

FlowScan Architecture
Essential Data Structures
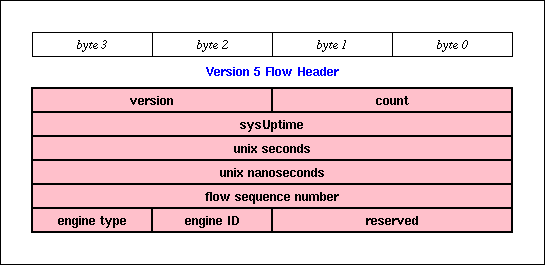
Cisco's Version 5 flow-export packets [Cisco] contain a flow header followed by a number of flow entries. The number of flow entries in the packet is in the count field in the flow header. In contrast to Version 1 flow-export, Version 5 also includes AS numbers and netmask lengths for the source and destination. [McRobb]
While the NetFlow V5 PDU is well documented in [Cisco] and [McRobb], the following two figures indicate which flow attributes are available to FlowScan. At the same time that this set of attributes enables FlowScan's current capabilities, it also limits those capabilities due to the need to impose performance requirements and measurement compromises. For more information, please see Dave Plonka's paper.
Cisco NetFlow Version 5 Flow Header:
Cisco NetFlow Version 5 Flow Entry:
http://oss.oetiker.ch/mrtg/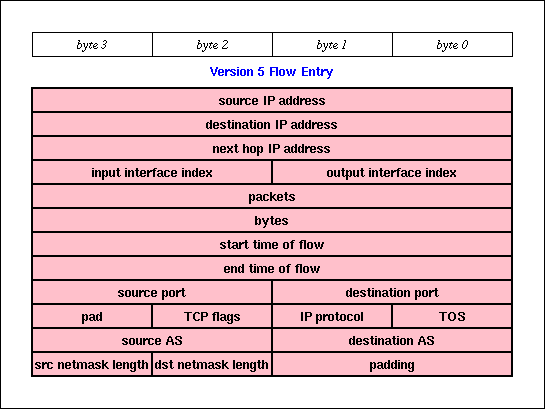
Hardware
While FlowScan does not have strict platform requirements, most currently deployed installations have dedicated either a SPARC machine running Solaris, or an Intel machine running GNU/Linux or *BSD as their FlowScan system. An additional benefit to using one of these platforms is the ability to co-locate cflowd so that both FlowScan and cflowd have access to the same local disks. The fastest FlowScan performance has been reported on multi-processor Intel machines.
FlowScan's Hardware Components:
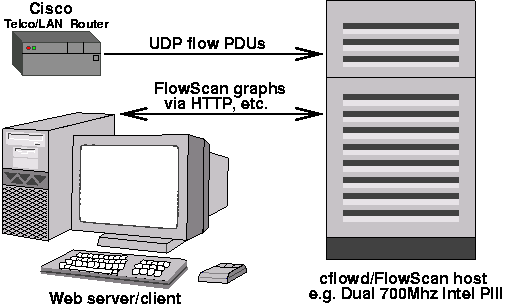
For further information, see the FlowScan installation documentation provided in the distribution package. It contains recommendations for selection and configuration of disk space and network interface card.
Software
A FlowScan system consists of a number of software components. First, cflowd (described in detail in [McRobb2]) is used by FlowScan strictly as a flow collector. Specifically, FlowScan uses the cflowdmux and cflowd programs. cflowdmux receives UDP Cisco Version 5 flow PDUs from routers and passes them to cflowd, which then writes them to disk in a portable, well-defined format of its own. FlowScan requires a patch to the cflowd sources. The patch modification enables cflowd to rotate and time-stamp its flow files at FlowScan's pre-defined sampling interval (typically 5 minutes). The decision to use five minute samples was influenced by the popular tool MRTG [MRTG].FlowScan's second software component is a Perl script called flowscan. Note that its executable name consists only of lower-case characters. "FlowScan" refers to the package whose primary procedural component is the Perl script flowscan. flowscan loads and executes report modules chosen by the network administrator. Report modules are themselves Perl modules derived from the FlowScan class defined in the FlowScan.pm Perl module. flowscan is responsible for maintaining databases of statistics regarding the IP traffic represented by the flows.
The third major component of FlowScan is RRDtool, which is used to store numeric time-series data and automatically distill or aggregate data into averages over time. Using RRDtool in this manner essentially replaces cflowd's arts++ data aggregation features. RRDtool maintains a set of RRD files that form an extensive database of IP flow metrics. RRDtool and RRGrapher are also responsible for producing graphic output as .gif or .png format images.
Finally, FlowScan utilizes operating system utilities such as the make command, the Unix cron job-scheduling facility, and the gzip compressor. On occasion, it may be useful to use the flowdumper utility, supplied with cflowd, to examine raw flows.
FlowScan's Processes and Files:
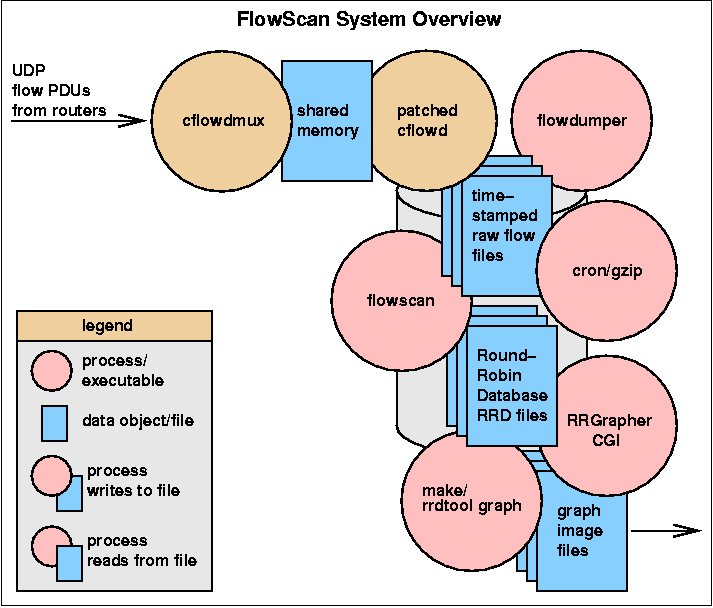
FlowScan uses the disk as a large buffer area in which cflowd writes raw flow files that wait to be post-processed by flowscan. This buffering is an important fail-safe when used in networks with very high traffic or flood-based DoS attacks because FlowScan sometimes develops a backlog of flow files yet to be processed. These pending files may total Gigabytes in size.
Anatomy of a FlowScan Report Module
A FlowScan report module is an object-oriented Perl module. The module name FlowScan.pm implements the base reporting class, and serves as an example of what any FlowScan report module must provide. Three methods are available that work on FlowScan-derived class objects:
- perfile - Invoked on the time-stamped raw flow file produced by patched cflowd prior to any flowscan processing, e.g., once-per-file. Converts the raw flow file's embedded time-stamp to a native Unix time_t representation. Expects raw flow files to be named using the format "flows.YYYYMMDD_HHMISS+TZ". For example, "flows.20000917_20:08:14-0500" is a file created at 8:08PM on September 17, 2000 in a locale that is five hours west of GMT.
- wanted - Invoked by flowscan to parse and then select or discard each flow. Interrogates values stored in each flow to determine whether the flow meets selection criteria.
- report - Invoked after flowscan finishes processing all flows within the raw flow file. Analyzes and dispatches any information selected and collected by wanted.
These three methods enable FlowScan's modular reporting structure. The flowscan script essentially provides a framework for periodic testing and reporting on flow content. Analysis and visualization are handled by other integrated modules peripheral to flowscan.
References
http://oss.oetiker.ch/mrtg/
- [Cisco] "Cisco's IOS NetFlow Feature".
1.
https://www.cisco.com/c/en/us/products/ios-nx-os-software/ios-netflow/index.html
2. http://www.cisco.com/warp/public/cc/pd/iosw/ioft/neflct/tech/napps_wp.htm - [McRobb] Daniel W. McRobb, "cflowd configuration", 1998-1999. https://www.caida.org/catalog/software/cflowd/configuration/configuration.html
- [McRobb2] Daniel W. McRobb, "cflowd design", 1998. https://www.caida.org/catalog/software/cflowd/design/design
- [MRTG] Tobias Oetiker, Dave Rand, et al. "Multi Router Traffic Grapher (MRTG)" http://oss.oetiker.ch/mrtg/