

Summary of Anonymization Best Practice Techniques
Privacy, security, legal, proprietary ownership, and other economic complications often prevent distribution of Internet data. This page describes issues, offers recommendations for anonymizing IP address fields in captured trace data from three different network environments, and links to an annotated bibliography of papers in the field. CAIDA's research on anonymization techniques and implications is supported by DHS's IMPACT project (formerly known as PREDICT).
Background
Sharing of sensitive network data with researchers is almost always blocked on the need to protect personally identifying information (among other political and economic constraints), but there has been little attention thus far in analyzing and comparing existing Internet data anonymization schemes for data leakage and other performance characteristics. A related problem is the lack of experience with data sharing in an admittedly quite young field of Internet science, which means that there is no established code-of-conduct for protecting user privacy, nor history of engaging with Institutional Review Boards to navigate ethical issues in Internet measurement research. In fact, many network researchers consider data protection schemes to be "meta-research" rather than research, resulting in a sub-field without clear incentives, boundaries, or, established modes of inquiry. As a result the academic network research community has its own internal conflicts over questionable research approaches (as we've reviewed before), such as deanonymizing anonymized traces without consulting the data provider, thus violating the trust model of the data provider, and giving all providers even more reason to keep data taps closed off to researchers.
Fortunately, DHS's Science and Technology Directorate is putting resources into the problem, recognizing data protection technology as prerequisite to the success of its other cybersecurity projects, notably its data-sharing project, IMPACT. An early initiative funded under DHS's Cybersecurity program is UNC's evaluation of anonymization schemes. Other groups are starting to hold workshops and attempt to build international consensus regarding ethical data handling practices. Interest is growing, however slowly.
In this spirit, we have investigated current and proposed anonymization schemes that support IMPACT's goal to protect privacy while supporting cybersecurity research. We have added several dozen papers on anonymization topics to our networking bibliography. We provide the following summary of what we have learned so far, including some suggestions to Internet data providers on the use of current and future data anonymization schemes to increase security and privacy. We will update these suggestions as technology develops in future years of the project.
Introduction
For a good literature overview of basic Internet traffic anonymization schemes which have been discussed or implemented , the 2007 document "PRISM State of the art on data protection algorithms for monitoring systems" (IST-2007-215350) provides a good summary, although no recommendations on what techniques to use for particular circumstances. Most existing data provided through IMPACT has been sanitized in two distinct ways: (1) deleting, editing, or otherwise sanitizing payload, including in some cases removing entire packets whose content does not match a specific filter; (2) anonymizing IP addresses of hosts. As of January 2009, all IP-anonymized datasets in IMPACT have used some form of (at least partial) prefix-preserving address anonymization, commonly CryptoPan . Since IP address anonymization is a common problem to all traffic data, including packet traces and netflow logs, we focus on IP address anonymization and make initial recommendations on which techniques seem most appropriate for different capture environments. Pang, et al. in "The devil and packet trace anonymization" provide detailed suggestions for what meta-data should ideally accompany anonymized traces to maximize their utility to researchers, as part of their study of how to optimize tradeoffs in anonymizing their own trace data before making it publicly available. We hope for feedback from other data providers and users about these schemes.
Capture Environments
We identify three types of capture environments that should be treated distinctly regarding IP address anonymization:
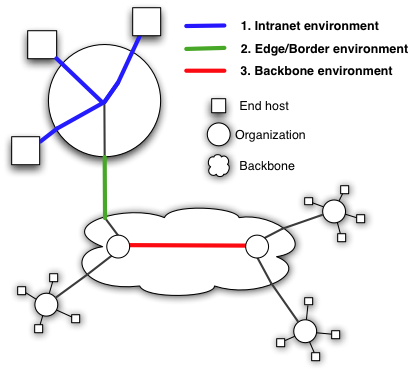
- Inside an intranet - defined primarily by the presence of internal host <-> internal host communication of the organization(s) associated with the data provider, may also contain traffic outside the intranet
- Edge/border of an organization - here there is no internal <-> internal traffic, however traffic is still completely associated with the providing organization(s)
- Backbone / Large peering point - traffic aggregates from multiple sources making identification of a specific end organization difficult; all traffic involving a single end organization is also unlikely to pass through this monitor due to routing
These three environments do not capture all types of network monitoring scenarios, but they effectively guide a conversation. Traffic from a gigapop or local exchange point may look like either category 2 or 3 depending on which links are monitored. If one defines an distributed enterprise, such as the University of California system, as a single entity, then UC's backbone Calren would be an intranet (category 1) for this purpose.
IPv4 Address Anonymization
Ideally, we want a collision-free anonymization/mapping for IP addresses, i.e., a one-to-one mapping. An example of a highly colliding anonymization scheme is Internet2's anonymization of their Internet2 netflow data, since they zero the bottom 11 bits of all addresses. The cryptoPan algorithm, and similar prefix-preserving algorithms which use a key, are all collision-free. Pang, et al.'s anonymization system anonymizes the subnet and host portions of the IP address separately, which only guarantees that two IP addresses in the same unanonymized subnet will also be in the same anonymized subnet, far less structure preservation than cryptoPan provides. Coull, et al.'s, "Taming the Devil: Techniques for Evaluating Anonymized Network Data" analyzed the relative privacy-protecting strength in the mapping for these two approaches. They developed an entropy-based approach to measuring conditional object anonymity, which they define as the anonymity of hosts conditioned upon the deanonymization of other objects in the trace, and found that Pang, et al.'s approach offers greater privacy protection according to this metric, especially after a few address deanonymizations have occurred. Many sites, including CAIDA, still choose to use CryptoPAN for convenience, augmented with Acceptable Use Policies to limit what researchers can legitimately do (and publish) with the data.
Note that specialized services and hosts, e.g., a campus web server, may be impossible to hide under any anonymization scheme, except perhaps those with high collision rates, since by definition the service is special and distinct and therefore identifiable. Note that IP addresses appear in fields outside the IP headers of packets, e.g., in ICMP, DNS, DHCP and NTP messages, where providing more payload may be necessary to certain research questions. Other application protocols also transmit IP addresses internally and would thus require payload scrubbing, but data providers often handle this issue by completely discarding the payload.
-
We recommend either not anonymizing special IP address ranges, e.g., RFC1918 (not globally reachable) addresses, multicast addresses, or -- if environments where such addresses are allocated and used in a way that can convey information on individuals -- anonymizing them separately from other addresses. RFC 1918 addresses may require different treatment when appearing in category 1 traffic (intranet traces), since those addresses are likely in production use internally and and thus map to specific individuals or services. For example, after deciding what special address ranges to preserve, if encoding an address yields an address in the special range, repeat the encoding until it lands back outside the special range, guaranteed to happen given an encoding (mapping) that is one-to-one on a fixed size set. This process cleanly separates the special ranges from the rest of the addresses, facilitating the handling of special ranges differently. One might also decide to selectively anonymize parts of these special ranges, e.g., leave 0.0.0.0/8 unanonymized, but map 10.0.0.0/8 using a keyed non-prefix-preserving mapping. Zhang and Li [ZHA06] described this approach, where special address ranges included IANA reserved ranges, such as 0.0.0.0/8 or 127.0.0.0/8, multicast and class E space.
-
Multicast addresses may require special consideration since it is possible that specific addresses in the multicast ranges could reveal information about the nature of the communication, or could lead to identification of the other end-point of the communication. As mentioned above, one can anonymize inside the multicast range, separately from other address ranges, which will allow researchers to distinguish multicast traffic from other traffic. From an anonymization perspective, the challenging portion of the multicast address space is the source addressed range, where the middle two octets of the address are supposed to specify the source ASN of the traffic. Since organizational information may be too sensitive to reveal, but hard to hide due to the relatively sparse multicast address utilization, if multicast address anonymization is a goal, we recommend encoding the entire source address multicast /8 space with a random (not prefix-preserving, which has no utility for this type of address) deterministic mapping. This encoding distinguishes multiple sources from the same ASN, but aggregates them with other ASNs to prevent easy identification of the ASN. The tradeoff is this approach also prevents any research involving comparison of channels between and within ASNs; if such research is a goal we recommend no encoding of multicast addresses.
-
Scanning traffic, either malicious or management-tool-based, may also merit special handling since the sequential activity introduces structure into the trace that may assist with attempts to deanonymize it. Pang, et al. chose to map internal addresses relating to scanning activity separately, using a heuristic to detect scanning activity. This separation removes the ability to analyze all traffic from a given host involved in a scan (including being scanned) during the trace. Approaches to anonymizing scanning traffic will differ by network environment and sensitivities of network owners.
-
We recommend key-based anonymization. Using a key allows for distributed collection, re-use of keys over time, and may help with schemes that allow multiple anonymization methods to be combined in a single file (to save space).
General recommendations:
Recommendations specific to environment 1 (Intranet):
In addition to the above four general recommendations, we suggest providers of internal network traffic data review the Pang, et al. paper, a detailed case study on how they decided to anonymize their internal traffic traces. Although this anonymization was partly "broken" by Coull, et al., the thorough consideration they give to various anonymization alternatives provides a valuable baseline. Note that Allman and Paxson rebut some of the arguments made in Coull et al.'s work, including how much of the anonymization was actually broken. The conversation embodied in these three papers may be the spiciest technical reading about anonymization, at least available in the public domain.
Recommendations specific to environment 2 (Edge/border of an organization):
Several recent papers have focused on how to de-anonymize the internal addresses of an organization from edge traces. Particularly with (partial) prefix-preserving anonymization, the state of the art in de-anonymization jeopardizes claims that Internet data can be "safely anonymized". Current approaches are weakest when the internal hosts and structure are the most homogenous, for example in a corporate environment with every host running the same reference system. However, with additional meta-information and future improvement of techniques, exposure will only increase. We believe that there is no truly safe way of providing prefix-preserving (including partial or with randomized /24s) anonymization for addresses within an organization for traces taken near the border of that organization. Therefore we recommend providers of traces treat addresses within the organization by either not anonymizing them (handling privacy protection with other technology like AUPs) or using a non-prefix-preserving anonymization scheme (either with or without collisions), keeping in mind that even with non-prefix-preserving schemes, addresses associated with specialized services are more easily de-anonymized, unless the scheme introduces many collisions. In this environment we recommend anonymizing RFC1918 addresses as described above, and anonymizing external addresses via (partial) prefix-preserving algorithms.
Recommendations specific to environment 3 (Backbone / Large peering point):
When aggregation is sufficiently high, prefix-preserving is advisable. If the number of ASes or prefixes observable on the link is low or heavily weighted toward a few organizations, we recommend treating these addresses like internal addresses in environment 2. We acknowledge that assessing the "anonymizability" of a given workload is likely to be hard.
Layer 2 (e.g., Ethernet) Addresses
Although we are focusing on IP (Layer 3) address anonymization, there has been some attention to anonymizing Layer 2 addresses as well, mostly relevant for Environment Type 1 where they will identify NICs on individual hosts (rather than routers for Environments 2 and 3). Pang, et al.'s above-mentioned study considered three methods for randomizing Ethernet addresses: scrambling the whole 6-byte address; scrambling the lower 3 bytes (preserving vendor information); and scrambling the upper and lower 3 bytes independently. The first approach prevents a researcher from using the trace to analyze vendor-specific behaviors, but strengthens the anonymization against reversal attempts. The authors chose the third approach for their traces as a reasonable balance between data utility and privacy. (Note that Ethernet addresses of hosts being scanned must be renumbered or they will reveal the relationship between IP mappings for scanned and non-scanning traffic, described above.)
Attribution
CAIDA would like to thank Keren Tan, Jihwang Yeo, and David Kotz of the CRAWDAD project for providing the seed references for the anonymization bibliography from which we drew for this summary. David Moore wrote the original version of this document in 2008. kc claffy revised it last December 2008. Please email info@caida.org with questions, comments, or corrections.