

DNS Evolution
The Domain Name System (DNS) is a crucial component of today's Internet. The top layer of the DNS hierarchy (the root nameservers) faces dramatic changes: cryptographically signing the root zone with DNSSEC, deploying Internationalized Top-Level Domain (TLD) Names (IDNs), and addition of other new global Top Level Domains (TLDs). ICANN has stated plans to deploy all of these changes in the next year or two, increasing stakeholder interest in measurement, testing, and provisioning for foreseen (or unforeseen) complications. This page describes the Day-in-the-Life annual datasets available to characterize workload at the root servers, and some analysis of the last several years of these datasets as a baseline for operational preparation, additional research, and informed policy. We confirm some trends from previous years, including the low fraction of clients (0.55% in 2009) still generating most "pollution", which constitutes the vast majority of observed queries to the root servers. We present new results on security-related attributes of the client population: an increase in the prevalence of DNS source port randomization, a short-term measure to improve DNS security; and a surprising decreasing trend in the fraction of DNSSEC-capable clients. Our insights on IPv6 data are limited to the nodes who collected IPv6 traffic, which does show growth. These statistics serve as a baseline for the impending transition to DNSSEC. We also report lessons learned from our global trace collection experiments, including improvements to future measurements that will help answer critical questions in the evolving DNS landscape.
The paper "Understanding and preparing for DNS evolution" will be presented at the 2nd International Traffic Monitoring and Analysis (TMA'10) Workshop colocated with the Passive and Active Measurement (PAM) Conference in April 2010.
1 Introduction
The DNS is a fundamental component of today's Internet, mapping domain names used by people and their corresponding IP addresses. The data for this mapping is stored in a tree-structured distributed database where each nameserver is authoritative for a part of the naming tree. The root nameservers play a vital role providing authoritative referrals to nameservers for all top-level domains, which recursively determine referrals for all host names on the Internet, among other infrastructure information. This top (root) layer of the DNS hierarchy is facing three dramatic changes: cryptographically signing the root zone with DNSSEC, deploying Internationalized Top-Level Domain (TLD) Names (IDNs), and addition of other new global Top Level Domains (TLDs). In addition, ICANN and the root zone operators must prepare for an expected increase in IPv6 glue records in the root zone due to the exhaustion of IPv4 addresses. ICANN currently plans to deploy all of these changes within a short time interval, and there is growing interest in measurement, testing, and provisioning for foreseen (or unforeseen) complications. As part of its DNS research activities, in 2002 CAIDA responded to the Root Server System Advisory Committee's invitation to help DNS root operators study and improve the integrity of the root server system. Based on the few years of trust we had built with these operators, in 2006 we asked them to participate in a simultaneous collection of a day of traffic to (and in some cases from) the DNS root nameservers. We collaborated with the Internet Systems Consortium (ISC) and DNS Operation and Research Center (DNS-OARC) in coordinating four annual large-scale data collection events that took place in January 2006, January 2007, March 2008, and March 2009. While these measurements can be considered prototypes of a Day in the Life of the Internet [8], their original goal was to collect as complete a dataset as possible about the DNS root servers operations and evolution, particularly as they deployed new technology, such as anycast, with no rigorous way to evaluate its impacts in advance. As word of these experiments spread, the number and diversity of participants and datasets grew, as we describe in Section 2. In Section 3 we confirm the persistence of several phenomenon observed in previous years, establishing baseline characteristics of DNS root traffic and validating previous measurements and inferences, and offering new insights into the pollution at the roots. In Section 4 we focus on the state of deployment of two major security-related aspects of clients querying the root: source port randomization and DNSSEC capability. We extract some minor insights about IPv6 traffic in Section 5 before summarizing overall lessons learned in Section 6.2 Data sets
On January 10-11, 2006, we coordinated concurrent measurements of three DNS root server anycast clouds (C, F, and K, see [13] for results and analysis). On January 9-10, 2007, four root servers (C, F, K, and M) participated in simultaneous capture of packet traces from almost all instances of their anycast clouds [5]. On March 18-19, 2008, operators of eight root servers (A, C, E, F, H, K, L, and M), five TLDs (.ORG, .UK, .BR, .SE, and .CL), two Regional Internet Registries (RIRs: APNIC and LACNIC), and seven operators of project AS112 joined this collaborative effort. Two Open Root Server Network (ORSN) servers, B in Vienna and M in Frankfurt, participated in our 2007 and 2008 collection experiments. On March 30-April 1, 2009, the same eight root servers participated in addition to seven TLDs (.BR, .CL, .CZ, .INFO, .NO, .SE, and .UK), three RIRs (APNIC, ARIN, and LACNIC), and several other DNS operators [9]. To the best of our knowledge, these events deliver the largest simultaneous collection of full-payload packet traces from a core component of the global Internet infrastructure ever shared with academic researchers. DNS-OARC provides limited storage and compute power for researchers to analyze the DITL data, which for privacy reasons cannot leave OARC machines.1 For this study we focus only on the root server DITL data and their implications for the imminent changes planned for the root zone. Each year we gathered more than 24 hours of data so that we could select the 24-hour interval with the least packet loss or other trace damage. The table in Fig. 1 presents summary statistics of the most complete 24-hour intervals of the last three years of DITL root server traces. Figure 1 (below) visually depicts our data collection gaps for UDP (the default DNS transport protocol) and TCP queries to the roots for the last three years. The darker the vertical bar, the more data we had from that instance during that year. The noticeable gaps weaken our ability to compare across years, although some (especially smaller, local) instances may have not received any IPv6 or TCP traffic during the collection interval, i.e., it may a traffic gap rather than a measurement gap. The IPv6 data gaps were much worse, but we did obtain (inconsistently) IPv6 traces from instances of four root servers (F, H, K, M), all of which showed an increase of albeit low levels of IPv6 traffic over the 2-3 observation periods (see Section 5).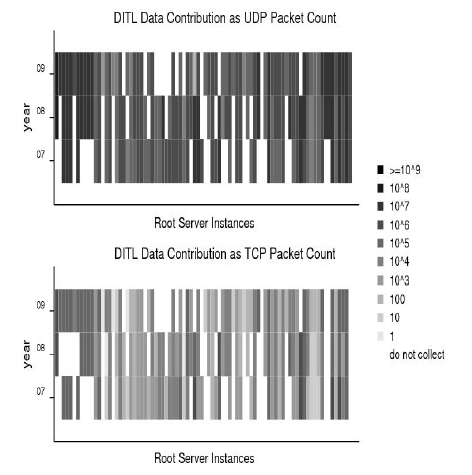
3 Trends in DNS workload characteristics
To discover the continental distribution of the clients of each root instances measured, we mapped the client IP addresses to their geographic location (continent) using NetAcuity [2]; the location of the root server instances is available at www.root-servers.org [1]. Not surprisingly, the 3 unicast root servers observed had worldwide usage, i.e., clients from all over the globe. Fifteen (15) out of the 19 observed global anycast instances also had globally distributed client populations (exceptions were f-pao1, c-mad1, k-delhi, m-icn2). Our observations confirm that anycast is effectively accomplishing its distributive goals, with 42 of the 46 local anycast instances measured serving primarily clients from the continent they are located in (exceptions were f-cdg1, k-frankfurt, k-helsinki, f-sjc13). We suspect that the few unusual client distributions results from particular BGP routing policies, as reported in Liu et al.[13] and Gibbard [10].
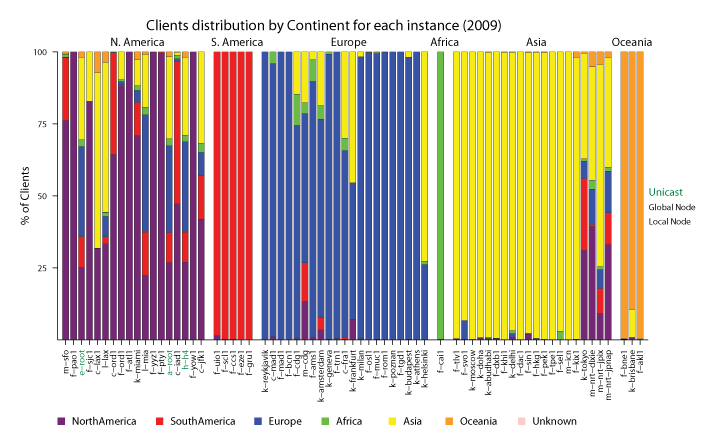
Figure 2: The geographic distribution of clients querying the root server
instances participating in the DITL 2009 (colored according to their continental location). The root server instances are sorted by geographic longitude. Different font styles indicate unicast (green), global anycast (black, bold) and local anycast nodes (black, italic). The figure shows that anycast achieves its goal of localizing traffic, with 42 out of 46 local anycast instances indeed
serving primarily clients from the same continent.
|
|
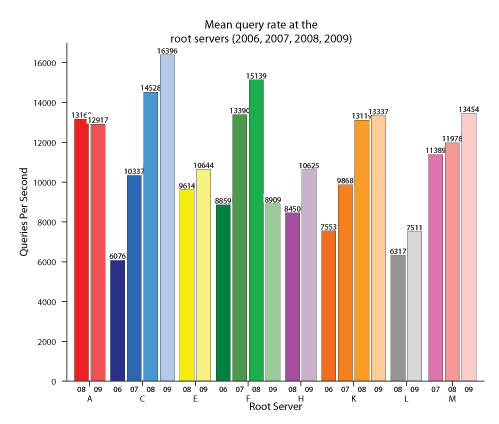
Figure 3: Mean query rate over IPv4 at the root servers participating in DITL from 2006 to 2009. Bars represent average query rates on eight root servers over the four years. The table presents the annual growth rate at participating root servers since 2007. The outlying (41%) negative growth rate for F-root is due to a measurement failure at (and thus no data from) a global F-root (F-SFO) node in 2009.
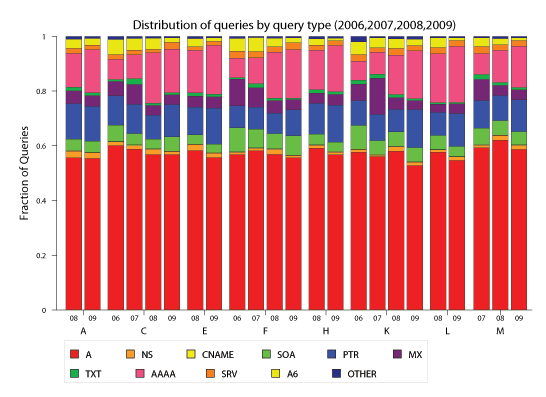
Figure 4: DITL distribution of IPv4 UDP queries by types from 2007 to 2009. IPv6-related
developments caused two notable shifts in 2008: a significant increase in
AAAA queries due to the addition of IPv6 glue records to root servers,
and a noticeable decrease in A6 queries due to their deprecation.
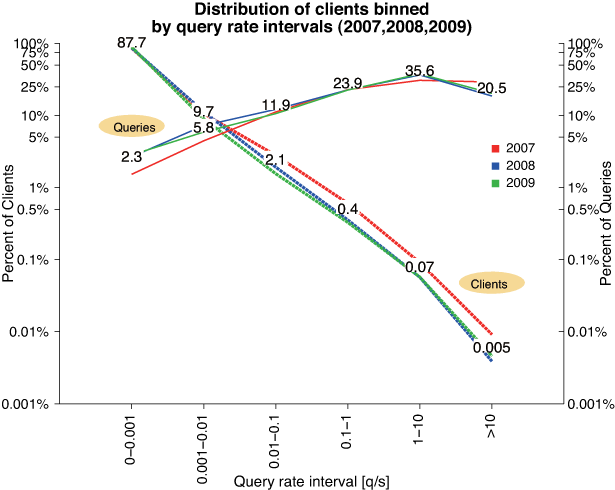
Figure 5: Distribution of clients and queries as a function of
mean IPv4 query rate order of magnitude for last three years of DITL
data sets (y-axes log scale), showing the persistence of
heavy-hitters, i.e. a few clients (in two rightmost bins) account
for more than 50% of observed traffic. The numbers on the lines are
the percentages of queries (upward lines) and clients represented
by each bin for DITL 2009 (24-hour) data.
| Rate interval | Number of clients | Number of queries | Number of valid queries |
| < 0.001 | 602 K | 23 M ( 2.7%) | 8,088 K (47.9%) |
| 0.001-0.01 | 72 K | 49 M ( 5.7%) | 5,446 K (32.3%) |
| 0.01-0.1 | 14 K | 79 M ( 9.2%) | 2,343 K (13.9%) |
| 0.1-1 | 3 K | 165 M (19.3%) | 770 K ( 4.6%) |
| 1-10 | 565 | 324 M (37.8%) | 206 K ( 1.2%) |
| > 10 | 71 | 216 M (25.2%) | 32 K ( 0.2%) |
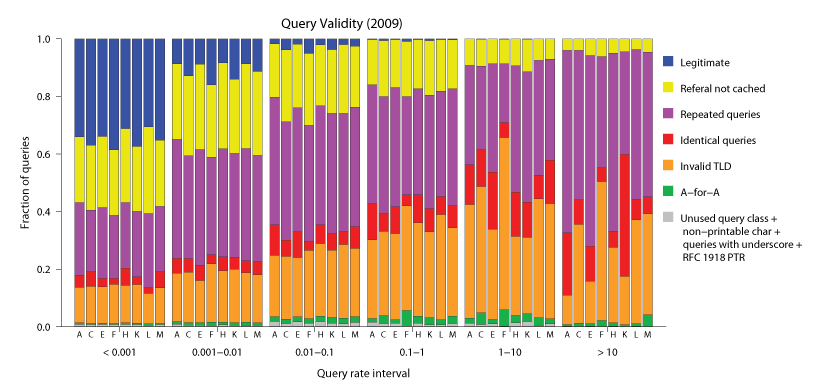
Figure 6: Query validity as a function of query rate (2009) of the reduced datasets (queries from a random 10% sample of clients)
| Clients | % of clients | #Pollution/#Total | % of queries |
| Top 4000 | 0.07% | 4,958M/4,964M=99.9% | 61.39% |
| Top 4000-8000 | 0.07% | 760M/ 762M=99.7% | 9.42% |
| Top 8000-32000 | 0.41% | 1,071M/1,080M=99.2% | 13.36% |
| Top 32000 | 0.55% | 6,790M/6,803M=99.8% | 84.13% |
| All clients | 100.00% | #Total queries: 8,086M | 100.00% |
Table 2: Pollution and total queries of the busiest DITL2009 clients
4 Security-related attributes of DNS clients
We next explore two client attributes related to DNS security and integrity.4.1 Source Port Randomness
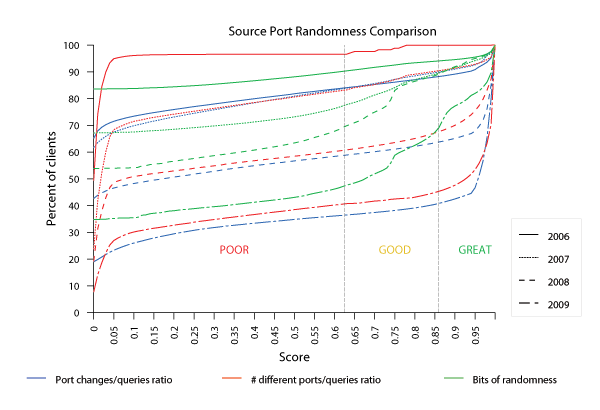
Figure 7: CDFs of Source Port Randomness scores across four years of DITL data.
Scores < 0.62 are classified as Poor, scores in [0.62, 0.86]
as Good and scores > 0.86 as Great. DNS source port
randomness has increased significantly in the last 4 years, with the
biggest jump between 2008 and 2009, likely in response to Kaminksy's
demonstration of the effectiveness of port-guessing to poison DNS
caches [17].
4.2 DNSSEC capability
Although source-port randomization can mitigate the DNS cache poisoning vulnerability inherent in the protocol, it cannot completely prevent hijacking. The longer-term solution proposed for this vulnerability is the IETF-developed DNS Security extensions (DNSSEC) [3] architecture and associated protocols, in development for over a decade but only recently seeing low levels of deployment [19]. DNSSEC adds five new resource record (RR) types: Delegation signer (DS), DNSSEC Signature (RRSIG), Next-Secure record NSEC and NSEC3), and DNSSEC key request (DNSKEY). DNSSEC also adds two new DNS header flags: Checking Disabled (CD) and Authenticated Data (AD). The protocol extensions support signing zone files and responses to queries with cryptographic keys. Because the architecture assumes a single anchor of trust at the root of the naming hierarchy, pervasive DNSSEC deployment is blocked on cryptographically signing the root zone. Due to the distributed and somewhat convoluted nature of control over the root zone, this development has lagged expectations, but after considerable pressure and growing recognition of the potential cost of DNS vulnerabilities to the global economy, the U.S. government, ICANN, and Verisign are collaborating to get the DNS root signed by 2010. A few countries, including Sweden and Brazil, have signed their own ccTLD's in spite of the root not being signed yet, which has put additional pressure on those responsible for signing the root.
|
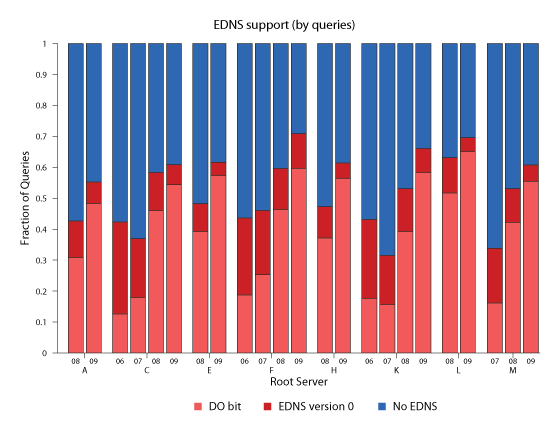
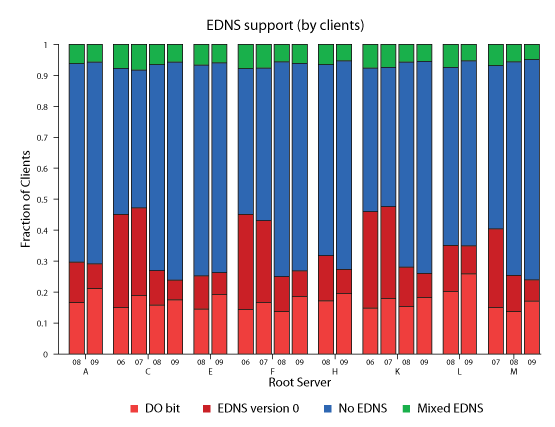 Figure 9: Decrease in EDNS Support measured by clients. In contrast to the query evolution, the fraction of EDNS enabled clients has dropped since 2007. Worse news for DNSSEC, in 2009 only around 60% of the observed EDNS clients were DO enabled, i.e., DNSSEC-capable. |
Due to the way DNSSEC works, clients will not normally issue queries for DNSSEC record types; rather, these records are automatically included in responses to normal query types, such as A, PTR, and MX. Rather than count queries from the set of DNSSEC types, we explore two other indicators of DNSSEC capability across the client population. First we analyse the presence of EDNS support, a DNS extension that allows longer responses, required to implement DNSSEC. We also know that if an EDNS-capable query has its DO bit set, the sending client is DNSSEC-capable. By checking the presence and value of the OPT RR pointer, we classify queries and clients into three groups: (i) no EDNS; (ii) EDNS version 0 (EDNS0) without DO bit set; (iii) and EDNS0 with DO bit. A fourth type of client is mixed, i.e. an IP address that sources some, but not all queries with EDNS support. Figure 8 shows clear growth in EDNS support as measured by queries, particularly from 2007 to 2008. Even better news, over 90% of the observed EDNS-capable queries were DO-enabled in 2009. This high level of support for DNSSEC seemed like good news, until we looked at EDNS support in terms of client IP addresses. Figure 9 shows that the fraction of the EDNS-capable clients has actually decreased over the last several years, by almost 20%! In 2009, fewer than 30% clients supported EDNS, and of those only around 60% included DO bits indicating actual DNSSEC capability.
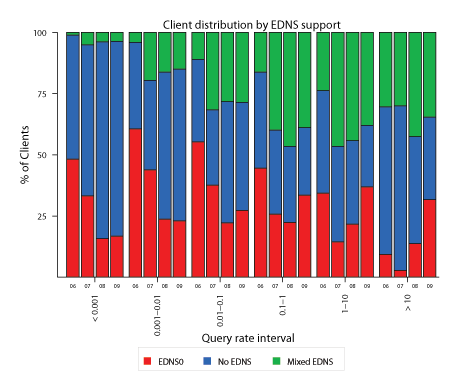
Figure 10: Plotting EDNS support vs. query rate reveals that EDNS support is increasing for busy clients, who mainly generate pollution, but has declined substantially for low frequency (typical) clients.
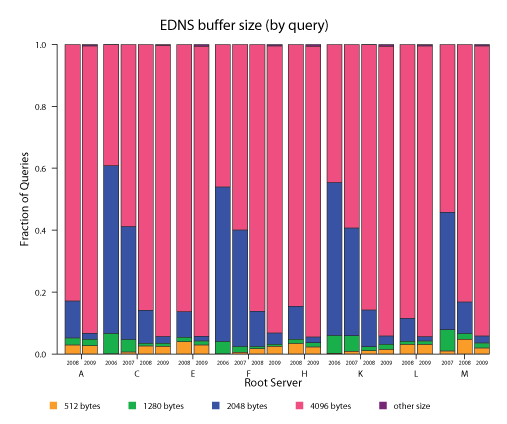
Figure 11: Another capability provided by EDNS is signaling of UDP buffer
sizes. For the queries with EDNS support, we analyze the buffer size
announced. An increase from 50% to 90% in the largest size can be
observed from 2006 to 2009.
5 A first look at DNS IPv6 data
Proposed as a solution for IPv4 address exhaustion, IPv6 supports a vastly larger number of endpoint addresses than IPv4, although like DNSSEC its deployment has languished. As of November 2009, eight of the thirteen root servers have been assigned IPv6 addresses [1]. The DITL 2009 datasets are the first with significant (but still pretty inconsistent) IPv6 data collection, from four root servers. Table 3 shows IPv6 statistics for the one instance of K-root (in Amsterdam) that captured IPv6 data, without huge data gaps in the collection, for the last three years. Both the IPv6 query count and unique client count are much lower than for IPv4, although growth in both IPv6 queries and clients is evident. Geolocation of DITL 2009 clients reveals that at least 57.9% of the IPv6 clients querying this global root instance are from Europe [16], not surprising since this instance is in Europe, where IPv6 has had significant institutional support. The proportion of legitimate IPv6 queries (vs. pollution) is 60%, far higher than for IPv4, likely related to its extremely low deployment [4,11].| 2007 | 2008 | 2009 | ||||
| IPv4 | IPv6 | IPv4 | IPv6 | IPv4 | IPv6 | |
| Query Count | 248 M | 39 K | 170 M | 8.21 M | 277.56 M | 9.96 M |
| Unique Clients | 392 K | 48 | 340 K | 6.17 K | 711 K | 9 K |
Table 3: IPv4 vs. IPv6 traffic on the K-AMS-IX root instance over three DITL years
6 Lessons learned
The Domain Name System (DNS) provides critical infrastructure services necessary for proper operation of the Internet. Despite the essential nature of the DNS, long-term research and analysis in support of its performance, stability, and security is extremely sparse. Indeed, the biggest concern with the imminent changes to the DNS root zone (DNSSEC, new TLDs, and IPv6) is the lack of data with which to evaluate our preparedness, performance, or problems before and throughout the transitions. The DITL project is now four years old, with more participants and types of data each year across many strategic links around the globe. In this paper we focused on a limited slice - the most detailed characterization of traffic to as many DNS root servers possible, seeking macroscopic insights to illuminate the impending architectural changes to the root zone. We validated previous results on the extraordinary high levels of pollution at the root nameservers, which continues to constitute the vast majority of observed queries to the roots. We presented new results on security-related attributes of the client population: an increase in the prevalence of DNS source port randomization, and a surprising decreasing trend in the fraction of DNSSEC-capable clients, which serve as a motivating if disquieting baseline for the impending transition to DNSSEC. From a larger perspective, we have gained insights and experience from these global trace collection experiments, which inspire recommended improvements to future measurements that will help optimize the quality and integrity of data in support of answering critical questions in the evolving Internet landscape. We categorize our lessons into three categories: data collection, data management, and data analysis.- Lessons in Data Collection
- Data collection is hard. Radically distributed Internet data collection across every variety of administrative domain, time zone, and legislative framework around the globe is in "pray that this works" territory. Even though this was our fourth year, we continued to fight clock skew, significant periods of data loss, incorrect command line options, dysfunctional network taps, and other technical issues. Many of these problems we cannot find until we analyze the data. We rely heavily on pcap for packet capture and have largely assumed that it does not drop a significant number of packets during collection. We do not know for certain if, or how many, packets are lost due to overfull buffers or other external reasons. Many of our contributors use network taps or SPAN ports, so it is possible that the server receives packets that our collector does not. Next year we are considering encoding the pcap_stats() output as special "metadata" packets at the end of each file. For future experiments, we also hope to pursue additional active measurements to improve data integrity and support deeper exploration of questions, including sending timestamp probes to root server instances during collection interval to test for clock skew, fingerprinting heavy hitter clients for additional information, and probing to assess extent of DNSSEC support and IPv6 deployment of root server clients. We recommend community workshops to help formulate questions to guide others in conducting potentially broader "Day-in-the-Life" global trace collection experiments [6].
- Lessons in Data Management
- As DITL grows in number and type of participants, it also grows in its diversity of data "formatting". Before any analysis can begin, we spend months fixing and normalizing the large data set. This curation includes: converting from one type of compression (lzop) to another (gzip), accounting for skewed clocks, filling in gaps of missing data from other capture sources5, ensuring packet timestamps are strictly increasing, ensuring pcap files fall on consistent boundaries and are of a manageable size, removing packets from unwanted sources6, separating data from two sources that are mixed together7, removing duplicate data8, stripping VLAN tags, giving the pcap files a consistent data link type, removing bogus entries from truncated or corrupt pcap files. Next, we merge and split pcap files again to facilitate subsequent analysis. The establishment of DNS-OARC also broke new (although not yet completely arable) ground for disclosure control models for privacy-protective data sharing. These contributions have already transformed the state of DNS research and data-sharing, and if sustained and extended, they promise to dramatically improve the quality of the lens with which we view the Internet as a whole. But methodologies for curating, indexing, and promoting use of data could always use additional evaluation and improvement. Dealing with extremely large and privacy-sensitive data sets remotely is always a technical as well as policy challenge.
- Lessons in Data Analysis
- We need to increase the automatic processing of basic statistics (query rate and type, topological coverage, geographic characteristics) to facilitate overview of traces across years. We also need to extend our tools to further analyze IPv6, DNSSEC, and non-root server traces to promote understanding of and preparation for the evolution of the DNS.
References
- [1]
- List of root servers. http://www.root-servers.org/ (accessed 2009.11.20).
- [2]
- NetAcuity. http://www.digital-element.net (accessed 2009.11.20).
- [3]
- R. Arends, R. Austein, M. Larson, D. Massey, and S. Rose. DNS Security Introduction and Requirements. RFC 4033, 2005.
- [4]
- CAIDA. Visualizing IPv6 AS-level Internet Topology, 2008. https://www.caida.org/research/ topology/as_core_network/2008/ipv6 (2009.11.20).
- [5]
- CAIDA and DNS-OARC. A Report on DITL data gathering Jan 9-10th 2007. https://www.caida.org/projects/ditl/summary-2007-01/ (accessed 2009.11.20).
- [6]
- CAIDA/WIDE. What researchers would like to learn from the ditl project, 2008. https://www.caida.org/projects/ditl/questions/ (accessed 2009.11.20).
- [7]
- S. Castro, D. Wessels, M. Fomenkov, and k. claffy. A Day at the Root of the Internet. In ACM SIGCOMM Computer Communications Review (CCR), 2008.
- [8]
- N. R. Council. Looking over the Fence: A Neighbor's View of Networking Research. National Academies Press, 2001.
- [9]
- DNS-OARC. DNS-DITL 2009 participants. https://www.dns-oarc.net/oarc/data/ditl/2009 (2009.11.20).
- [10]
- S. Gibbard. Observations on Anycast Topology and Performance, 2007. http://www.pch.net/resources/papers/anycast-performance/anycast-performance-v10.pdf (2009.11.20).
- [11]
- E. Karpilovsky, A. Gerber, D. Pei, J. Rexford, and A. Shaikh. Quantifying the Extent of IPv6 Deployment. In Passive and Active Measurement Conference (PAM) '09, Seoul, Korea, 2009.
- [12]
- M. Larson and P. Barber. Observed DNS Resolution Misbehavior. RFC 4697, 2006.
- [13]
- Z. Liu, B. Huffaker, N. Brownlee, and kimberly claffy. Two Days in the Life of the DNS Anycast Root Servers. In Passive and Active Measurement Conference (PAM) '07, pages 125-134, Louvain-la-Neuve, Belgium, 2007.
- [14]
- P. Mockapetris. Domain names - implementation and specification. RFC 1035 (Standard), 1987.
- [15]
- Y. Rekhter, B. Moskowitz, D. Karrenberg, G. J. de Groot, and E. Lear. Address Allocation for Private Internets. RFC 1918, 1996.
- [16]
- Team Cymru. Ip to asn mapping. http://www.team-cymru.org/Services/ip-to-asn.html (accessed 2009.11.20).
- [17]
- US-CERT. Vulnerability note vu#800113: Multiple dns implementations vulnerable to cache poisonings. http://www.kb.cert.org/vuls/id/800113 (2009.11.20.
- [18]
- P. Vixie. Extension Mechanisms for DNS (EDNS0). RFC 2671, 1999.
- [19]
- P. Vixie. Reasons for deploying DNSSEC, 2008. http://www.dnssec.net/why-deploy-dnssec (2009.11.20).
- [20]
- P. Watson. Slipping in the Window: TCP Reset attacks, 2004. http://osvdb.org/ref/04/04030-SlippingInTheWindow_v1.0.doc (2009.11.20).
- [21]
- D. Wessels. DNS port randomness test. https://www.dns-oarc.net/oarc/services/dnsentropy (2009.11.20).
- [22]
- D. Wessels. Is your caching resolver polluting the internet? ACM SIGCOMM Workshop on Network Troubleshooting (Netts) '04, 2004.
- [23]
- D. Wessels and M. Fomenkov. Wow, that's a lot of packets. In Passive and Active Measurement Workshop (PAM) '02, Fort Collins, USA, 2002.