

Internet Measurement Data Catalog (IMDC) Specification
Working draft. November 2004.
IMDC goals
- facilitate searching for and sharing of data among researchers
- bridge the gap between Internet models and real measurement data
- promote the reproducibility of network analysis results
CAIDA is designing an Internet Measurement Data Catalog (IMDC) to organize the heterogeneous datasets (both publicly accessible and restricted usage) into a database that researchers can query to find relevant data to support their work. The IMDC includes annotation capabilities for users so that bugs, novel features, and other information about datasets can be shared by investigators with experience in analyzing a particular dataset. In addition to providing the fodder for new inquiries, the IMDC will also support robust science by documenting exactly the data used in a study and enabling others to reproduce published results.
Main features of IMDC
- IMDC helps users to find the data.
-
IMDC contains only "data about data" (i.e., meta-data), but does not actually
store copies of the datasets*. Description of data
includes Acceptable Use Policy information and access instructions.
* - similar to a mail order catalog that is distinct from a warehouse - The IMDC allows both guest browsing and/or login accounts. Only users with accounts can contribute to the IMDC.
- The records in the database are "user-annotatable". Annotations are displayed with the records and can be searched. To add annotations, users can choose from a standard set or create their own.
- Objects in the database have "smart IDs" for citations and references.
- We enable grouping of the database objects together on a logical level. Users can organize the objects of interest into a Functional Group, or into a Study (if there is a publication based on this subset of data).
- We provide an API to automate cataloging large data sets and a web-based GUI for single item input.
The focus of IMDC is on providing reliable and valuable information, being convenient to use, and accommodating the diversity of existing and future Internet data sets.
The objects of IMDC
Fields common for all objects in the database are: creator (of this object); contributor (actually puts the objects into database); creation time; modification time.The main types of objects in the database are:
- Data Descriptor (DD)
- the central conceptual object (atomic entity) of the data catalog. A
data descriptor represents a single file containing data that resides on a
computer somewhere in the world. A single data descriptor is used to
reference all copies of the data item, even copies on disparate computers at
different sites.
DD fields: name; description - long, short; URL; keywords; file size; format; location - geographic, net, logistic; platform; time period - start, end, time zone offset, time zone name; creation process*; MD5 hash (to detect duplicates, to check for corruption).
* - The creation process will be a text field until we gain better understanding of what people might want to put here. It may indicate that data was derived from other data. - Format Descriptor (FD)
- points to information about file formats.
FD fields: name, description, keywords, package or data format, type (ASCII/binary/mixed), file suffixes. - Package Descriptor (PD)
- physical grouping of one or more data files, can be thought of as a
downloadable unit. A package may have multiple data files, and a data file may
be in multiple packages.
PD fields: name, description, keywords, file size, format ID, MD5 hash, linkage to contained DD/PD via a path. - Location Descriptor (LD)
- tells how to actually fetch some data. Packages may be available
from multiple (mirror) locations. Some packages may be downloaded immediately,
while others may require authorization by the data owner.
LD fields: download URL, download procedure (includes AUPs), geographic location of server. - Contact Descriptor (CD)
- human component of the database: data creators, data
contributors, and users.
CD fields: login, password, name, description (long, short, URL), email (hideable), phone (hideable), address (hideable), country (hideable), organization, research interests. - Tool and ToolSet Descriptors (TD)
- what tools are available to conduct measurements, what tools were
used to generate data, versions information.
TD fields: name, description, keywords, release date, OS. We will finalize the fields after getting some experience with usage. Notes and bugs will be in annotations. - Collections: Functional Group and Study Descriptors (FGD, SD)
- Collections are logical groupings of data with a
specific purpose. Such groupings may not exist physically, but they could be
very important for others to use. In particular, Study Descriptor keeps track
of data and results used in a particular publication (but is not meant to
replace/overtake citeseer).
SD fields: name, description, keywords, linkage to DDs, TDs, linkage to StudyWriteup (i.e. actual text of publication). - Annotations
- include all additional information about a given object in the
database and let other people know about important findings in the data.
We will determine the policy allowing users to add annotations to the database.
Annotations dictionary: key name (e.g. hierarchical namespace,
FORMAT-pcap-snaplen), description, value type, position type (time range, all,
string). We will standardize certain annotations further when widely accepted.
Annotation fields: dictionary key, "object" of annotation (DD, PD, LD), value, position (e.g. time).
- All comments are annotations.
- Tool-related 'bugs' and 'caveats' are annotations.
- Default order of annotations is by date.
- Annotations will be sortable.
- Automatic annotations might be possible (i.e. number of packets in a trace file).
- Specifics of Data Formats are defined through annotations .
The structure of IMDC
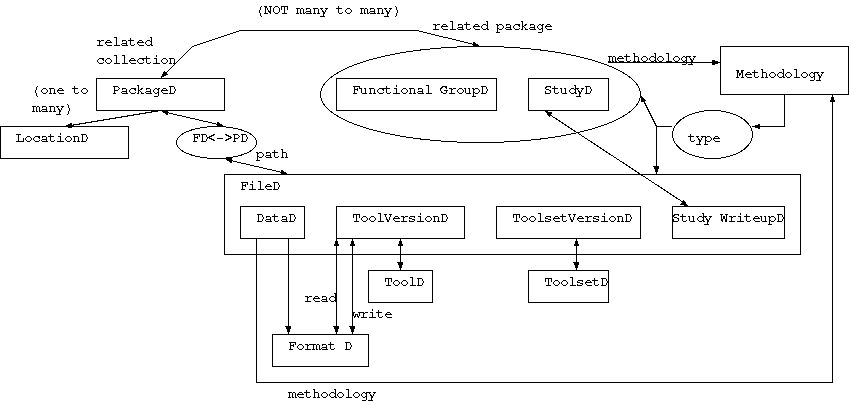
The Figure illustrates the overall structure of the IMDC and relationships between its main parts.
IMDC implementation order
- Phase 1: Data, Formats, Packages and Locations - close to completion
- Phase 2: Annotations - in progress
- Phase 3: Collections
- Phase 4: Tools, Toolsets, and Methodologies