinitely for new files to appear in a directory and pipes them to stdout.
The -d option deletes flow files after they've been output; for
other options that preserve the flow files (for instance, to do other analysis
on them), see the
spoolcat documentation.
Once the flow files have been processed and stored, we intermittently generate graphs for display on the web page. This is easily done by using cron to schedule repeated tasks. Add the following lines to the crontab (with crontab -e) of the user generating reports:
PATH=/bin:/usr/bin:/usr/local/bin:/usr/local/Coral/bin 0,15,30,45 * * * * create_report report.conf
Next, copy the display_report script into the cgi-bin directory:
cp /usr/local/Coral/bin/display_report /www/cgi-bin
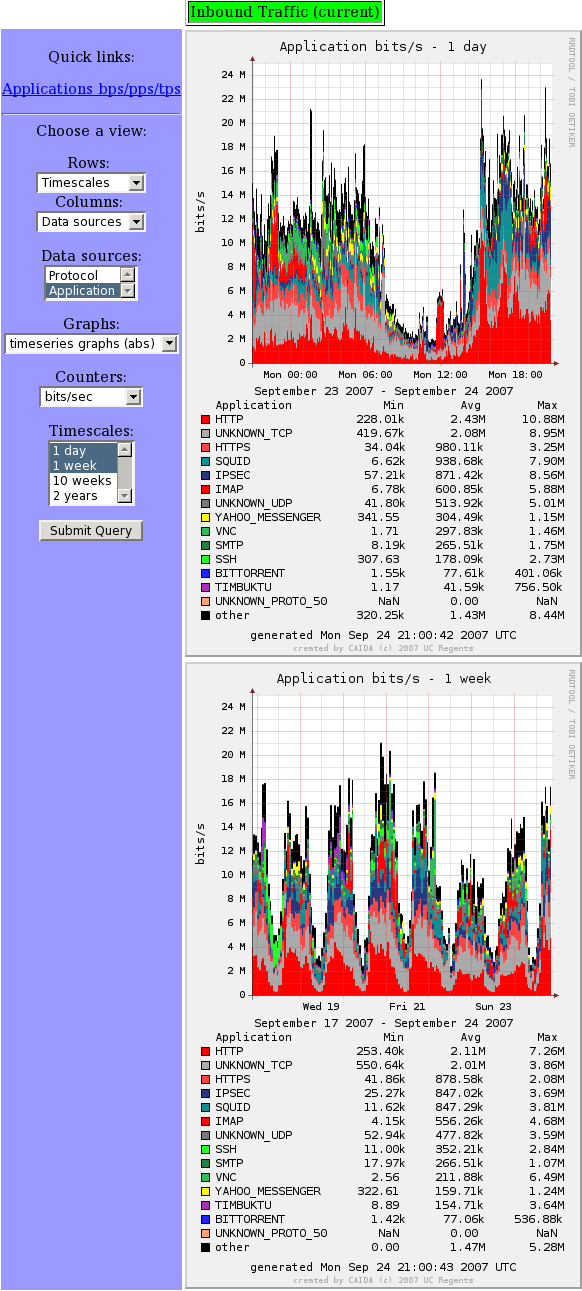
Once the data have been transferred, there should be a working page on
at http://machinename/cgi-bin/display_report which looks something
like: