

The contents of this legacy page are no longer maintained nor supported, and are made available only for historical purposes.
Internet Atlas Gallery
Layout Showing the Major ISPs
Bill Cheswick, Bell Labs and Hal Burch, CMULucent Technologies Bell Labs Innovations
Carnegie Mellon University (CMU) Computer Science Dept.
URL: https://www.bell-labs.com/about/history/#gref
| Visualization Thumbnail | About the Data | ||||
|---|---|---|---|---|---|
 |
|
||||
| Full-Size Visualization | Back |
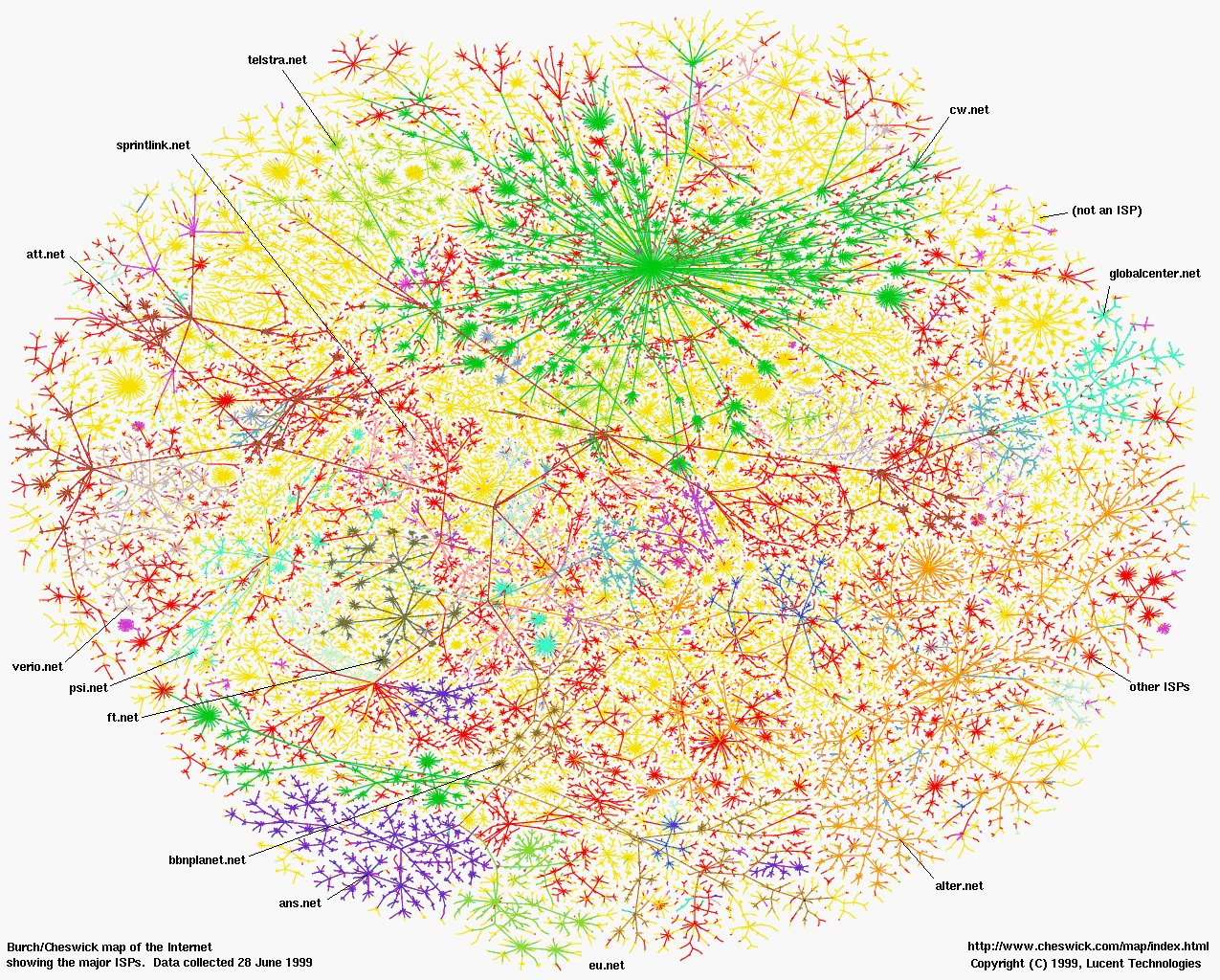{kind=link}