

CAIDA's Internet Topology Data Comparison
This document was later published as a CAIDA technical report in May 2012.
Internet Topology Data Comparison
1. Introduction
Topology maps of the Internet are indispensable for characterizing this critical infrastructure and understanding its properties, dynamics, and evolution. They are also vital for realistic modeling, simulation, and analysis of Internet infrastructure and other large-scale complex networks. These maps can be constructed for different layers (or granularities), e.g., fiber, IP address, router, Points-of-Presence (PoPs), autonomous system (AS), ISP/organization. Router-level and PoP-level topology maps can powerfully inform and calibrate vulnerability assessments. ISP-level topologies, sometimes called AS-level or interdomain routing topologies (although an ISP may own multiple ASes so an AS-level graph is a slightly finer granularity) provide insights into technical, economic, policy, and security needs of the largely unregulated peering ecosystem.
Over the last decade, many studies have focused on the structure of observable Internet topologies [FFF99, TGJSW02, BT02, JRT04, GP04, ZM04a] including considerable controversy over the quality of data and associated inferences [CCGJSW02, LAWD04, ZM04b]. Substantially different views of the Internet result from different methods of measuring topology. Relating particulars of measurements to artifacts and specifics of collected data is crucial for objective evaluation of the scope and the validity of the resulting Internet maps. In our 2006 study [MKFHDCV06], we compared AS topology graphs generated from three different data sources: traceroute (using skitter, CAIDA's previous active measurement infrastructure), BGP (Routeviews), and IRR data (RIPE's WHOIS registry). Here we extend the scope of this comparative analysis to include two additional types of graphs (IP-interface and router level graphs) and five additional data sources (RIPE-RIS, Ark-IPv4-traceroute, iPlane, DIMES, and IRL). We provide what we believe is the most comprehensive study thus far comparing and interpreting structural characteristics of topologies inferred from the best available data sources. We hope the resulting comparative analysis facilitates more informed selection of topology datasets to support specific research or analysis needs.
We organize this report as follows. In Section 2 we describe our data sources, in Section 3 we define the structural topology metrics we use for graph comparison. Section 4 discusses background and methodology for how we process the data to derive corresponding Internet topology graphs at three granularities: IP, router, and AS. Section 5 presents our comparative analaysis framed around the metrics described in Section 3. Section 6 summarizes and concludes the report. and compare structural topological metrics of the resulting graphs and recommendations.
2. Data sources
| graph level | vantage point | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| date | interval | type | IP | Router | AS | collectors | ASes | countries | |
| DIMES | 2011.04.04 - 2011.04.17 | 14 days | traceroute | X | X | 947 | |||
| iPlane | 2011.04.06 - 2011.04.20 | 15 days | traceroute | X | X | X | 251* | 190 | 40 |
| Ark IPv4 All Prefix /24 | 2011.04.01 - 2011.04.15 | 15 days | traceroute | X | X | X | 54 | 54 | 29 |
| RouteViews2 | 2011.01.16 - 2011.01.20 | 4 days | BGP | X | 1 | 33 | 11 | ||
| BGP Full | 2011.01.16 - 2011.01.20 | 4 days | BGP | X | 19 | 336 | 21 | ||
| IRL | 2011.04.01 - 2011.04.15 | 15 days | BGP | X | N/A** | N/A** | N/A** | ||
| RIPE WHOIS | 2009.04.20 - 2011.04.20 | 2 years | IRR | X | 1 | 20,905 | 183 | ||
2.1 - Traceroute Data
Underpinning many Internet topology studies are data sets collected by traceroute-based measurements. By sending probe packets to the destination, traceroute [TLGAC] methods capture a sequence of interfaces along the forward path from the source to a given destination. The most prevalent probing technique uses ICMP packets, although UDP- or TCP-based probing is also used [LHH08].
Per the IP protocol standard, before forwarding a packet, each router along the way decrements the Time To Live (TTL) field in the packet's header. If the field is zero, the router drops the packet and sends a time-exceeded response to the source IP address in the packet [RFC792]. Traceroute probing methodologies infer the IP-level forward path through the network by sending a series of packets to the same final destination, each with incrementing TTL values, and recording the addresses of the routers along the way that return ICMP time-exceeded messages. There is some non-standard variation in the interface used as the source IP addresses in these ICMP response packets (sometimes it is the IP address on the outgoing interface for the return path rather than the interface on the forward path), but it is always an IP address on the router where the TTL expired. Executing traceroute probing from multiple vantage points to multiple destinations reveals a multitude of IP interfaces and links between them. An IP-interface or IP-level graph results from superimposing the results of traceroute measurements across many vantage points.
In order to construct a more realistic map of actual physical devices (routers) from this raw traceroute data, we must estimate which IP addresses in the traceroute paths belong to the same router, a process known as IP address alias resolution. A router by definition has at least two interfaces, with Internet core routers having possibly hundreds of interfaces. The process of alias resolution yields an approximate router-level topology. (See Section 4.2.1 and 4.2.2.)
One can also create AS-level graphs from traceroute-derived IP-level data. The first step in this process is mapping IP addresses to ASes as follows. Each IP address belongs to an address prefix that is originally announced by an independent routing entity in the global routing system, called an Autonomous System (AS). Converting IP-level data to an AS-level graph requires collecting the origin AS for each prefix from BGP data, annotating each IP address with its origin AS, and using these annotations to infer AS links corresponding to each traceroute-observed IP link. Alternatively, one can start with a router-level topology derived through alias resolution, annotate each router with the AS that owns it (for example, using heuristics we described in PAM2010 [HDFC10]), and infer AS links corresponding to each link in the router-level topology. We describe AS graph construction in Section 4.4 and compare the resulting graph characteristics in Section 5.
For this study we used traceroute data from three sources (see Table 1): DIMES, iPlane, and Ark IPv4 All Prefix /24. DIMES is a distributed scientific research project run by Tel Aviv University. Traceroute measurements are executed in parallel by volunteers who have deployed the netDIMES measurement software on their personal computers. (1065 vantage points shown in Table 1, although we could not find out how many vantage points were active in the sub-interval we compared). iPlane is a topology collection research project developed by the University of Washington, and operated on PlanetLab [PL], a global network of academic research servers (during the interval we studied, there were 251 vantage points with 517 monitors, most vantage points have multiple monitors). iPlane constructs an annotated map of Internet topology and predicts end-to-end performance by composing measured performance of segments of known Internet paths, particularly in "core" Internet backbones that contain most used paths. Ark IPv4 All Prefix /24 is traceroute data collected by CAIDA's Ark [AMI] measurement infrastructure which, during the period used in this report (April 2011), consisted of 54 dedicated PCs acting as vantage points and controlled by a central server at CAIDA. The Ark monitors attempt to probe a single random address in each routed IPv4 /24 prefix on the Internet, a complete cycle through the routed IPv4 address space taking approximately 48 hours.
2.2 - BGP Data for AS-level topologies
ASes use the Border Gateway Protocol (BGP) [RFC1771] to exchange routing information on the Internet. Each BGP-speaking router maintains a table of IP-prefix-to-AS mappings that designate reachability to ASes by describing a "chain" or path vector of ASes. One can derive an AS-level graph of the Internet directly from this BGP data.
Two repository projects collect and archive BGP routing tables for research: Route Views [UORVP] run by the University of Oregon and the Routing Information Service (RIS) [RIS] collection provided by RIPE NCC [RIPENCCa]. Each peer contributes a BGP table that stores a set of routed IP prefixes and the computed best path from that peer to each prefix.
Our first source of BGP data for this study is the single Route Views server with the largest number of peers, RouteViews2 (with 33 ASes peers). The second source, BGP Full, is a combination of routing tables from 5 Route Views servers and 14 RIPE-NCC RIS servers, that is, all servers available on 1-14 January 2011 (collectors). Creating a BGP-based AS-level graph using the maximum available number of collectors for a given time interval is the same method we use to produce the AS-level graphs underlying our AS-ranking project [ASR]. Our third source of BGP data is UCLA's Internet Research Lab (IRL) [IRL] compilation, which includes BGP data from Route Views, RIPE-NCC RIS, Packet Clearing House, traceroute.org, and the Looking Glass Wiki (http://www.bgp4.net/rs). The IRL documentation does not specify how many sources contributed to the dataset we used.
2.3 - IRR Data
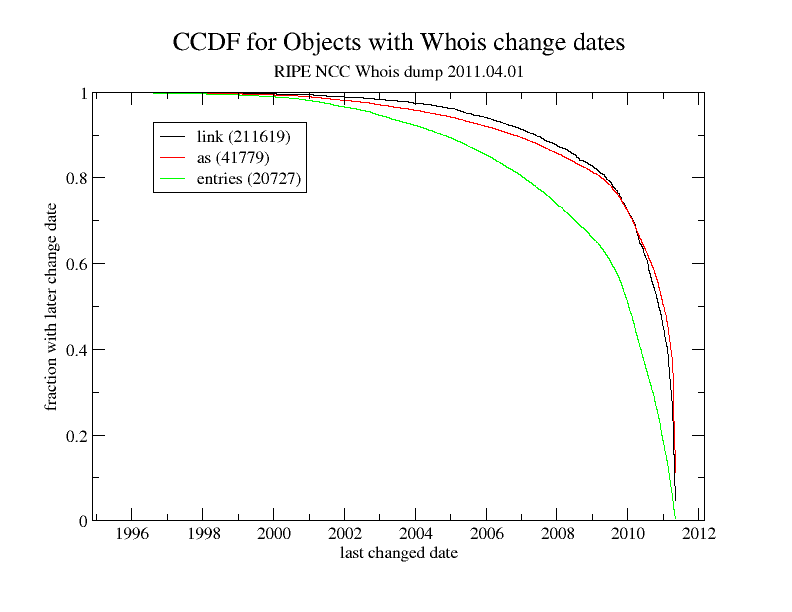 Figure 1. Statistics of entries in the RIPE NCC WHOIS
database. The green line shows the fraction of records that have their
changed field set to a value equal or more recent than the
corresponding x value. The red line is the fraction of ASes
and the black line is the fraction of AS links found in those "changed
after the given date" entries.
Figure 1. Statistics of entries in the RIPE NCC WHOIS
database. The green line shows the fraction of records that have their
changed field set to a value equal or more recent than the
corresponding x value. The red line is the fraction of ASes
and the black line is the fraction of AS links found in those "changed
after the given date" entries.
The Regional Internet Registries (RIR) support query access to their databases of Internet address assignment information via the WHOIS [RFC3912] query and response protocol. The servers providing this query access are called WHOIS servers. Along with the assignment information, at least one RIR database (RIPE) stores voluntarily contributed and (sometimes) maintained routing policy information such as the set of announcements an AS accepts from its neighboring ASes. This information is useful for ISPs in the detection of AS invalid paths (i.e., paths that do not follow the advertised policies of the ASes in the path.) One can also build an AS-level graph of Internet connectivity from these AS links.
In 2004, Siganos and Faloutsos [SF04] analyzed the amount and quality of information available from different RIR databases. They found that the RIPE NCC maintains the largest database with the most accurate topological information. They also found that only 28% of the ASes, almost all of them registered with the RIPE registry, had registered polices that were both internally consistent and consistent with observable Route Views BGP routing tables at the time of their analysis. Therefore, we chose the RIPE NCC WHOIS database as the source of IRR data for an AS-level graph [IRR]. A major problem with this data source is that the WHOIS databases are manually and voluntarily maintained, with no requirement to update registered information. Thus many records are likely obsolete, and we must decide how to filter out stale or unreliable information.
We obtained the RIPE-NCC WHOIS database dump on August 20th, 2011 and used the following approach to retain sufficiently fresh entries. When WHOIS records are updated, their changed field typically shows the date a change was made, although it does not specify if it was the routing information that was updated or another field. Nevertheless, a recent date in the changed field at least means that somebody reviewed the entry then, increasing the likelihood that the routing policy information is still current or they decided the entry was too much work to fix. The green line in Figure 1 shows the fraction of records in RIPE-NCC's WHOIS database that have their changed date field set to a value equal to or greater than the date given on the x-axis. The red line shows the fraction of ASes and the black line shows the fraction of AS links (i.e., listed as peers of the recorded AS) found in those "changed after the given date" entries.
The older the change date, the larger the fraction of ASes and AS links in these ASes' records that changed after this date. The inflection point is at about June 2009, with only 25% of ASes and AS links having change dates in the preceding 13 years vs. 75% in the following two years. Therefore, we retained all entries with changed dates less than two years old as the data source for our analysis, which includes IRR connectivity data for 20,905 ASes (out of more than 39 thousand ASes in total). Since database records only show links from each AS to its immediate neighbors, each AS acts as a vantage point (hence, 20,905 vantage points in Table 1) providing a local view of the network 1-hop away.
3. Topological Metrics
We selected the following four basic statistical characteristics for comparison between available Internet topology graphs. These metrics are the most popular in the networking literature [MKFHDCV06] and also are definitive as [MKFV06] showed that reproducing these metrics is sufficient to capture all essential topological characteristics of Internet AS- and router-level topologies.
Average Node Degree. The two most basic graph properties are the number of nodes n (also referred as graph size) and the number of links m. The ratio of links to nodes defines the average node degree = 2m / n. Average node degree is the coarsest connectivity characteristic of a given topology. Networks with higher are better connected on average and consequently, all other things equal, likely to be more efficient and robust, as well as potentially vulnerable, since diffusion of malware is also more efficient.
Degree Distribution. Let n(k) be the number of nodes of degree k (k-degree nodes). The node degree distribution is the probability that a randomly selected node is k-degree: P(k) = n(k)/n. The degree distribution contains more information about connectivity in a given graph than the average degree; given a specific form of P(k) we can always restore the average degree by = ∑k=1kmax kP(k), where kmax is the maximum node degree in the graph. In this report we analyze and compare the complementary cumulative distribution function (CCDF) of node degree, which shows the fraction of nodes that have a degree equal to or greater than the argument value.
The degree distribution is the most frequently used topology characteristic. Most network researchers agree that the degree distribution P(k) for the AS level graphs of the Internet follows a power law function P(k)=k-γ with exponent γ being close to 2 [FFF99,BT02, JRT04,MKFHDCV06]. Since power law is a highly variable distribution, node degree is an important attribute of an individual node. We check whether this power-law approximation fits our data and report the values of the exponent γ. We use two methods to find the fit: least-squares fitting of the degree CCDF and maximum-likelihood fitting of the degree sequences [CSN09].
Average Neighbor Degree. Let a(i,k) be the average degree of the immediate neighbors of the i-th node of degree k. Then the average neighbor degree for degree k is the average for all nodes i = 1... Ik with degree k: ann(k)= ∑i=1 Ik a(i,k)/n(k). The average neighbor degree is a summary statistic of the joint degree distribution. It shows whether ASes of a given degree preferentially connect to high- or low-degree ASes. In a full mesh graph, ann(k) reaches its maximal possible value n-1. Therefore, for uniform graph comparison we will plot normalized values ann(k)/(n-1).
Clustering. Let nn(k) be the average number of links between the neighbors of k-degree nodes. Local clustering is the ratio of this number to the maximum possible number of such links: C(k) = 2nn(k)/(k-1). If two neighbors of a node connect, then these three nodes together form a triangle (3-cycle). Therefore, by definition, local clustering is the average number of 3-cycles involving k-degree nodes. Mean local clustering is the average of C(k) over all values of node degrees k: = ∑C(k)P(k). Clustering expresses local robustness in the graph: the higher the local clustering of a node, the more interconnected are its neighbors, thus increasing the path diversity locally around the node.
For all three granularity levels of focus (IP, router, AS), we examine how different data sources yield different graph structural characteristics.
4. Constructing Internet topology graphs from the available data
4.1 - IP-level graphs
An Internet Protocol (IP) interface-level graph is constructed by extracting IP links directly from the traceroute output: two IP addresses are inferred to form a link if they were observed adjacent to each other in a traceroute output. The DIMES project does not publish the complete traceroute paths measured by the netDIMES clients, but rather extracts from these measurements a set of such inferred IP links, yielding an IP-level graph we will refer to as DIMES IP. In contrast, iPlane and Ark IPv4 All Prefix /24 data include a complete set of observed IP forward paths. In order to obtain an IP-level graph from these data, a researcher has to parse the raw paths into IP links. Although it is conceptually straightforward to enumerate every pair of adjacent IP addresses in a collected path, the simplicity evaporates in the face of millions of real-world observations. Raw paths may contain non-responsive hops, loops, private [RFC1918] or bogon [TCBL] addresses, and other irregularities. Different methods of handling these anomalies will induce different effects on the resulting topology.
For example, a non-responsive hop appears in a traceroute path when a router forwards packets, but does not generate a time exceeded message when it drops a packet. In this case, the resulting trace will have a gap between two known IP addresses on either side of the non-responding router. In traceroute output these hops are typically represented by an asterisk ("*").
We used the following basic trace processing algorithm to create the Ark IPv4Pref IP and iPlane IP graphs from the Ark All Prefix /24 and iPlane data sets. For each traced path in the data set, we begin with an empty array and fill the array's entries as we process each hop, using the following rules:
- Ignore responses from the destination (the target of the trace).
- If multiple responses are found for the same hop, use the last one.
- At the first repeated IP address, assume a loop and truncate the path to the hop just before the repeated one.
- Treat private addresses as non-responsive.
- Discard IPs with no adjacent hops.
4.2 - Router-level graphs
4.2.1 - Related work on alias resolution techniques
The process of mapping IP addresses to routers is known as alias resolution. A variety of techniques have been developed and implemented for this task. Mercator and Mercator-like techniques [PG98, GT00,IART, SS05] attempt to identify aliases by sending a probe packet to an unused port on an interface and collecting the resulting error messages. Probing one interface and getting this error from a different interface is a strong suggestion that the two interfaces belong to the same router. However, when applied to Internet-scale topologies, this methodology generates a high rate of false positive alias pairs, for example due to middleboxes in the path responding [KHLC11].
Other techniques employ different properties of existing Internet protocols to resolve interfaces into routers. Ally [SMWA04] infers that two addresses are aliases if probe packets sent to them produce responses with increasing but appropriately proximate IP ID values, since the IP ID field increments with each packet sent from the router. RadarGun [BSS08] further refined this technique by looking for similarities in IP ID time series collected from many addresses. Sherry [SKPMAK10] describes iPlane's recent use of the IP prespecified timestamp option to infer aliases. MIDAR, CAIDA's Monotonic ID-Based Alias Resolution tool [KHLC11], expanded on the IP velocity techniques of RadarGun by implementing an extremely precise ID comparison test based on monotonicity rather than proximity, integrating multiple probing methods from multiple vantage points, and employing a novel sliding-window probe scheduling algorithm that increased scalability to the Internet scale of millions of IP addresses.
APAR [GS06] and kapar [Ke10] use sophisticated graph analysis techniques to infer subnets linking routers, and from that, aliases. We briefly mention only the subset of alias resolution techniques related to how the data sets in this study are processed, which is the focus of the next section. A survey of other existing alias resolution techniques and implementations, including utilizing reverse DNS information, record route data, and IGMP (multicast) protocol messages, is available in [Ke10].
4.2.2 - Alias Resolution techniques used in data set comparison
According to their 2005 paper [SS05], DIMES uses a Mercator-like technique [GT00] for alias resolution. Due to the high rate of false positives of this older method, we decided not to use the DIMES-provided alias resolution data in our comparisons.
iPlane implements the following two-phased approach to alias resolution. The first phase uses two methods to generate a list of alias candidate pairs, and the second phase uses two methods to test the merged list of candidate pairs generated from the first phase. The first technique for generating a list of alias candidate pairs is the same Mercator-like approach that DIMES uses, i.e., sending a UDP probe to every interface Rj seen in traceroute probing. If the source address Ri of the response is different from Rj, the pair Ri, Rj is added to the list of candidate pairs. The second technique is similar to the APAR method [GS06]. It examines every pair of consecutive interfaces Rk, Rl observed in traceroutes, introducing the other usable IP address Rp in the same /30 subnet as Rl (and thus likely on a point-to-point link with Rl), and adding (Rk, Rp) to the list of candidate pairs. Given the merged list of candidate pairs from both techniques, the system next tests each candidate pair, again using two methods. The first method is Ally-like [SMWA04]: a host running iPlane sends pairs of ICMP probes to both addresses in the candidate pair and determines whether the responses have proximate IP-ID values and return the same TTL. The second method is to send customized packets toward the candidate interfaces with the option set to collect timestamps. If the order and the values of the timestamps match, iPlane assumes these interfaces are on the same router. Further details of the alias resolution methodology used by iPlane are available in [MIPDAKV06] and [SKPMAK10].
The resulting iPlane alias resolution data show which interfaces are inferred to be on the same router, but links between routers are not included. To create the router links for the iPlane router graph, we started with the iPlane IP graph and used iPlane's router aliases to merge aliased IP nodes and corresponding links into router nodes and links.
To collapse IP addresses in Ark IPv4 All Prefix /24 data into routers, we employed CAIDA's alias resolution tools iffinder [IART], kapar [Ke10], and MIDAR [KHLC11]. Router-level topologies produced from Ark IPv4 All Prefix /24 traceroutes using combinations of the three tools are the core of the Internet Topology Data Kit (ITDK) datasets regularly released by CAIDA [ITDK]. The process of constructing these ITDK topologies involves the following steps. First, kapar breaks the observed IP paths into IP links as described in Section 4.2.3 below. Next, these inferred IP level links become the input for further alias resolution measurements and analysis by MIDAR and iffinder. In addition, kapar can also heuristically infer the set of IP addresses that belong to the same router, and the set of two or more routers on the same "IP link" (either a point-to-point link, or LAN, or shared medium with multiple attached IP addresses). We release both router-level topologies as part of ITDK: a conservatively-inferred MIDAR-iffinder topology (Ark ITDK Rmi) and a more-aggressively inferred MIDAR-iffinder-kapar topology (Ark ITDK Rmik). We elucidate the differences between these topologies in Section 4.3 below.
4.2.3 - kapar processing of IP paths into IP links
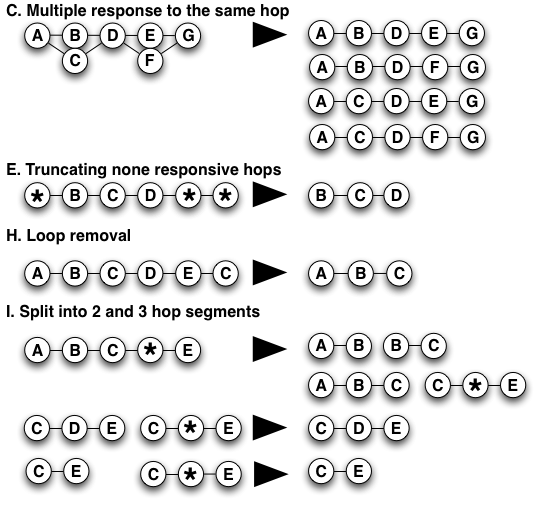
Figure 2. Selected examples of kapar's initial processing of IP paths into segments.
Based on our experience with processing and interpreting traceroute data, we refined the basic approach of extracting IP links from paths described for IP graphs (Section 4.1) to the following two-phase procedure implemented in kapar for constructing router-level graphs.
First phase involves cleaning and splitting IP paths into segments:
- As in the basic IP trace processing described above, ignore responses from the target destination of a trace.
- If there were multiple responses to a single probe at a given hop, truncate the trace before that hop.
- If any hop has multiple responses resulting from multiple probes, consider all combinations to be valid paths (Figure 2C). However, if the number of possible combinatoric paths is >10, discard the trace. (Not yet seen in practice.)
- If the same address occurs at two adjacent hops, treat the first occurrence as a non-responsive hop.
- Truncate leading and trailing non-responsive hops (Figure 2E).
- Treat bogus and private addresses as non-responsive.
- If only 2 hops remain after the above processing, discard the trace.
- If a loop is detected, only keep the part before the loop (Figure 2H). Note that the basic processing applied to construct IP-level graphs would have kept the path A-B-C-D-E, but the kapar approach is more conservative and removes entirely connectivity that forms a loop.
- Split paths into overlapping 2 and 3-hop segments. If a 2-hop or 3-hop segment matches the edge IP addresses of a 3-hop segment containing a non-responsive hop in the middle, discard the 3-hop segment containing the non-responsive hop (Figure 2I).
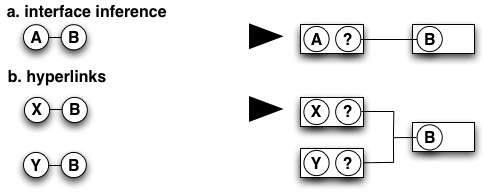
Figure 3. Selected steps of kapar's processing of IP segments into links.
In the second phase, kapar infers IP links from the segments as follows. For each path segment (A, B), it postulates a link between the router (node) R1 containing interface A and the router R2 containing interface B and assumes that, unless node R2 is already linked to node R1, this link connects the interface B on the node R2 and an implied unknown interface ? on the node R1 [A ?] ↔ [B] (Figure 3a).
Hyperlinks ("link clouds") appear when there are multiple non-aliased predecessors to an address (Figure 3b). Unlike traditional links, the hyperlinks represent connectivity between more than two nodes.
4.2.4 - Dealing with non-responsive hops
If there is no path that would resolve a triplet with a non-responsive hop in the middle, then we include the triplet into the final graph assuming a provisional placeholder node between the two known nodes. This data construct allows us to maintain information about the connectivity without knowledge of the intermediate hop. Note that if a known node has more than one placeholder node as its immediate neighbor, then we cannot distinguish whether it is in reality a single non-responsive node or a different non-responsive node for each next hop observed in the traces. 7.8% of nodes (inferred routers) in our ITDK data set have only non-responding hops as neighbor(s). Some of these inferred routers could possibly further collapse into higher-degree routers with additional data that we do not have.
We considered three scenarios for dealing with non-responsive hops (see Figure 4) that trade off accuracy and completeness of the resulting graph. Under the first and most conservative scenario, non-responsive none, we create a clean graph by discarding all links from the known nodes to the non-responsive ones. Such a graph is missing some actual topology. In the second case, non-responsive+1, we assume that all the observed connectivity can be attributed to a single unknown node, and so we count only the first occurrence of a placeholder neighbor toward the degree of a given node. In the third and least conservative case, non-responsive all, we assume that every placeholder neighbor is really a different node and count them all toward the degree of a given node. In other words, the third scenario admits the upper bound of the number of possible nodes represented by the "observed" non-responsive hops.
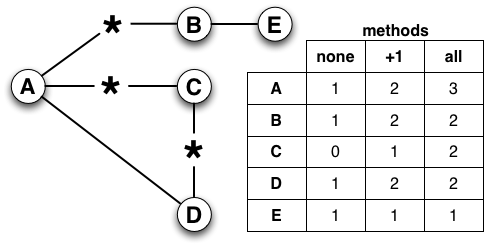
Figure 4. Node degrees resulting from three methods for counting non-responsive hops.
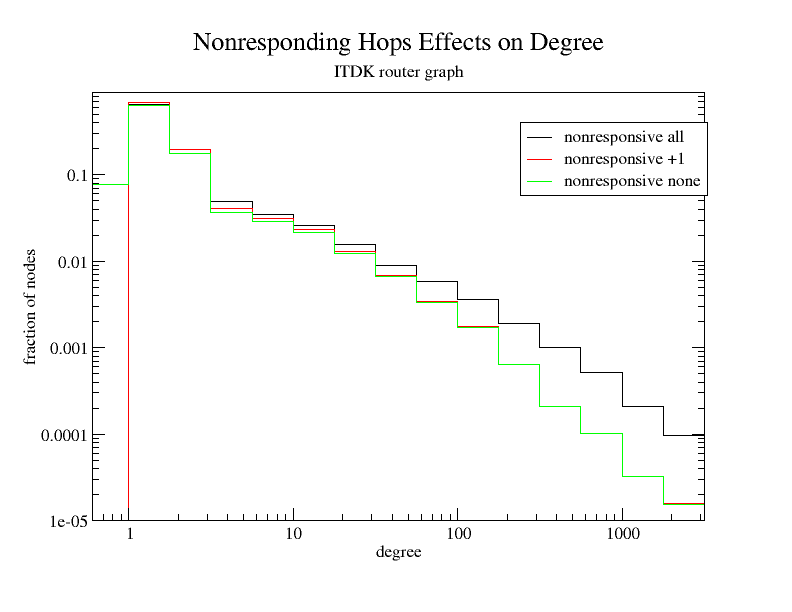 Figure 5. Node degree distributions resulting from different
methods for dealing with non-responsive hops. Differences between
none and +1 are largest for small
degrees. The all method produces an order of magnitude
more nodes with degrees >1000 than other methods.
Figure 5. Node degree distributions resulting from different
methods for dealing with non-responsive hops. Differences between
none and +1 are largest for small
degrees. The all method produces an order of magnitude
more nodes with degrees >1000 than other methods.
To explore the effect these three approaches have on the degree distribution of this resulting graph, we examine the CCDF of the degree distribution (Figure 5). The degrees are binned logarithmically, with 4 bins per decade. All three methods result in power-law degree distributions, with most interfaces -- between 63% and 68% -- having a degree of one. The gap between non-responsive +1 (the red line) and non-responsive none (the green line) shrinks as the degree increases, while the gap between these two and non-responsive all (the black line) increases in each logarithmic bin. In this latter case, when we count all placeholder nodes toward the degree of a given node, the degree distribution shifts rightward since for each node its degree can only increase.
Considering the largest nodes in the non-responsive all graph we found that almost all of them received the majority of their connectivity from non-responsive hops. Therefore, counting all placeholder hops as different interfaces is unlikely the most accurate choice. Using the non-responsive +1 method seems at first to be a reasonable compromise, allowing us to capture some of the ambiguous connectivity. However, by construction placeholder nodes always have a degree of 2 and skew the distributions (toward nodes of degree 2) and averages of any statistical metrics. These nodes also make it difficult to ascertain clustering, since their clustering is completely unknown. For these reasons we selected the non-responsive none methodology to construct router-level graphs from Ark data for this report and discarded the 7.8% of nodes that only had non-responsive neighbors. This conservative method does result in the loss of some connectivity.
4.3 - Comparison of IP- and router- level graphs with the ground truth
Since IP addresses in an IP-level graph represent interfaces on the actual routers, IP-level graphs are an approximation of what we ideally would like which is a map of how each router is connected, identifying (the IP addresses of) as many IP interfaces on each router as possible. In order to evaluate the accuracy of various datasets and methods used to produce these approximations, we compared all IP- and router-level graphs available for this study to a ground truth dataset provided by a Tier 1 ISP for their backbone AS (2420 routers). That ISP gave us a complete listing of the domain names of their core routers and the heuristic they use to map router interfaces into domain names. Using this ground truth dataset, we can evaluate the completeness of the various measurements for this ISP, the accuracy of the router alias resolution, and how closely each experimental dataset captures the degree distribution. Unfortunately, this ground truth dataset does not indicate actual links between the routers, making it impossible to assess the accuracy of clustering or average neighbor degree of the inferred topologies.
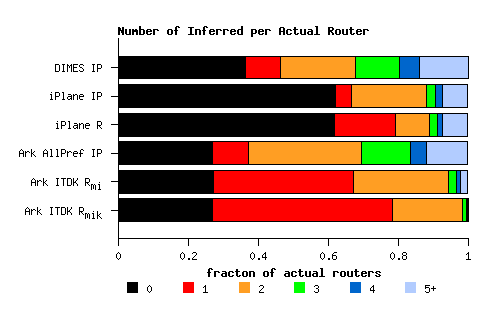 (a) Mapping of actual routers into a given number of inferred routers. |
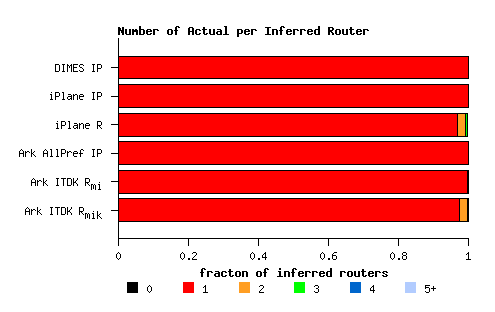 (b) Mapping of inferred routers into a given number of actual routers. |
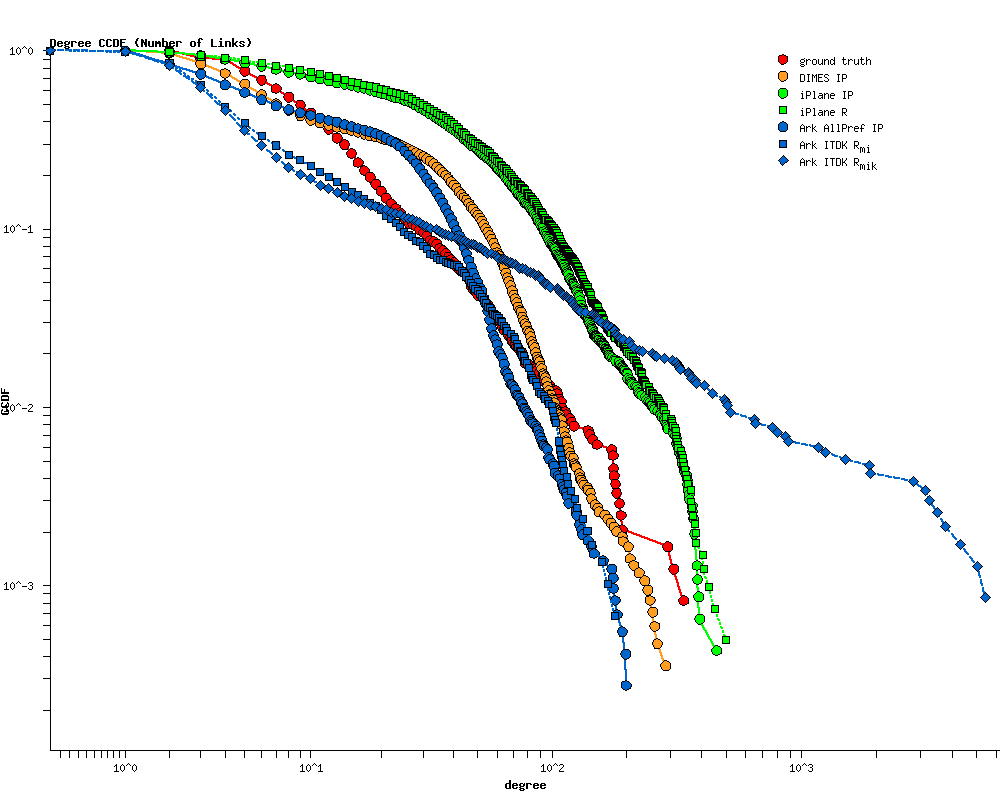 (c) The CCDF of node degrees for each processing method and data source. |
|---|---|---|
| Figure 6. Comparison between a Tier 1 ISPs set of (2420) core routers and the corresponding inferred topologies derived from three traceroute datasets. | ||
Figure 6a illustrates the coverage of each methodology, showing the fraction of real routers that: (i) could not be mapped to any router in the inferred topology (the black segments); (ii) is mapped to a single router (the red segments) - these are the correct answers that we seek to maximize; and (iii) is mapped to 2 or more routers (all other color segments) - the routers that are undercollapsed in the inferred topologies. The black segments are the shortest for the topologies derived from the Ark IPv4 All Prefix /24 dataset, which fails to capture 27% of this ISP's routers. The DIMES dataset misses 37% of the true routers for this ISP, and iPlane is the least complete at 62%. That Ark detected a larger fraction of the real topology's routers is somewhat suprising given that Ark has the fewest vantage points, but each Ark monitor sends a significantly more probes than the other platforms, capturing a larger number of IP addresses. This larger view of the overall topology enables detection of a greater fraction of the ground truth routers.
The red segment of each bar shows the fraction of real routers that correctly had their interfaces mapped to a single router. It does not mean that the dataset captured every interface on a given router, only that all the interfaces captured did map to the same router. IP-level graphs treat every observed IP address as a separate router, which means a real router will be mapped to as many routers as it has IP interfaces. This inference is clearly wrong, as reflected by the short red segments in bars for all of the IP-level graphs in Figure 6a: DIMES IP, iPlane IP, and Ark IPv4Pref IP. The process of resolving IP aliases (i.e., merging interface addresses) into common routers increases the fraction of correct one-to-one mappings. For the iPlane data, the fraction of real routers that map to a single inferred router increases from 4.6% in their IP-level graph to 17.4% in their router-level graph. For the router-level topologies in the Ark-derived ITDK, this fraction rises from 10% to 40% for the MIDAR-iffinder topology and to 51% in the MIDAR-iffinder-kapar topology.
At the same time, alias resolution can overcollapse routers by assigning interfaces from multiple distinct real routers to the same inferred router (i.e., a false positive). Figure 6b illustrates the prevalence of such false inferences for a single backbone ISP (with 2420 routers). Here the red segment of each bar shows the fraction of inferred routers that correctly contain only IP addresses from a single real router. Since IP level graphs always interpret a single IP address as a separate inferred router, for these graphs the red segments are trivially 100% by definition. iPlane's alias resolution process creates falsely inferred routers for 3% of the real routers in this ISP's ground truth data. Alias resolution using MIDAR-iffinder results in a tiny fraction of false inferences (0.2% of the actual routers for this ISP), while MIDAR-iffinder-kapar processing overcollapses 2.6% of the ISP's actual routers. The fractions of false inferences in all router-level topologies seem small, but Figure 6c shows that they may have a dramatic effect on the resulting node degree distributions.
Canonically, a node degree distribution is a histogram of the number of neighbors of each node, but our ground truth data provides only the number of active interfaces on each router, which may not always map one-to-one to the number of neighbors due to hyperlinks (described above). In the case of this ISP, most but not all interfaces are on point-to-point links. So while the actual number of neighbors per node is unknown, the number of links per node we infer in the router-level topology for this ISP is a reasonable approximation to the number of interfaces, which we compare to the number of interfaces listed in the ground truth data.
We first extract the set of routers from the inferred topology with at least one interface matching an interface in the ground truth data and compare (Figure 6c) the CCDFs of the number of links connecting to each such extracted router against the number of interfaces on a router in the ground truth data (the red symbols) as proxies for the CCDFs of node degree distributions. Both iPlane-derived graphs (the green symbols) significantly overestimate the number of routers (in this ISP) with degrees >10: 40% in the ground truth data set vs. 70% and 74% in the iPlane topologies. The DIMES IP (the yellow circles) and the Ark IPv4Pref IP (the blue circles) topologies yield reasonable approximations of the degree distribution for the 60% of the ground truth routers that have degrees <10, but begin to diverge for degrees between 10 and 60, which represents about 37% of routers in the ground truth data. The DIMES IP graph is the closest to the ground truth in the large degrees (>100) range, but this range represents only 1% of the ground truth routers. DIMES' much larger number of edge vantage points will naturally capture a larger number of interfaces entering core routers from the periphery. Both ITDK-derived router-level topologies (the blue diamonds and squares) underestimate the degrees of small degree (<20) nodes, which is 84% of ground truth routers, yet the Ark ITDK Routermi topology that uses only MIDAR-iffinder processing (the blue squares) matches the ground truth perfectly in the range of node degrees between 20 and 100, or 15% of our ground truth routers. In contrast, the MIDAR-iffinder-kapar topology (Ark ITDK Routermik, the blue diamonds) contains unrealistically super-high degree nodes that appear when two (or more) routers are merged into a single super-router: 4.6% of Ark ITDK Routermik routers have degrees >100 vs. only 1.2% of the corresponding ground truth routers. Adding kapar inferences to the MIDAR-iffinder results increases the completeness of alias resolution (cf. Figure 6a), but this additional processing also overcollapses the routers (cf. Figure 6b) skewing the node degree distribution toward unrealistically large degrees. To avoid the false positives and associated distorted statistics, we use the more conservatively-inferred Ark ITDK Routermi topology in the rest of this report. As mentioned in Section 4.2.2, this is one of the two topologies we release as part of each ITDK package.
4.4 - AS-level graphs
AS-level graphs represent the topology of the Internet at the level of Autonomous Systems (ASes), which are approximately network(s) under a single administrative control. ASes are an important abstraction because they are the "unit of routing policy" in the routing system of the global Internet. ASes peer with each other to exchange traffic, and these peering relationships define the high-level global Internet topology. For the purposes of analysis, these peering relationships are represented with an AS graph, where nodes represent ASes and links represent peering relationships. This section focuses on the construction (derivation) of AS-level graphs from three possible data sources: raw traceroute data, BGP (Border Gateway Protocol) inter-AS routing table dumps, and RIPE's WHOIS routing registry database entries (voluntarily maintained by some ISPs to RIPE's Internet Routing Registry or IRR).4.4.1 - Traceroute-based AS-level graphs
A typical starting point for constructing AS-level Internet topologies from traceroute data uses BGP table dumps from the Route Views Project [UORVP] and RIPE-NCC RIS [RIS] to map routable prefixes found in the collected traces to their origin ASes in the global routing system. A small percentage of IP prefixes map to an AS set, i.e., a set of ASes any of which could be announcing the prefix. We leave the origin of those IP prefixes unresolved and discard such AS sets. (The IETF is in the process of deprecating AS sets [KS11].) Some prefixes originate from multiple ASes, in which case we select the AS most frequently seen in the BGP tables as the origin AS. Out of 366,294 prefixes found in Routeviews BGP tables in the first half of April 2011 (the period of Ark data collection used in this report), 2,299 prefixes (0.6%) originated from AS sets, and 18 prefixes (0.005%) had multiple origin ASes.
Once we have a mapping between the IP address space and the AS space, the simplest method of constructing an AS-level graph entails mapping each IP address in the traces to its origin AS, and inferring AS links corresponding to observed IP links. We used this technique to generate the iPlane AS and the Ark IPv4Pref AS AS links files. We also used this method in our previous paper [MKFHDCV06] comparing AS-level Internet topologies. Note that DIMES provides their own set of AS links DIMES AS, which we used directly rather than generating them as we did with iPlane data.
For the Ark ITDK Routermi topology, we examined two methods to create AS-level Internet graphs: router-observed, and router-inferred. In both cases, the first step is to assign router ownership to ASes, we use BGP data to map each IP address on a given router to its origin AS. Whichever AS has the most interface IP addresses assigned to it "owns" the router, or in the case of a tie between two ASes, we assign the router to the AS with the smallest degree. Further details of router-to-AS assignment algorithms are available in our PAM paper [HDFC10].
Router-observed AS links. This method starts with the observed IP interfaces in the path, uses the alias resolution data to map these interfaces to routers, and then uses router-AS assignment data to map these routers to ASes [HDFC10]. This mapping results in an AS path, which we then split into AS links. We call the AS graph derived by this method Ark ITDK ASro.
Router-inferred AS links. This method starts with the ITDK graph, use the same router-AS assignment data as above to map these routers to ASes, resulting in an AS graph, which we then split into AS links. The conceptual distinction between the two methods is that an AS-graph constructed using the router-observed method contains only AS-links that correspond to IP links that were directly "observed" via measurement, while a graph constructed by the router-inferred method also includes links that were not actually output of the measurement process, but can be inferred from the router-level graph. We name this graph Ark ITDK ASri.
Although we excluded the destination addresses when constructing IP- and router-level graphs (since these graphs focus on routers, not edge hosts), we retained these addresses when building AS-level graphs, with the following justification. Although the router just before the destination may be managed by the same AS as the destination, we often see only its provider-facing address in the collected traceroute output. In this case, retaining the destination address provides a way to capture additional AS connectivity AS; dropping the destination addresses would decrease the size of the resulting AS-level graph by 29%.
4.4.2 - BGP-based AS-level graphs
In order to generate an AS-level graph from BGP data, we start with the AS paths found for each prefix and break these AS paths into individual AS links. We discard links that contain private ASes. For the RouteViews2 and BGP Full data sets we collect a RIB on five consecutive days, and extract AS links only from the persistent paths during this period (paths seen in the majority of RIB tables during the interval).
The IRL data set used BGP data from active Route Views, Internet2 [I2ODC], RIPE RIS servers, and some looking glass servers (at bgp4.net), although the IRL documentation was not sufficient to explain exactly which parts of which data resources they were using.
4.4.3 - WHOIS AS-level graph
To derive an AS-level graph from the RIPE WHOIS IRR data, we use the import and export fields that list ASes registered as BGP neighbors of a given AS (represented by its autonomous system number, or aut-num in the IRR record). We create links between the aut-num's AS and the ASes listed in these import and export fields, excluding ASes that only appear as neighbors but do not have their own aut-num lines. Such ASes are external to the database and we cannot correctly estimate their topological properties (e.g., node degree). We also filter out private ASes.
5. Analysis of Internet topology graphs
5.1 - Characteristics of IP- and Router- Level Graphs
| graphs | number of | degree | normalized avg avg neighbor degree |
mean local clustering |
|||
|---|---|---|---|---|---|---|---|
| nodes | edges | avg | max | ||||
| IP-level graphs | |||||||
| Ark IPv4Pref IP | 2,111,019 | 4,073,080 | 3.86 | 4,772 | 5.53e-05 | 0.012 | |
| DIMES IP | 1,543,320 | 4,230,578 | 5.48 | 4,742 | 6.31e-05 | 0.065 | |
| iPlane IP | 233,996 | 1,661,041 | 14.20 | 1,586 | 2.16e-04 | 0.12 | |
| Router-level graphs | |||||||
| Ark ITDK Routermi | 1,633,126 | 2,729,618 | 3.34 | 3,439 | 8.48e-05 | 0.15 | |
| iPlane Router | 218,399 | 1,531,736 | 14.03 | 1,600 | 2.38e-04 | 0.13 | |
Table 2 compares the basic statistics of three IP-level graphs and two router-level graphs. The number of links observed in the IP-level graphs DIMES IP and Ark IPv4Pref IP data are similar, with only 4% more links in DIMES IP, despite having 27% fewer nodes. The iPlane IP graph has only a fraction (~11-15%) as many nodes and 40% as many links as the other two graphs. The smaller size of the iPlane IP graph is consistent with its focus on capturing only the Internet core topology, which also explains its larger average degree. The iPlane IP graph does have a smaller maximum node degree, perhaps because it has so many fewer nodes. The iPlane IP graph has an order of magnitude higher mean local clustering than the Ark IPv4Pref IP graph, although this disparity disappears after alias resolution, at which point the Ark IPv4Pref Routermi graph has only 13% higher mean local clustering than the iPlane Router graph. Our alias resolution process on the Ark IP level graph, Ark IPv4Pref IP, creates a router-level graph Ark ITDK Routermi, reducing the number of nodes by 23% and links by 31%. iPlane IP's alias resolution resulted in the iPlane router graph having only 6.7% fewer nodes and 7.8% fewer links. It appears that the alias resolution methods used by the iPlane project are less aggressive and/or efficient than CAIDA's MIDAR/iffinder/kapar. The relative accuracy of these methods is beyond the scope of this study.
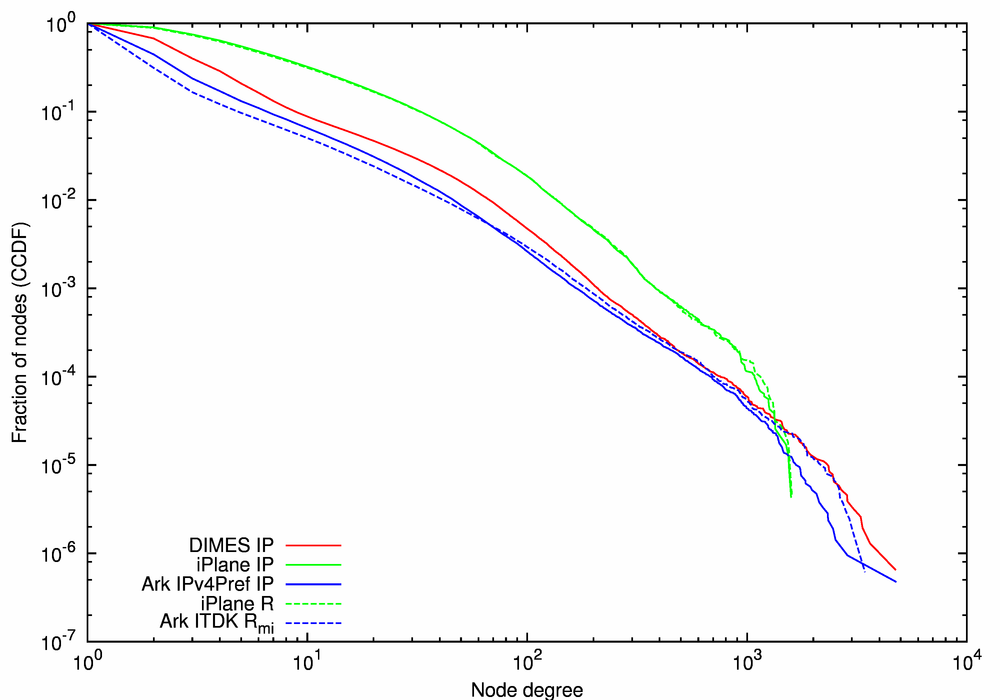 (a) CCDF of Node Degree |
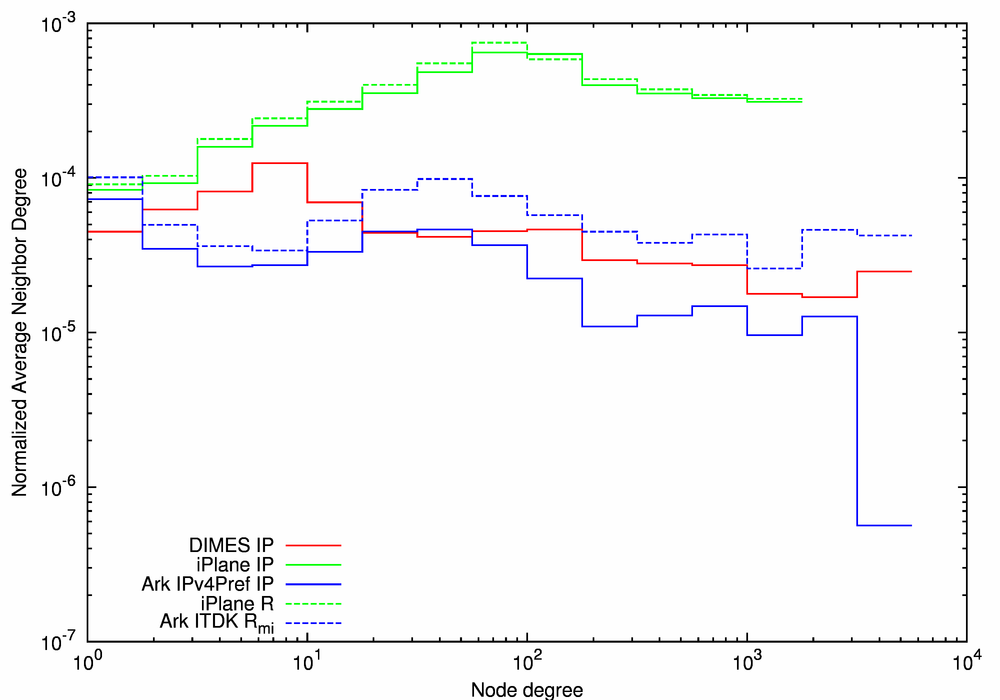 (b) Average Neighbor Degree |
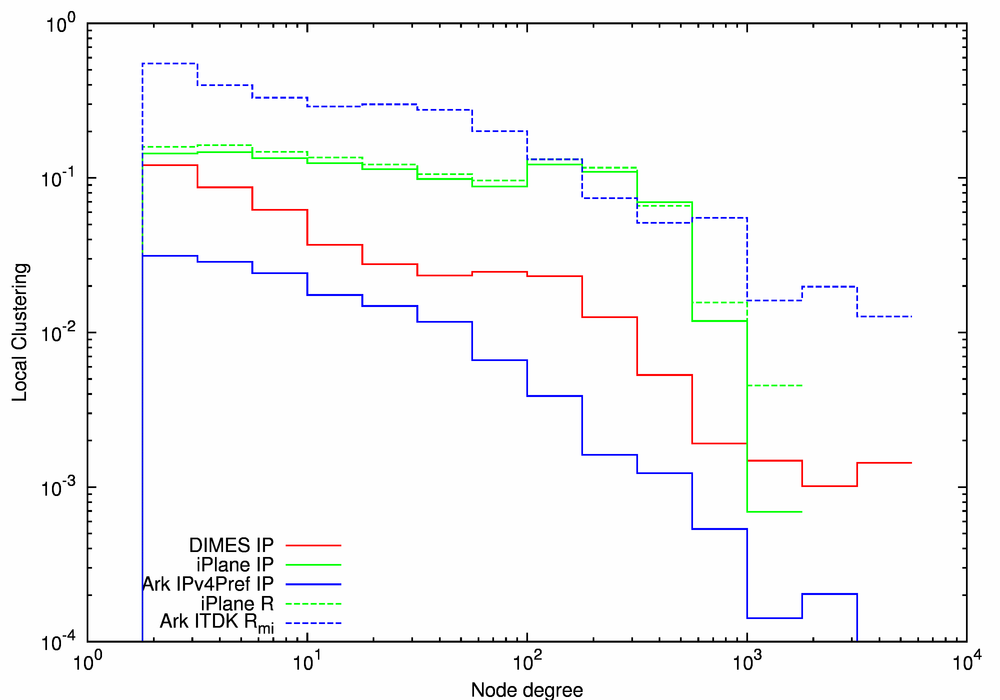 (c) Local Clustering |
|---|---|---|
| Figure 7. Statistical characteristics of the IP- and router-level graphs. | ||
The plots in Figure 7 are: the CCDF of node degree, the average neighbor degree, and local clustering, as functions of node degree, for the three IP-level (solid lines) and the two router-level (dashed lines) graphs. The x-values (degrees) are log-binned using four bins per decade. For all three statistics, the statistical characteristics of iPlane IP and iPlane Router graphs (the green lines) are similar, consistent with iPlane's conservative methods of alias resolution; less than 6% of the nodes in the IP-level graph are collapsed into routers.
Figure 7a reveals that the node degree distribution in both iPlane graphs is skewed toward high-degree nodes: 30% of nodes have a degree larger than 10, compared to 10% or fewer for both Ark-derived (the blue lines) and the DIMES IP (the red line) graphs. We have already noted this effect in the ground truth comparison (cf. Figure 6c).
Figure 7b plots normalized average neighbor degrees. Unlike the degree distributions, which describe nodes in isolation, average neighbor degree captures how nodes of different degrees interconnect. We see two types of behavior. For both iPlane graphs, the average neighbor degree is initially increasing as the node degree increases, but high degree nodes k>100 tend to connect to smaller degree nodes and the average neighbor degree decreases. The DIMES IP graph has a similar behavior, but the average neighbor degree starts decreasing for k>10. In contrast, the average neighbor degree remains nearly constant (within a factor of 3) for both Ark-derived graphs in the whole range of node degrees.
Considering local clustering as a function of node degree (Figure 7c), we notice the ITDK Router graph generally has the largest clustering, followed, in turn, by both iPlane data sets, DIMES, and Ark IPv4Pref IP. Alias resolution, i.e., aggregating IP addresses into a router-level graph, increases clustering since it decreases the number of nodes but makes them densely connected.
5.2 - Characteristics of AS-Level Graphs
| graphs | data type | number of | degree | normalized avg avg neighbor degree |
mean local clustering |
γ | |||
|---|---|---|---|---|---|---|---|---|---|
| nodes | edges | avg | max | least-square fit of CCDF |
maximum-likelihood fit of degree sequence |
||||
| Ark IPv4Pref AS | traceroute | 27,399 | 68,685 | 5.01 | 3,245 | 0.019 | 0.35 | ||
| Ark ITDK ASro | traceroute | 25,578 | 66,401 | 5.19 | 2,607 | 0.016 | 0.33 | 2.19 | 2.18 |
| Ark ITDK ASri | traceroute | 27,797 | 77,965 | 5.61 | 2,815 | 0.018 | 0.36 | 2.11 | 2.20 |
| DIMES AS | traceroute | 25,774 | 78,373 | 6.08 | 4,386 | 0.029 | 0.43 | 2.12 | 2.18 |
| iPlane AS | traceroute | 17,937 | 61,218 | 6.83 | 3,753 | 0.042 | 0.50 | 2.11 | 2.22 |
| RouteViews2 AS | BGP | 37,606 | 80,051 | 4.26 | 3,100 | 0.016 | 0.21 | 2.15 | 2.12 |
| BGP full AS | BGP | 36,876 | 103,481 | 5.61 | 2,972 | 0.014 | 0.24 | 2.12 | 1.97 |
| IRL AS | BGP | 38,524 | 125,105 | 6.49 | 3,211 | 0.015 | 0.30 | 2.13 | 1.90 |
| WHOIS RIPE AS | WHOIS | 22,898 | 134,448 | 11.74 | 3,727 | 0.027 | 0.37 | ||
In Table 3, all of the data sources other than WHOIS RIPE AS match a model of the AS degree distribution as a power law function with exponent γ between 2.1 and 2.2. The closer the value of the power law exponent to 2, the relatively more hubs (high-degree nodes) in the network. (Note that a network cannot have a power-law degree distribution with γ < 2 over the whole range of degrees due to structural constraints [BPV04], namely that for a power-law node degree distribution, the maximum degree possible in a sample of N nodes is N1/(γ-1). If γ is <2, then the maximum degree could be >N, which is impossible. Therefore, an attempt to generate graphs with a power-law degree distribution with exponent <2 results in an exponential cutoff at large degrees. Such degree distributions have never been observed for real networks.)
Due to the large number of data sources used for AS-level graph comparison, we first analyze AS-graphs within each subgroup: Ark, traceroute, BGP, and then select a single representative from each subgroup for our overall comparison which also includes an AS graph derived from WHOIS data.
5.2.1 - Differences between Ark-based AS graphs
First, we analyze the differences between AS-graphs constructed directly from Ark data (Ark IPv4Pref AS) and from the router-level graph in ITDK using the two different methods described above (Ark ITDK ASro and Ark ITDK ASri).
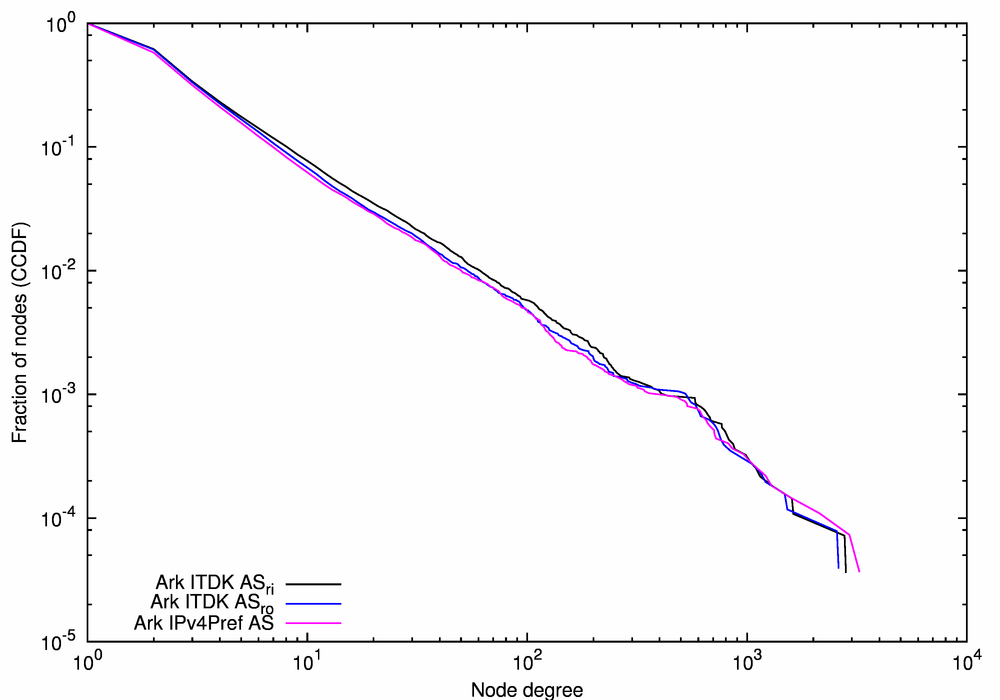 (a) CCDF of Node Degree |
 (b) Average Neighbor Degree |
 (c) Local Clustering |
|---|---|---|
| Figure 8. Statistical characteristics of the AS-level graphs derived from the Ark/ITDK data using three different methods. | ||
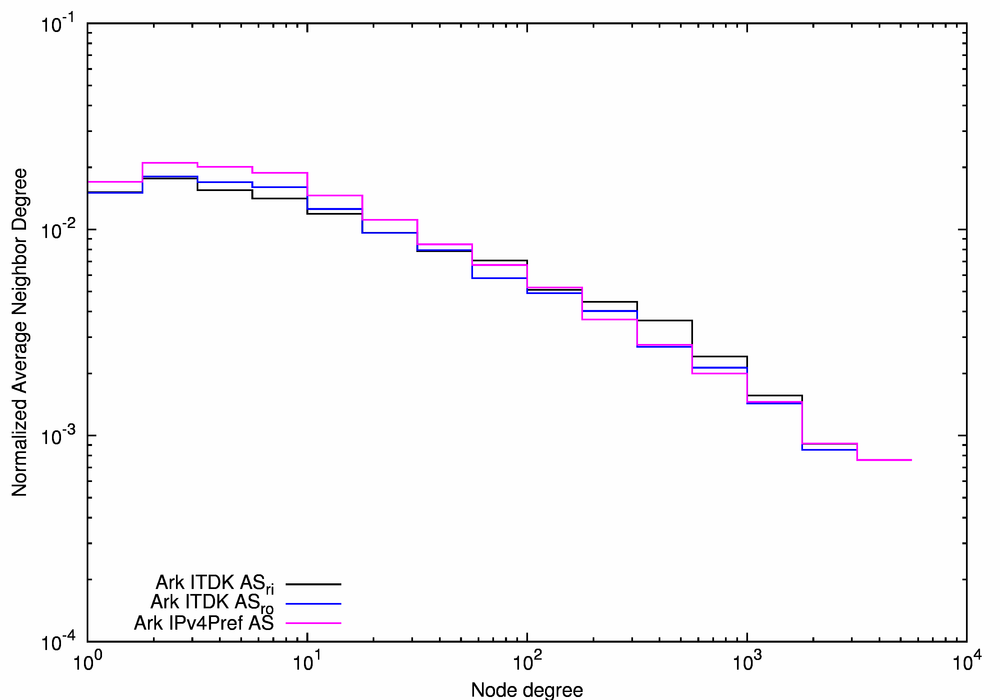
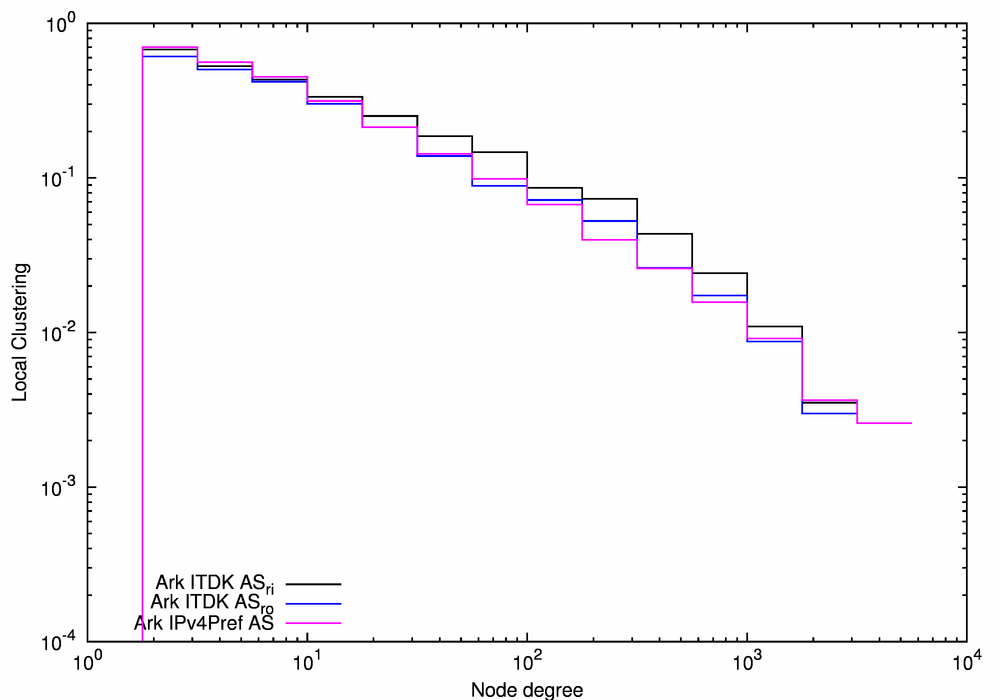
Figure 8 illustrates the similarity of our three topological metrics for the three Ark/ITDK-derived AS graphs, although the Ark ITDK ASri graph (the black lines) exhibits higher degrees and higher local clustering than the other two graphs due to the inclusion of the additional links inferred in the process of IP-to-router and router-to-AS mappings.
Degree distributions of the Ark IPv4Pref AS (the purple line) and Ark ITDK ASro (the blue line) graphs are noticeably different for the largest nodes with k > 1000 (Figure 8a). We select the Ark ITDK ASro graph as the representative of our Ark/ITDK-derived group of AS-level Internet graphs for comparison with other traceroute-derived AS-level graphs. This graph is likely more accurate than the Ark IPv4Pref AS graph because the former is derived from the router-level graph of the Internet which is a more accurate representation of the Internet than the IP-level graph. Among the two router-based AS-level graphs, the router-observed one more closely reflects observed paths, and thus captures some policy restrictions not conveyed in the router-inferred graph.
5.2.2 - Differences between Traceroute-based AS graphs
 (a) CCDF of Node Degree |
 (b) Average Neighbor Degree |
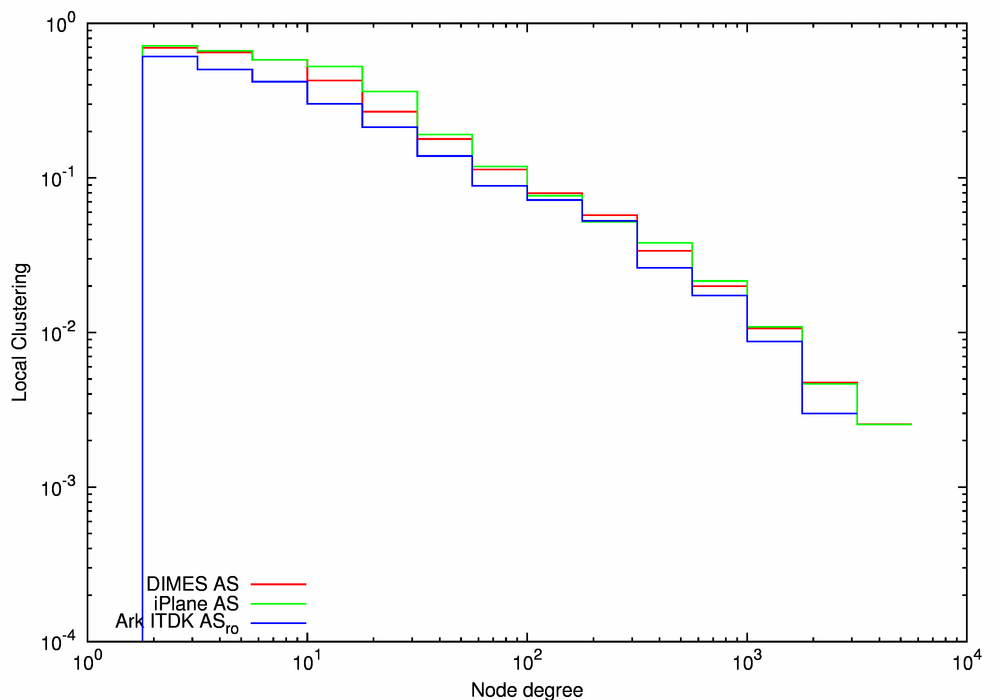 (c) Local Clustering |
|---|---|---|
| Figure 9. Statistical characteristics of the traceroute-based AS-level graphs. | ||
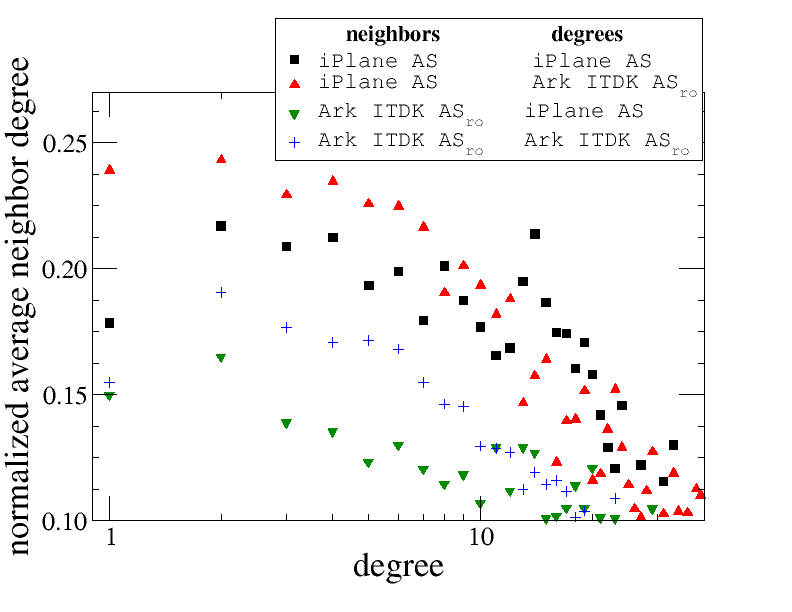 Figure 10. Exploring the contribution of two factors to
the larger average neighbor degree in the iPlane AS graph
versus the Ark ITDK ASro: the set of neighbors
or the degrees of those neighbors. We "simulate" switching
these two factors independently for both graphs.
The highest normalized average degree derives from the
neighbors in iPlane AS with neighbor degrees from
Ark ITDK ASro; the smallest
normalized average degree derives from the opposite.
The change in neighbors (toward nodes with higher degree)
seems primarily responsible for the difference in average
neighbor degree between the two graphs.
Figure 10. Exploring the contribution of two factors to
the larger average neighbor degree in the iPlane AS graph
versus the Ark ITDK ASro: the set of neighbors
or the degrees of those neighbors. We "simulate" switching
these two factors independently for both graphs.
The highest normalized average degree derives from the
neighbors in iPlane AS with neighbor degrees from
Ark ITDK ASro; the smallest
normalized average degree derives from the opposite.
The change in neighbors (toward nodes with higher degree)
seems primarily responsible for the difference in average
neighbor degree between the two graphs.
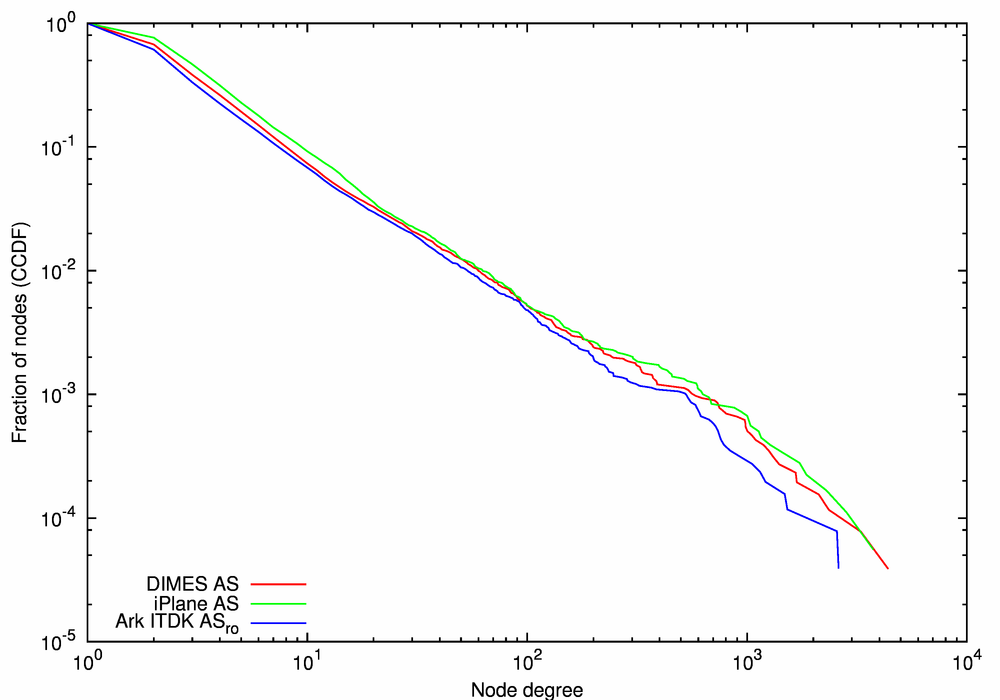
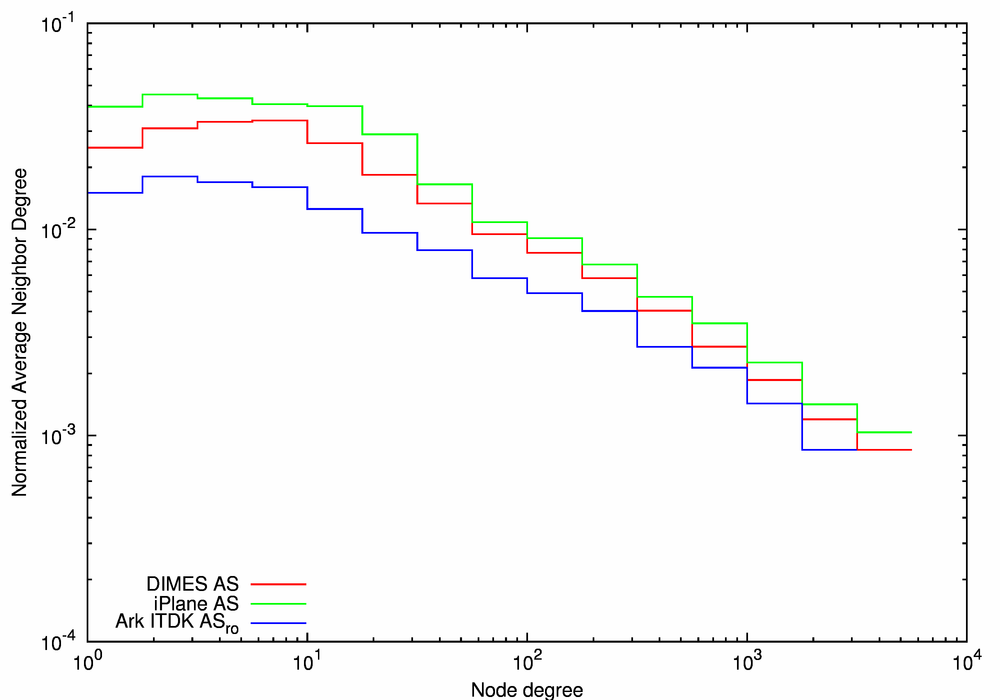
Figure 9 compares the Ark ITDK ASro AS-level topology (the blue line) with the two other traceroute-based AS graphs, DIMES AS (the red line) and iPlane AS (the green line). The CCDFs of node degree (Figure 9a) and local clustering (Figure 9c) are similar for all three graphs. For each value of node degree, the average neighbor degree is the highest for the iPlane AS graph and the lowest for the Ark ITDK ASro graph (Figure 9b). There are three possible reasons for this observed increase of the average neighbor degree between the Ark ITDK ASro and iPlane AS graphs: the change in the set of neighbors, the increase in degrees of those neighbors, or a combination of the two.
To try to untangle the relative contribution of these two factors to the average neighbor degree, we conducted the following simulation. We considered the Ark ITDK ASro graph and the iPlane AS graph and two simulated graphs obtained by swapping either the set of neighbors each AS has or the degrees of those neighbors between the two actual graphs. Figure 10 presents four plots, one for each of the possible permutations:
- ■ the actual iPlane AS graph;
- ▲ the set of neighbors from the iPlane AS graph with the degrees seen for those neighbors in the Ark ITDK ASro graph;
- ▼ the set of neighbors from the Ark ITDK ASro graph with the degrees seen for those neighbors in the iPlane AS graph;
- + the actual Ark ITDK ASro graph.
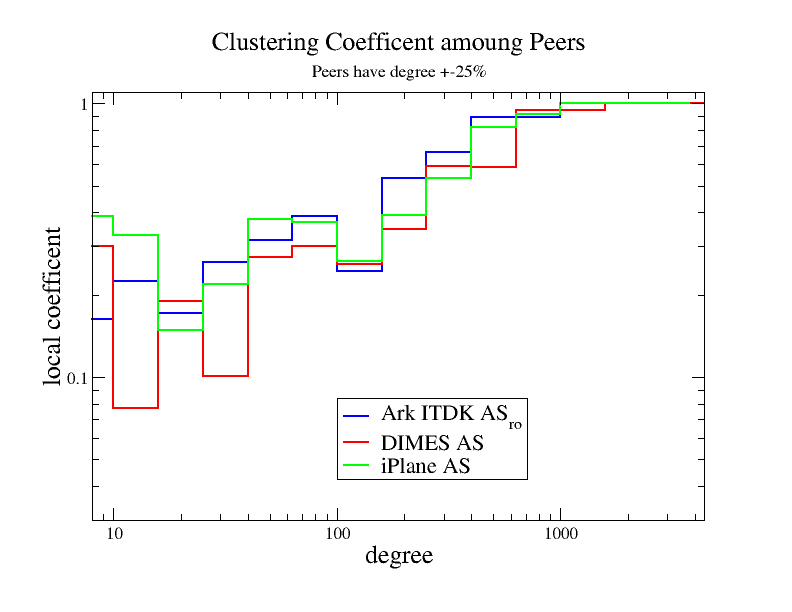 Figure 11. Local clustering calculated for subgraphs formed by
nodes with degrees within 25% of each other. As the degree increases
so does the local clustering coefficient, indicating that nodes of
a similar size tend to be interconnected.
Figure 11. Local clustering calculated for subgraphs formed by
nodes with degrees within 25% of each other. As the degree increases
so does the local clustering coefficient, indicating that nodes of
a similar size tend to be interconnected.
When studying AS relationships in the real world, we often assume that ASes that are at similar levels in the AS hierarchy enter into peering relationships to decrease transit costs. The manifestation of this assumption in the AS-level graphs is a tendency to form cliques between ASes of a similar size. Figure 11 examines the behavior of local clustering if we include only nodes of roughly the same size into the clustering calculations, in this case, specifically, neighbors that have degrees within ±25% of each other. In contrast to Figure 9c where local clustering is a decreasing function of node degree, local clustering becomes an increasing function of node degree in Figure 11. This simulation confirms the clique-forming hypothesis between ASes of similar sizes, described above.
5.2.3 - Differences between BGP-based AS graphs
Next, we consider the three BGP-based graphs: RouteViews2 generated from a single largest BGP collector, RouteViews2 server, BGP Full derived from all available BGP servers (5 in Routeviews and 14 in RIPE NCC RIS), and IRL compiled by IRL from multiple sources. Table 3 shows that the more contributors to a given data set, the more edges and the higher average degree and mean clustering of the resulting topology. This result is intuitive: the more vantage points, the more edges they can observe, in particular tangential links between low- and medium- degree nodes [MKFHDCV06] (cf. also Figure 12a below).
 (a) CCDF of Node Degree |
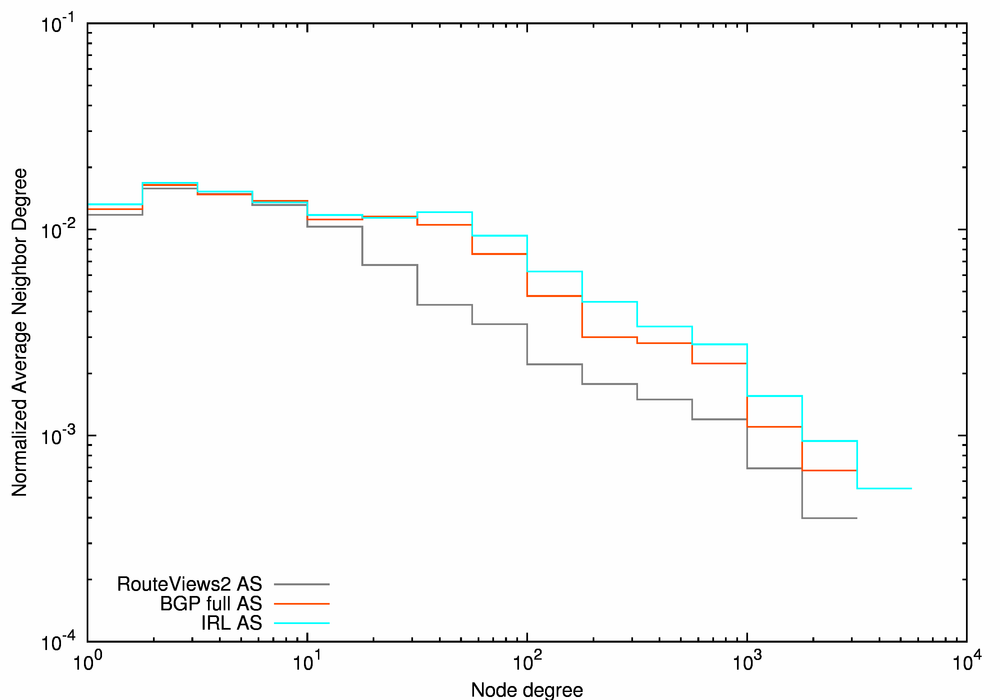 (b) Average Neighbor Degree |
 (c) Local Clustering |
|---|---|---|
| Figure 12. Statistical characteristics of the AS-level graphs derived from BGP data sources. | ||
Figure 12 plots our three chosen topological metrics for for the three BGP-based AS-level graphs: the CCDF of node degree, and the average neighbor degree and local clustering as functions of node degree The x-values (degrees) are log-binned using four bins per decade.
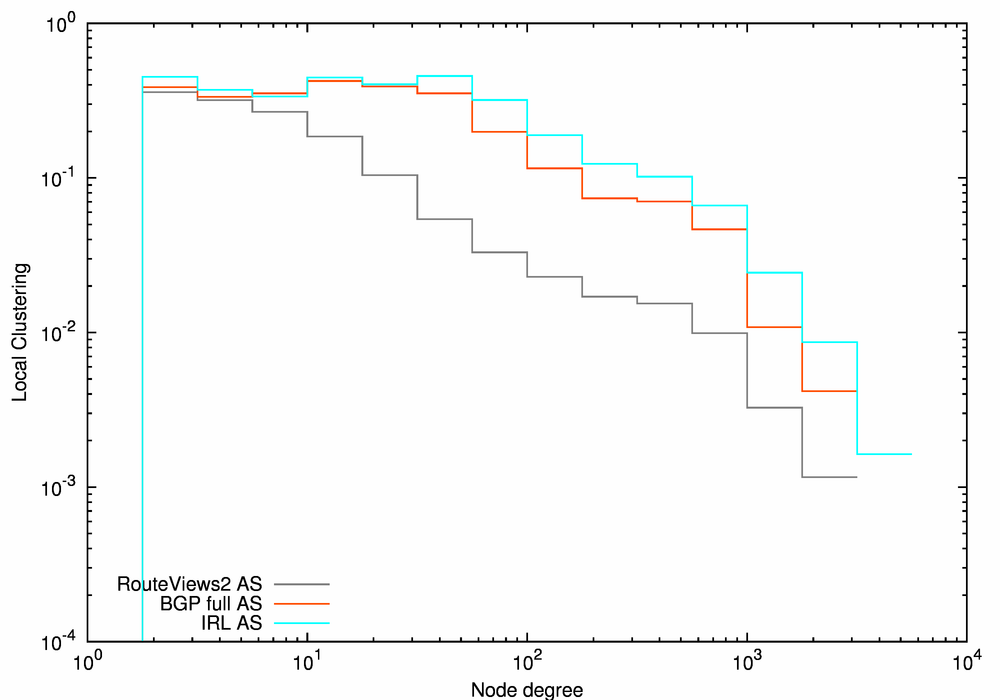
Figure 12a, the CCDF of node degree, confirms that IRL AS graph (the cyan line), compiled from the largest number of diverse contributors (Route Views, RIPE-NCC RIS, Packet Clearing House, traceroute.org, bgp4.net), has a slightly larger percentage of high-degree nodes than the other two graphs: 0.77% of IRL AS nodes have degree greater than 100, compared to 0.62% for BGP Full AS and 0.33% for RouteViews2 AS data. Although these high-degree nodes make up only a tiny fraction of the total graphs, they represent the top of the Internet routing hierarchy, serving a critical routing function. Notably, AS 3356 (Level3) and AS 174 (Cogent) COGENT are consistently ranked first and second, and ASes 7018 (ATT) and 3549 (Global Crossing) are ranked third and fourth in all data sets except for WHOIS. However, the fractions of nodes with an order of magnitude larger degrees (> 1000) are similar in all three graphs: 0.04%, 0.03%, and 0.02%, for IRL AS, BGP Full AS, and RouteViews2 AS, respectively. Increasing the number and diversity of BGP-data contributors seems to to reveal additional connectivity mostly for nodes with medium degrees.
Figure 12b plots the average neighbor degree vs. node degree. For small degrees (k <10 for the RouteViews2 AS graph, k <70 for the IRL AS and BGP Full AS graphs) the average neighbor degree is nearly constant, and it becomes a decreasing function of node degree at larger degrees. AS-level graphs are known [MKFHDCV06] to be disassortative: small ASes connect to larger ASes and larger ASes connect to smaller ASes. The flat areas for BGP full AS and IRL AS for ASes with degrees between 10 and 50 indicate a denser connectivity between middle-tier ASes observed due to a larger number of vantage points used to collect the raw data.
Figure 12c demonstrates that as the node degree increases, the local clustering drops much faster for RouteViews2 (the black line) than for the other two graphs. In contrast, for the BGP Full AS and IRL AS topologies, the local clustering is approximately constant or even increasing slightly for small node degrees, and starts decreasing only for degrees above 50. The larger number of vantage points captures more tangential links between small nodes. The BGP Full AS graph derived from a combination of multiple BGP tables is noticeably more complete than the RouteViews2 AS graph derived from just a single BGP table, but using a combination of seven diverse contributors in the case of the IRL AS graph does not add much to the connectivity already captured from BGP tables.
All the characteristics of the BGP Full AS (the red line) and the IRL AS (the cyan line) graphs presented in Figure 12 are similar for all node degrees, suggesting that the combination of BGP tables used in the BGP Full AS data set is capturing a representative sample of the underlying AS topology even with fewer contributors than the IRL AS data set. Therefore, we select the BGP Full AS graph as a representative of BGP-derived AS-level graphs for the overall comparison in the next subsection.
5.2.4 - All AS-level graphs
 (a) CCDF of Node Degree |
 (b) Average Neighbor Degree |
 (c) Local Clustering |
|---|---|---|
| Figure 13. Statistical characteristics of the AS-level graphs derived from different types of data sources. | ||
The final comparison includes a single representative AS topology graph from each of the previous three AS-level comparisons, and the RIPE WHOIS AS graph, which exists as a class of its own.
Note that the RIPE NCC service region consists of countries in Europe, the Middle East and parts of Central Asia [RIPENCCb], so the AS graph derived from their WHOIS database represents primarily European connectivity. In [MKFHDCV06] when we compared statistical properties of AS-level graphs derived from BGP tables, traceroute measurements, and WHOIS data, we investigated whether the substantial difference in topological properties between the WHOIS-based graph and the other two graphs could be explained by the geographical biases in the data. We confirmed that geographic bias could not fully explain the disparity, since when we took the subset of topology connecting nodes in both the BGP and WHOIS graphs, the resulting graphs preserved the normalized topological properties of the original graphs.
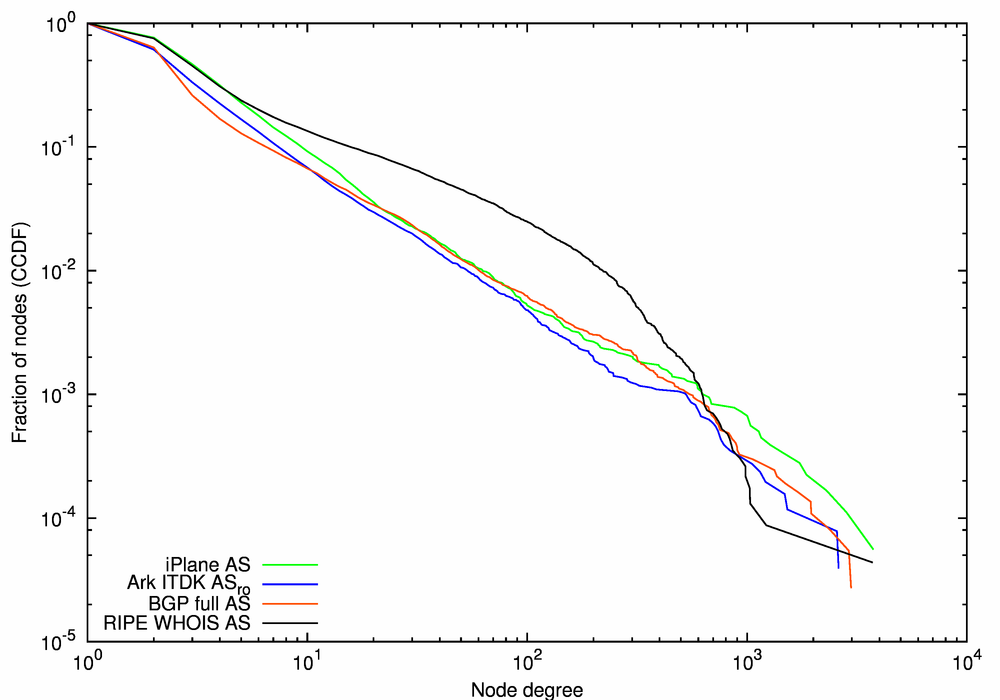
Figure 13a, the CCDF of node degrees, shows that the BGP full AS (the red line) and the Ark ITDK ASro (the blue line) graphs have relatively higher fractions of edge ASes with degrees 1 and 2: 36% and 39% vs. 25% in the RIPE WHOIS AS graph (the black line) and 23% in the iPlane AS graph (the green line). In comparison with the other three graphs, the RIPE WHOIS AS graph has an excess of nodes with medium degrees between 5 and 500. This graph is distinctively different from the other three in that its degree distribution does not fit the power-law function, while the other three can be approximated as a power-law with the exponent γ = 2.1-2.2. iPlane AS has the largest fraction of ASes with degree >1000: 0.07% compared to 0.03% or fewer for the Ark ITDK ASro, BGP full AS, and WHOIS RIPE AS graphs.
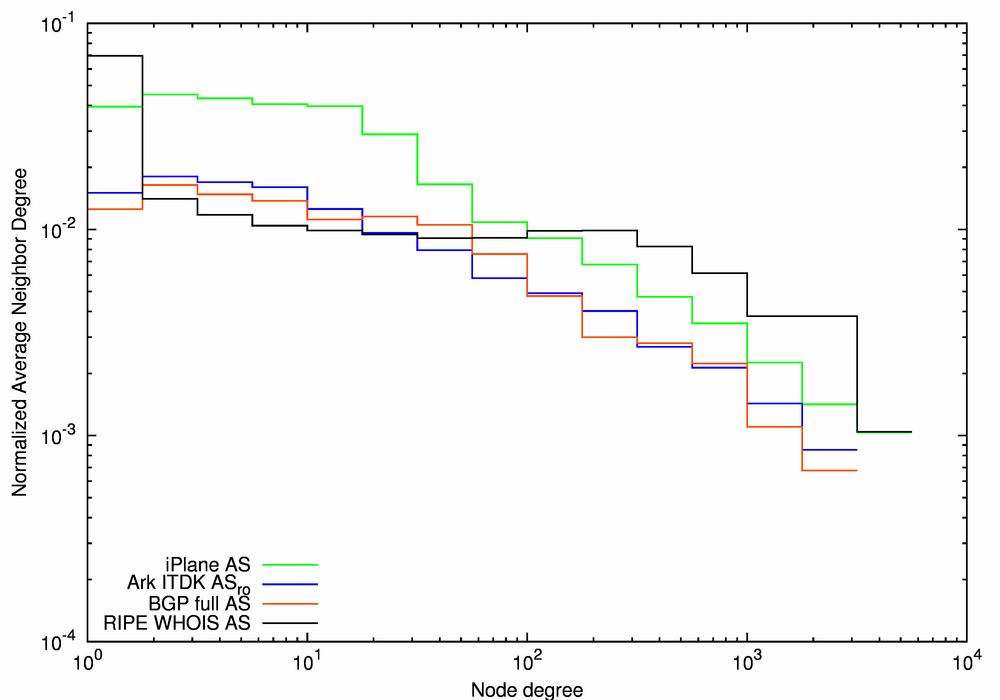
Considering the average neighbor degree (Figure 13b), we notice that the RIPE WHOIS AS graph (the black line) has the largest average neighbor degree for ASes with a degree of 1. In all four graphs, the average AS neighbor degree decreases as the AS degree increases (i.e., the AS-graphs are disassortative), although for the RIPE WHOIS AS graph it remains nearly constant for degrees between 2 and 200 and only starts decreasing at larger degrees. This behavior reflects a relative excess of medium-degree nodes in this graph. Among the other three graphs, iPlane AS (the green line) has the highest average neighbor degree across all degree ranges while the same distribution for the BGP Full AS and the Ark ITDK ASro graphs are lower and similar to each other.
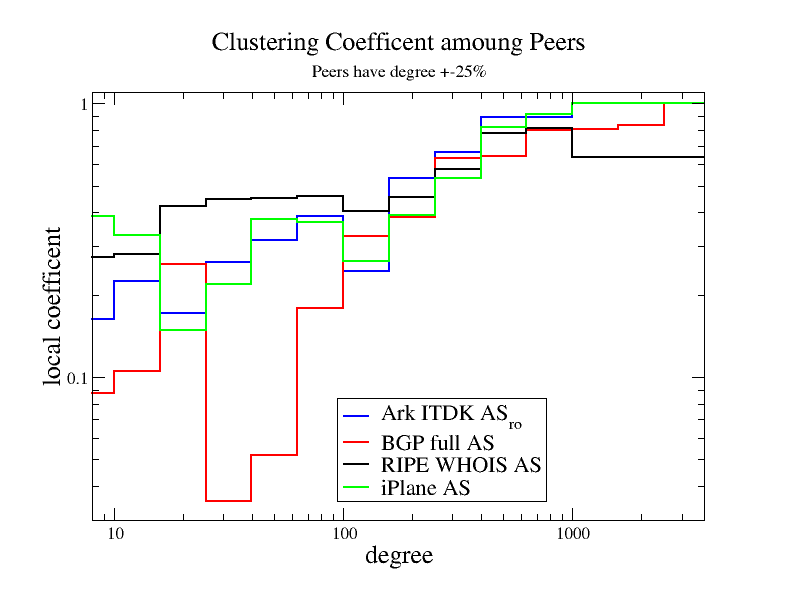 Figure 14. Local clustering calculated for subgraphs formed by
nodes with degrees within 25% of each other. As the degree increases
so does the local clustering coefficient, indicating that nodes of
a similar size tend to be interconnected.
Figure 14. Local clustering calculated for subgraphs formed by
nodes with degrees within 25% of each other. As the degree increases
so does the local clustering coefficient, indicating that nodes of
a similar size tend to be interconnected.
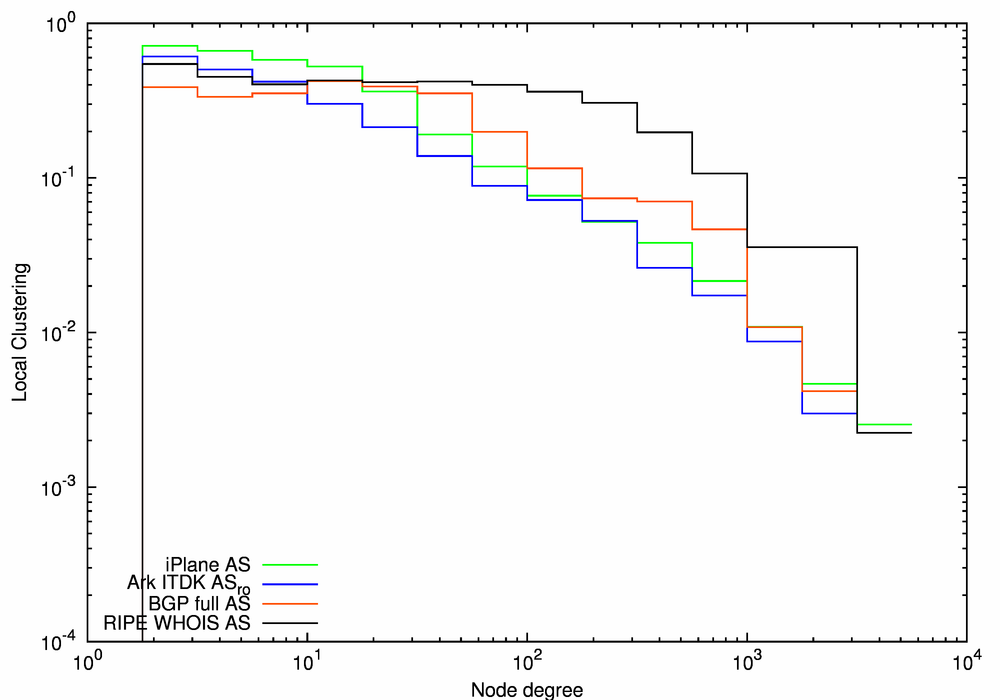
The RIPE WHOIS AS graph (the black line) also stands apart from the other graphs in Figure 13c, which depicts local clustering as the function of node degree. For this graph, local clustering remains nearly constant (and mostly higher than for the other three graphs) for node degrees <200. Comparing the black RIPE WHOIS AS lines in Figures 13b and 13c, we see that the inflection points in both plots occur at around node degree of 200. This coincidence could mean that as the average neighbor degree decreases, these neighbors do not have a high enough degree to form clusters by connecting to other (too numerous) neighbors of a given high-degree node.
Figure 14 again shows local clustering calculated for subgraphs formed by nodes of similar degrees, that is, within 25% of each other. In this case, the RIPE WHOIS AS clustering is similar to that of the other graphs. As in Figure 12, the local clustering increases with the node degree and the links between smaller nodes drag down the average clustering. Since the RIPE WHOIS AS graph has a lower percentage of small degree nodes (cf. Figure 13a which shows a relative excess of nodes in the 100-600 degree range), fewer of its links connect to them, which makes local clustering higher.
Considering the other three graphs in Figure 13c, we notice that the local clustering in the iPlane AS graph (the green line) is slightly higher or the same as in the Ark ITDK ASro graph (the blue line) at each degree value. The local clustering of the BGP-based BGP Full AS graph (the red line) is lower than that of the traceroute-based iPlane AS and Ark ITDK ASro graphs for small degrees <10, but is higher in the medium degree range of 10 < k < 800. Consistent with how BGP vs traceroute data is collected, BGP graphs shed more light on higher-degree ASes than on the periphery; and conversely, traceroute infrastructures with vantage points scattered at the periphery will capture relatively more low-degree nodes.
6. Conclusion
Researchers need topology maps to describe, analyze, or model Internet structure. Unfortunately, many studies use single, inconsistent, incomplete, or undocumented data sources, which can undermine integrity of research and analysis results. Our objective with this study is to enable more informed selection of topology datasets, by taking a rigorous approach to systematically comparing the topologies inferred from the best available data sources and typically used inference techniques. Following up on our 2006 study [MKFHDCV06], we compared topology graphs at three granularities (IP interface, router, and AS) derived from seven different topology data sources (CAIDA's traceroute data, BGP (Routeviews and RIPE NCC RIS), IRR data (RIPE's WHOIS registry, iPlane, DIMES, and IRL.
Like many Internet data analysis projects, what seemed like a conceptually straightforward proposition at the beginning turned into an extended struggle with incongruent, incomplete, and underdocumented data sets. For example, before we could even begin to use WHOIS data, which is inconsistently volunteered and maintained by ISPs, we had to heuristically estimate the maximum age of data we would still trust to accurately reflect peering topology. Other challenges included processing the traces differently for each topology granularity, simulating and evaluating different techniques for handling non-responsive hops, applying our best understanding of alias resolution techniques to the processing and interpretation of the data sources, and comparing the results to a moderately sized and limited ground truth data set -- a Tier1 backbone ISP (with 2420 routers).
We used four basic statistical properties and plotted their CCDFs to compare topology data sets: node degree distribution; average neighbor degree; and local clustering as a function of node degree. In terms of comparison to ground truth, none of the topologies perfectly reflect reality, nor do they claim to. The DIMES and Ark data sets have an order of mangitude more nodes, since Iplane focuses on capturing the backbone topology not the edge. The structural metrics reflect this difference; the Iplane IP and router-level graphs have fewer nodes, but of higher degree, and higher mean local clustering, also this last disparity disappears after alias resolution. Iplane's alias resolution methods appear to be less aggressive (more conservative) than those we implement to derive our router-level graphs (ITDKs). Even a small fraction of false inferences can substantially affect (i.e., misinform) statistical properties of the graph. To avoid false positives and associated distorted statistics, we use the more conservatively-inferred Ark router-level topology (of the two in each ITDK) in our comparisons. We also learned that a "full" BGP table derived from a combination of multiple BGP tables is noticeably more complete than just using one BGP table, but the seven diverse contributors in the case of the IRL AS graph did not change the connectivity characteristics significantly from the "full" BGP graph.
All of the data sources other than WHOIS RIPE AS match a model of the AS degree distribution as a power law function with exponent between 2.1 and 2.2, reflecting an abundance of high-degree (hub) nodes in the network. We also confirmed that ASes of a similar size tend to be richly interconnected with eachother, while the graph is also disassortative, i.e., low-degree ASes tend to connect with high-degree ASes.
The same four ASes (of Level 3, Cogent, ATT, and Global Crossing) are consistently ranked in the top four in our data sets, and the fractions of ASes with peering degree over 1000 is less than 0.04% in all three BGP-based graphs. Consistent with how BGP vs traceroute data is collected, BGP graphs shed more light on higher-degree ASes than on the periphery; and conversely, traceroute infrastructures with vantage points scattered at the periphery will capture relatively more low-degree nodes. Increasing the number and diversity of BGP-data contributors seems to to reveal additional connectivity mostly for nodes with medium degrees.
As far as we know, this the most comprehensive study thus far of this type, with published sources of data, metrics, methods, and results. The investment of effort required to gather, curate, interpret, and integrate Internet topology data into research project is intimidatingly huge. We hope this analysis will facilitate more informed selection of topology datasets to support specific research or analysis needs.
7. References
[AMI] datasource:Archipelago Measurement Infrastructure (ark), July 2010.
[ASR] CAIDA AS Rank.
[BPV04] M. Boguna, R. Pastor-Satorras, and A. Vespignani, Cut-offs and finite size effects in scale-free networks,
The European Physical Journal B - Condensed Matter and Complex Systems,
Volume 38, Number 2, pp. 205-209, 2004.
[BSS08] A. Bender, R. Sherwood, and N. Spring, Fixing Ally's Growing Pains wi5th Velocity Modeling, Internet Measurement Conference (IMC), pp. 337-342, 2008.
[BT02] T. Bu and D. Towsley, On Distinguishing between Internet Power Law Topology Generators, IEEE INFOCOM, 2002.
[CCGJSW02] Q. Chen, H. Chang, R. Govindan, S. Jamin, S. Shenker, and W. Willinger, The Origin of Power Laws in Internet Topologies Revisited, IEEE INFOCOM, 2002.
[CSN09] A. Clauset, C. Rohilla Shalizi, and M. Newman, Power-Law Distributions in Empirical Data SIAM Rev. 51, pp. 661-703, 2009.
[FFF99] M. Faloutsos, P. Faloutsos, and C. Faloutsos, On Power-law Relationships of the Internet Topology, ACM SIGCOMM, pp. 251-262, 1999.
[GP04] M. Gaertler, and M. Patrignani, Dynamic Analysis of the Autonomous System Graph, IPS, 2004.
[GS06] M. Gunes, and K. Sarac, Analytical IP Alias Resolution, IEEE ICC, 2006.
[GT00] R. Govindan and H. Tangmunarunkit, Heuristics for Internet map discovery, INFOCOM, v.3, pp. 1371-1380, 2000.
[HDFC10] B. Huffaker, A. Dhamdhere, M. Fomenkov, and k. claffy, Toward Topology Dualism: Improving the Accuracy of AS Annotations for Routers, Passive and Active Network Measurement Workshop (PAM), April 2010.
[I2ODC] datasource:Internet2's BG collections.
[IART] iffinder alias resolution tool.
[IRL] dataset:Internet Research Lab.
[IRR] datasource:Internet Routing Registries, January 2011.
[ITDK] datasource:Internet Topology Data Kit (ITDK), July 2010. https://www.caida.org/catalog/datasets/internet-topology-data-kit/
[JRT04] S. Jaiswal, A. L. Rosenberg, and D. Towsley, Comparing the Structure of Power-Law Graphs and the Internet AS Graph, IEEE ICNP, 2004.
[Ke10] K. Keys, Internet-Scale IP Alias Resolution Techniques, ACM SIGCOMM CCR, 40, pp. 50-55, 2010.
[KHLC11] K. Keys, Y. Hyun, M. Luckie, and k. claffy, Internet-Scale IPv4 Alias Resolution with MIDAR: System Architecture, CAIDA Technical Report, 2011.
[KS11] W. Kumari, and K. Sriram, Recommendation for Not Using AS_SET and AS_CONFED_SET in BGP, Network Working Group, Internet-Draft, 2011.
[LAWD04] L. Li, D. Alderson, W. Willinger, and J. Doyle, A First-Principles Approach to Understanding the Internet Router-Level Topology, ACM SIGCOMM, 2004.
[LHH08] M. Luckie, Y. Hyun, and B. Huffaker, Traceroute Probe Method and Forward IP Path Inference, Internet Measurement Conference (IMC), pp. 311-324, October 2008.
[MIPDAKV06] H. Madhyastha, T. Isdal, M. Piatek, C. Dixon, T. Anderson, A. Krishnamurthy, and A. Venkataramani, iPlane: An Information Plane for Distributed Services, 7th USENIX Symposium OSDI, pp. 367-380, 2006.
[MKFHDCV06] P. Mahadevan, D. Krioukov, M. Fomenkov, B. Huffaker, X. Dimitropoulos, k. claffy, and A. Vahdat, The Internet AS-Level Topology: Three Data Sources and One Definitive Metric, ACM SIGCOMM Computer Communications Review (CCR), v. 36, pp. 17-26, January 2006.
[MKFV06] P. Mahadevan, D. Krioukov, K. Fall, and A. Vahdat, Systematic Topology Analysis and Generation Using Degree Correlations, SIGCOMM, 36, 135-146, 2006.
[PG98] J.-J. Pansiot and D. Grad, On routes and multicast trees in the Internet, ACM SIGCOMM, 1998.
[PL] datasource:PlanetLab.
[RFC792] J. Postel, Internet Control Message Protocol, RFC 792, September 1981.
[RFC1771] Y. Rekhter, and T. Li, A Border Gateway Protocol 4 (BGP-4), March 1995.
[RFC1918] Y. Rekhter, B. Moskowitz, D. Karrenberg, G. J. de Groot, and E. Lear, Address Allocation for Private Internets, RFC 1918, February 1996.
[RFC3912] L. Daigle, WHOIS Protocol Specification, RFC 3912, September 2004.
[RIPENCCa] RIPE Network Coordinate Centre.
[RIPENCCb] RIPE NCC - From Wikipedia, the free encyclopedia.
[RIS] RIPE NCC Routing Information Service.
[SF04] G. Siganos, and M. Faloutsos, Analyzing BGP Policies: Methodology and Tool, IEEE INFOCOM, 2004.
[SKPMAK10] J. Sherry, E. Katz-Bassett, M. Pimenova, H. Madhyastha, T. Anderson, and A. Krishnamurthy, Resolving IP Aliases with Prespecified Timestamps, IMC, 2010.
[SMWA04] N. Spring, R. Mahajan, D. Wetherall, and T. Anderson, Measuring ISP Topologies With Rocketfuel, IEEE ACM ToN, 12, pp. 2-16, 2004 .
[SS05] Yu. Shavitt, and E. Shir, DIMES: Let the Internet Measure Itself, ACM SIGCOMM CCR, 35(5), pp. 71-74, 2005.
[TCBL] Team Cymru's Bogon list.
[TGJSW02] H. Tangmunarunkit, R. Govindan, S. Jamin, S. Shenker, and W. Willinger, Network Topology Generators: Degree-Based vs. Structural, ACM SIGCOMM, pp. 147-159, 2002.
[TLGAC] Traceroute and Looking Glass applications and code
[UORVP] datasource:University of Oregon RouteViews Project, January, 2011.
[ZM04a] S. Zhou, and R. Mondragon, Redundancy and robustness of AS-level Internet topology and its models, Electronics Letters, pp. 151-152, 2004.
[ZM04b] S. Zhou, and R.J. Mondragon, Accurately Modeling the Internet Topology, Physical Review E, 066108, 2004.