

OKN-KISMET: Open Knowledge Network - Knowledge of Internet Structure: Measurement, Epistemology, and Technology
An abbreviated version of the original proposal is shown below.
Sponsored by:
")
Principal Investigators: kc claffy Geoffrey Voelker
Funding source: C-ACCEL OIA-1937165 Period of performance: September 1, 2019 - May 31, 2021.
1 Introduction
2 Appropriateness for Convergence Accelerator Program
3 Components to Support an Open Knowledge Network
-
ICANN Centralized Zone Data Service. Each Top Level Domain (TLD) registry operator maintains a zone file that contains information on each domain, including associated name server hosts, and IP addresses for those name servers. TLD zone data is inherently public via DNS queries but acquiring an entire zone file for research has historically required applying for access from each TLD registry operator, under appropriate use terms, e.g., no spamming domains. After introducing thousands of new gTLDs in 2012, ICANN established a centralized data access platform to simplify access to all zone files for those new gTLDs. (Legacy gTLDs and country-code TLDs, do not participate in this program.) Many academic researchers make use of zone files for Internet research, and even create other services based on this data. One of PI Voelker's graduate students collected, analyzed and archived changes to 1200 of these zone files every day for years [12] to support his own and collaborators' research [13,14].
-
OpenINTEL active measurements of global namespace. NLNet labs - jointly with three other Dutch research institutions (SURFnet, SIDN Labs, and U. Twente) - has been operating the OpenINTEL project, a system for comprehensive measurements of the global DNS [15]. OpenINTEL uses ICANN's CZDS files, and agreements with many other registries, to drive DNS queries for all covered domains once every 24 hours, covering over 216 million domains per day for: .com, .net, .org, .info, .mobi, .aero, .asia, .name, .biz, .gov, almost 1200 new gTLDs (.xxx, .xyz, .amsterdam, .berlin, ...), and many ccTLDs: .nl, .se, .nu, .ca, .fi, .at, .dk, .ru, .us. The project has collected 3 trillion data points since its inception in 2015. They have used this data to study and improve DNSSEC operational practices, DNS resilience, and identify misconfigurations.
-
Border Gateway Routing Protocol (BGP) Routing data. Two organizations - U. Oregon and RIPE RIS (both collaborators) - collect and store Internet interdomain routing data from several locations around the globe [16,17]. The Network Startup Resource Center at the University of Oregon operates Route Views, the primary (NSF-funded) U.S. source of interdomain routing data for scientific research. The Route Views project was originally conceived as a tool for Internet operators to obtain real-time BGP information about how the global routing system viewed their prefixes and/or AS space, but over the years Route Views data has become invaluably critical to the Internet routing research community. In 2001, RIPE established a similar data collection capability in the Routing Information Service (RIS) [17]. RIS data can be accessed via RIPEstat, which tries to provide a unified interface to available information about Internet number resources.
-
Active traceroute measurements. CAIDA and RIPE both operate global platforms (Ark [18] and RIPE Atlas [19], respectively) which continuously probe the Internet from hundreds or thousands of vantage points (VPs). Each VP executes pre-defined network-layer measurements, e.g., pings, traceroutes, DNS queries, HTTP queries, which help researchers infer connectivity and paths. CAIDA is current hosting a RIPE NCC researcher (Stephen Strowes) for a six-month visit to collaborate on a quantitative comparison of diversity and topological coverage of measurements from the two platforms, and the epistemological impact of these differences. Since 2007, Ark has gathered 170B traceroutes (over 20 TB) from (as of May 2019) 170 Ark monitors (121 cities, 50 countries) hosted by diverse organizations: research/educational, commercial, network infrastructure, residential, etc.1 The Ark platform also performs DNS lookups of all IP addresses observed during probing.2 These datasets grow by approximately 20B traces ( ≈ 10 TB) per year. Few researchers can download data sets of this size, so we created an interactive web-based interface [31] to allow researchers to find the most relevant data for their research, such as all traceroutes through a given region and time period toward or across a particular address, network, or country.
-
Network/organizational structure. The Internet is composed of tens of thousands of independent interconnecting autonomous systems (ASes). One organization may operate one or more autonomous systems, depending on engineering and business practices, e.g., mergers. There is no official data base mapping AS numbers to organizations owning and operating them; CAIDA maintains a heuristic-based mapping of ASes to organizations [32] as well as mapping of the set of IP addresses (v4 and v6) for which each network announces reachability to the global routing system [33].
-
Curated Internet Topology Data Kits (ITDKs). Using raw traceroute and BGP data, CAIDA regularly publishes derivative data sets [34,35,36], including heavily curated two-week snapshots of raw traceroute data into Internet Topology Data Kits (ITDK) [37]. Each ITDK contains inferred, DNS-annotated, router-level and AS-level topologies of the global Internet, based on paths gathered from a large cross-section of the global Internet. We have increased the richness of ITDKs over time by integrating new techniques as we develop them, including AS ownership inference [38] and scalable alias resolution (identifying which interface IP addresses belong to the same routers), which is required to convert the IP-level topology discovered by traceroute to a router-level topology [39]. We have recently used the ITDK to develop new cartographic techniques for inferring naming (DNS) structure [40].
-
Inferred Economic Relationships Between Networks. CAIDA operates a public web service (AS Rank) that allows exploration of routing and business relationships between ISPs (identified as ASes in the routing system) and organizations that own them [41]. The Internet AS-level topology and its dynamics are consequences of business decisions that Internet players make, and accurate knowledge of AS business relationships is relevant to both technical and economic forces driving Internet structure and evolution. AS relationships introduce a non-trivial set of constraints on paths over which Internet traffic can flow, with implications for network robustness, traffic engineering, measurement strategies, and economic modeling of topology. Our AS relationship inference algorithm, which builds on decades of work [42,36], ranks ASes by their customer cone size, which is the number of their direct and indirect customer networks, inferred from public BGP routing data (described above).
-
Security hygiene of networks. In collaboration with U. Waikato, CAIDA has developed open-source tools that enable crowd-sourced measurements of source address validation (SAV) compliance [43,44]. Source address validation is a best practice that protects other networks from spoofed denial-of-service attacks coming from one's own network. Unlike many security best practices that can be measured from anywhere on the network, measurement of SAV on a network requires attempting to transmit an invalid-source addressed packet from that network to the public Internet. We have developed client software that works on Windows, MacOS, and UNIX-like systems, periodically testing a network's ability to both send and receive packets with forged source IP addresses (spoofed packets). This platform helps operators testing their own configurations, and remediation authorities who want to prioritize SAV compliance attention where it will most benefit. We will also pursue sources of Indications of Compromise (IoCs) such as [45], which often include specific IP addresses and DNS hostnames, to identify and analyze networks that host systems that support the spread of malware.
4 Project Plan
4.1 Task 1: Build Team and Define OKN: People, Principles, Purpose
- Statement of purpose, related to improved Internet security, science, and policy.
- A shared theory of change: how the knowledge network can transform scientific studies of the Internet to address national needs.
- Measurement and subsequent articulation of structured semantic knowledge in the network, including evaluating utility of existing data sets, and identifying new ones needed.
- The role of expertise and experimentation within the network to accelerate coordination and learning and cross-fertilization among industry and academics.
- Models of participation and inclusion, including how to capture created knowledge into an online knowledge structure that to some extent automates the knowledge.
- Operating models and convening structures, including workshops described below.
- Development of social norms that generate continuous improvement and incentives to participate, learning from successes of participants in their own knowledge networks.
- Developing metrics of success.
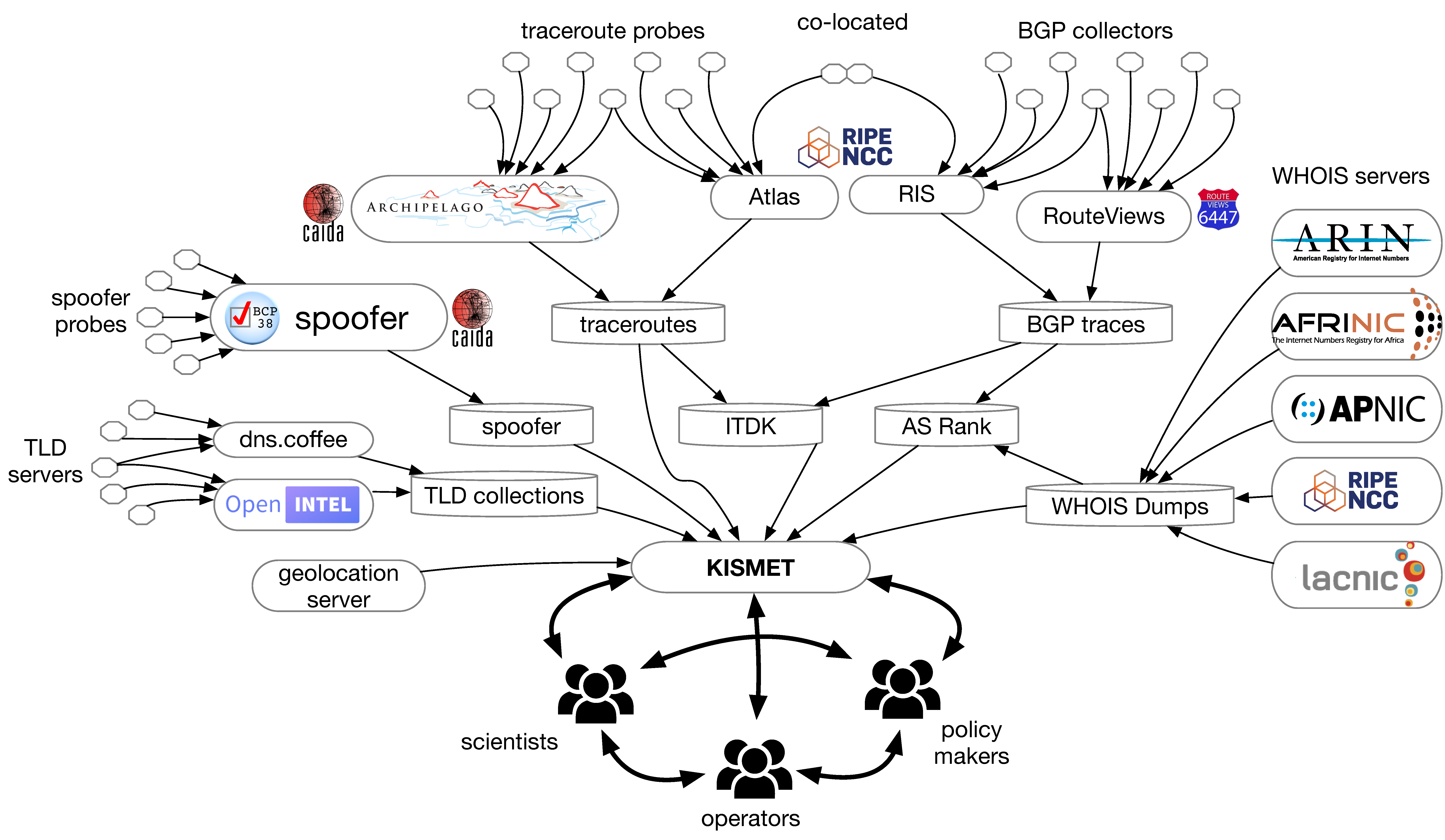
4.2 Task 2: Design KISMET prototype: Patterns, Protocols, Production
- We will start with conceptualizing, and constructing a sample of, a heavily annotated map of the namespace, including zone creation and expiration patterns, bulk registrations, parent/child zone delegation and TTL mismatches, and shared infrastructure that represents a resilience vulnerability.
-
In support of pattern detection, we will design a knowledge graph representation of the space, including analysis and visualization modules information to help detect anomalous patterns in zone files that reflect suspicious registrar or registrant behavior, e.g., orphan DNS nameservers, bulk registrations, delayed registration of domains, and new, changed, or deleted domains/nameservers. This graph should also capture concentration of domains across registrars that are also autonomous systems, such as that shown in Figure 2. Specifically, over half of observed domains in the CZDS data set on 1 May 2019 were hosted by 10 registries, mostly in the U.S. and China. Similarly, OpenIntel measurements using .com and .nl zones revealed that the vast majority of second-level domains in .com have name servers located in a single AS, while almost half of domains in the .nl zone have name servers in at least two ASes. Topological diversity is important to protect against denial-of-service attacks.
-
The most powerful contribution to DNS cartography will be superimposing the DNS resolution topology knowledge graph over an underlying AS-level topology knowledge graph, revealing the ISPs hosting or providing transit for various domains and TLDs (an oversimplification depicted in Figure 3), and even the physical co-location facilities where authoritative nameservers exist. This functionality should also integrate geolocation of IPs and ASNs to reveal further patterns. This will require new visualization techniques and synthesis of graph and relational database technologies.
- Although network-topology cartography is more advanced than DNS cartography, trying to join the two graphs may require an improved ability to gather traceroute measurements from VPs co-located with BGP data. One advantage of the knowledge network will be the ability to use Route Views collectors as vantage points for traceroutes into all the neighbors peering with the collector. Doing so will require development work, specifically modification of scamper [73] to send packets to a supplied Route Views peer. Route Views has agreed to manage their side of this capability with their peers. This development would be transformational for the Internet measurement community: we would no longer need to send hardware to do traceroute measurements - a single Route Views collector box would allow traceroute measurements via all its peering networks, giving us co-located data plane and control (BGP) plan views by default, a challenge for over a decade.
- We will discuss how and whether to study trends in concentration of address space ownership. A May 2019 presentation by Georgia Tech researchers showed that over 60% of IPv4 address space being purchased this year was purchased by Amazon, and much of the rest was purchased by other global cloud providers [74]. In addition, an unknown number of grey market transfers (purchasing and selling) of IPv4 address blocks [75] may be occurring, the study of which would require detecting anomalous changes in topology, DNS, and BGP data to infer address transfers.
- Another reasoning task will be to seek correlations of IP and DNS data and connectivity structure with blacklist and spoofing data to infer properties that seem to hinder or promote cybersecurity preparedness. As one example, we could try to compute a score for every nameserver and IP based on the likelihood that domain is machine generated, and thus more likely used for botnet command and control purposes.
- More fundamentally, the community has no scientific framework for assessing the integrity of blacklists, despite evidence for skepticism [76,77]. Access to more comprehensive DNS and routing data will enable more a rigorous approach to analyzing variations in blacklist feeds based on collection methodology, and their implications.
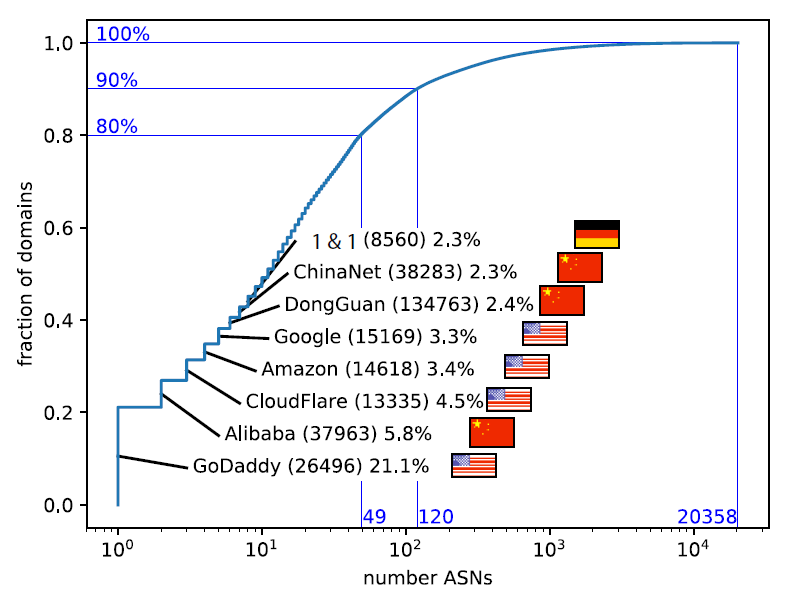 Figure 2.
Figure 2. 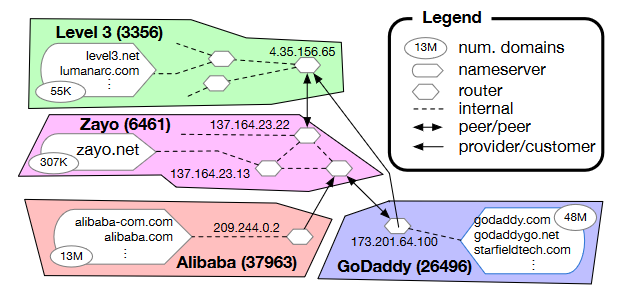
References
- [1]
-
"Emergency Directive 19-01: Mitigate DNS Infrastructure Tampering," Jan. 2019.
- [2]
-
Dan Goodin, "The wave of domain hijackings besetting the Internet is worse than we thought: Despite widespread attention since January, DNS campaign shows no signs of abating.," Apr. 2019. https://arstechnica.com/information-technology/2019/04/state-sponsored-domain-hijacking-op-targets-40-organizations-in-13-countries/.
- [3]
-
Danny Adamitis, David Maynor, Warren Mercer, Matthew Olney and Paul Rascagneres, "DNS Hijacking Abuses Trust In Core Internet Service," Apr. 2019. https://blog.talosintelligence.com/2019/04/seaturtle.html.
- [4]
-
U.S. National Institutes of Standards and Technology, "U.S. NIST Voluntary Cybersecurity Framework," Apr. 2018. https://www.nist.gov/cyberframework.
- [5]
-
Federal Communications Commission, "Communications Security, Reliability and Interoperability Council," 2019. https://www.fcc.gov/about-fcc/advisory-committees/communications-security-reliability-and-interoperability-council-0.
- [6]
-
National Institute of Standards and Technology, "Secure Interdomain Traffic Exchange – Routing Robustness and DDoS Mitigation: NIST Releases Draft NIST SP 800-189," 2018. https://www.nist.gov/news-events/news/2018/12/secure-interdomain-traffic-exchange-routing-robustness-and-ddos-mitigation.
- [7]
-
Brian Cute, "A conversation about evolving the effectiveness of our multistakeholdermodel," Mar. 2019. https://www.icann.org/en/system/files/files/draft-evolving-multistakeholder-model-issues-list-25apr19-en.pdf.
- [8]
-
Internet Corporation for Assigned Names and Numbers, "Board Action on Competition, Consumer Trust, and Consumer Choice Review," Mar. 2019. https://www.icann.org/news/blog/board-action-on-competition-consumer-trust-and-consumer-choice-review.
- [9]
-
ICANN, "Expedited Policy Development Process on the Temporary Specification for gTLD Registration Data," 2018. https://community.icann.org/display/EOTSFGRD/EPDP+on+the+Temporary+Specification+for+gTLD+Registration+Data.
- [10]
-
Technical Study Group on Access to Non-Public Registration Data, led by Ram Mohan (Afilias), 2019. https://www.icann.org/en/system/files/files/draft-technical-model-access-non-public-registration-data-06mar19-en.pdf.
- [11]
-
David Redl, Apr. 2019. https://www.icann.org/en/system/files/correspondence/redl-to-chalaby-04apr19-en.pdf.
- [12]
-
Ian Foster, "dns.coffee." https://dns.coffee/.
- [13]
-
T. Halvorson, K. Levchenko, S. Savage, and G. M. Voelker, "XXXtortion?: inferring registration intent in the .XXX TLD," in Internation Conference on World Wide Web, Apr. 2014.
- [14]
-
T. Halvorson, M. F. Der, I. Foster, S. Savage, L. K. Saul, and G. M. Voelker, "From.academy to.zone: An Analysis of the New TLD Land Rush," in Internet Measurement Conference (IMC), 2015.
- [15]
-
R. van Rijswijk-Deij, M. Jonker, A. Sperotto, and A. Pras, "A High-Performance, Scalable Infrastructure for Large-Scale Active DNS Measurements," IEEE Journal on Selected Areas in Communications, vol. 34, no. 7, 2016.
- [16]
-
"University of Oregon Route Views Project." http://www.routeviews.org/.
- [17]
-
RIPE NCC, "RIPE's Routing Information Service." http://www.ris.ripe.net/.
- [18]
-
Center for Applied Internet Data Analysis, "Archipelago Measurement Infrastructure." https://www.caida.org/projects/ark.
- [19]
-
RIPE NCC, "Global RIPE Atlas Network Coverage.." https://atlas.ripe.net/results/maps/network-coverage/, May 2019.
- [20]
-
http://www.raspberrypi.org/.
- [21]
-
M. Luckie, Y. Hyun, and B. Huffaker, "Traceroute probe method and forward IP path inference," in ACM SIGCOMM Internet measurement Conference (IMC), Oct 2008.
- [22]
-
P. Mérindol, B. Donnet, J.-J. Pansiot, M. Luckie, and Y. Hyun, "MERLIN: MEasure the Router Level of the INternet," in Euro-nf Conference on Next Generation Internet (NGI), June 2011.
- [23]
-
K. Keys, Y. Hyun, M. Luckie, and k. claffy, "Internet-Scale IPv4 Alias Resolution with MIDAR," IEEE/ACM Transactions on Networking, vol. 21, Apr 2013.
- [24]
-
R. Beverly, W. Brinkmeyer, M. Luckie, and J. Rohrer, "IPv6 Alias Resolution via Induced Fragmentation," in Passive and Active Network Measurement Conference (PAM), Mar 2013.
- [25]
-
M. Luckie, R. Beverly, W. Brinkmeyer, and k. claffy, "Speedtrap: Internet-scale ipv6 alias resolution," in ACM SIGCOMM Internet measurement Conference (IMC), Oct 2013.
- [26]
-
P. Marchetta, W. de Donato, and A. Pescapé, "Detecting third-party addresses in traceroute traces with IP timestamp option," in PAM, pp. 21-30, Apr. 2013.
- [27]
-
M. Luckie and k. claffy, "A Second Look at Detecting Third-Party Addresses in Traceroute Traces with the IP Timestamp Option," in Passive and Active Network Measurement Workshop (PAM), vol. 8362, pp. 46-55, Mar 2014.
- [28]
-
R. Beverly, A. Berger, Y. Hyun, and k. claffy, "Understanding the efficacy of deployed Internet source address validation filtering," in ACM SIGCOMM Internet measurement conference (IMC), 2009.
- [29]
-
kc claffy, "CAIDA participation in IPv6 day," June 2011. https://blog.caida.org/best_available_data/2011/06/05/caida-participation-in-ipv6-day/.
- [30]
-
"Vela: On-Demand Topology Measurement Service." https://www.caida.org/projects/ark/vela/.
- [31]
-
Young Hyun, "Henya: large-scale Internet topology query system," 2016. https://www.caida.org/tools/utilities/henya/.
- [32]
-
B. Huffaker, K. Keys, M. Fomenkov, and K. Claffy, "AS-to-Organization Dataset." https://www.caida.org/archive/as2org.
- [33]
-
Center for Applied Internet Data Analysis (CAIDA), "Prefix to AS mappings." https://www.caida.org/catalog/datasets/routeviews-prefix2as/.
- [34]
-
Center for Applied Internet Data Analysis (CAIDA), "AS links." https://www.caida.org/catalog/datasets/ipv4_routed_topology_aslinks_dataset.
- [35]
-
Center for Applied Internet Data Analysis (CAIDA), "AS Taxonomy." https://catalog.caida.org/dataset/2006_pam_as_taxonomy.
- [36]
-
CAIDA, "AS links annotated with AS relationships dataset." https://www.caida.org/catalog/datasets/as-relationships.
- [37]
-
CAIDA's Macroscopic Internet Topology Data Kit (ITDK). https://www.caida.org/catalog/datasets/internet-topology-data-kit/.
- [38]
-
B. Huffaker, A. Dhamdhere, M. Fomenkov, and k. claffy, "Toward topology dualism: Improving the accuracy of AS annotations for routers," in Passive and Active Network Measurement Conference (PAM), Apr. 2010.
- [39]
-
K. Keys, "Internet-Scale IP Alias Resolution Techniques," ACM SIGCOMM Computer Communication Review (CCR), vol. 40, pp. 50-55, Jan 2010.
- [40]
-
M. Luckie, B. Huffaker, and k. claffy, "Learning regexes for router names in hostnames," in in submission, May 2019.
- [41]
-
Center for Applied Internet Data Analysis (CAIDA), "As rank." http://asrank.caida.org/.
- [42]
-
M. Luckie, B. Huffaker, A. Dhamdhere, V. Giotsas, and k. claffy, "AS Relationships, Customer Cones, and Validation," in ACM SIGCOMM Internet Measurement Conference (IMC), Oct 2013.
- [43]
-
P. Ferguson and D. Senie, "Network ingress filtering: Defeating denial of service attacks which employ IP source address spoofing," May 2000. IETF BCP38.
- [44]
-
F. Baker and P. Savola, "Ingress filtering for multihomed networks," Mar. 2004. IETF BCP84.
- [45]
-
abuse.ch, "abuse.ch." https://abuse.ch/.
- [46]
-
"What is a Science Gateways: The Basics ." https://sciencegateways.org/new-to-gateways.
- [47]
-
Yoo, Christopher S. and Wishnick, David A., "Lowering Legal Barriers to RPKI Adoption," Faculty Scholarship at Penn Law, 2019. https://scholarship.law.upenn.edu/faculty_scholarship/2035.
- [48]
-
Josephine Wolff, You'll see this message when it is too late: The Legal and Economic Aftermath of Cybersecurity Breaches. MIT Press, 2018.
- [49]
-
M. Luckie, A. Dhamdhere, B. Huffaker, D. Clark, and k. claffy, "bdrmap: Inference of Borders Between IP Networks," in Internet Measurement Conference (IMC), Nov 2016.
- [50]
-
A. Marder, M. Luckie, A. Dhamdhere, B. Huffaker, J. Smith, and k. claffy, "Pushing the Boundaries with bdrmapIT: Mapping Router Ownership at Internet Scale," in Internet Measurement Conference (IMC), pp. 56-69, Nov 2018.
- [51]
-
Katrina Pugh and Laurence Prusak, Designing Effective Knowledge Networks. Oct. 2013. https://www.oreilly.com/library/view/designing-effective-knowledge/53863MIT55122/.
- [52]
-
"Open Knowledge Network: Summary of the Big Data IWG Workshop," Nov. 2018.
- [53]
-
k. claffy, M. Fomenkov, E. Katz-Bassett, R. Beverly, B. Cox, and M. Luckie, "The Workshop on Active Internet Measurements (AIMS) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 39, Oct 2009.
- [54]
-
kc claffy, E. Aben, J. Augé, R. Beverly, F. Bustamante, B. Donnet, T. Friedman, M. Fomenkov, P. Haga, M. Luckie, and Y. Shavitt, "The 2nd Workshop on Active Internet Measurements (AIMS-2) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 40, Oct. 2010.
- [55]
-
kc claffy, "The 3rd Workshop on Active Internet Measurements (AIMS-3) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 41, July 2011.
- [56]
-
kc claffy, "The 4th Workshop on Active Internet Measurements (AIMS-4) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 42, Jul 2012.
- [57]
-
kc claffy, "The 5th Workshop on Active Internet Measurements (AIMS-5) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 43, Jul 2013.
- [58]
-
kc claffy, "The 6th Workshop on Active Internet Measurements (AIMS-6) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 44, Oct 2014.
- [59]
-
kc claffy, "The 7th Workshop on Active Internet Measurements (AIMS-7) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 46, Jan 2015. https://catalog.caida.org/paper/2016_aims2015_report.
- [60]
-
kc claffy, "The 8th Workshop on Active Internet Measurements (AIMS-8) Report," ACM SIGCOMM Computer Communication Review (CCR), Oct 2016. https://catalog.caida.org/paper/2016_aims2016_report.
- [61]
-
kc claffy, "The 9th Workshop on Active Internet Measurements (AIMS-8) Report," ACM SIGCOMM Computer Communication Review (CCR), Oct 2017. https://catalog.caida.org/paper/2017_aims2017_report.
- [62]
-
kc claffy, "The 10th Workshop on Active Internet Measurements (AIMS-8) Report," ACM SIGCOMM Computer Communication Review (CCR), Oct 2018. https://catalog.caida.org/paper/2018_aims2018_report.
- [63]
-
kc claffy, "The 11th Workshop on Active Internet Measurements (AIMS-8) Report," ACM SIGCOMM Computer Communication Review (CCR), forthcoming. https://catalog.caida.org/paper/2019_aims2019_report.
- [64]
-
k. claffy, "Workshop on Internet Economics (WIE2011) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 40, Apr 2010.
- [65]
-
k. claffy, "Workshop on Internet Economics (WIE2011) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 42, pp. 110-114, Apr 2012.
- [66]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2012) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 43, pp. 95-100, Jul 2013.
- [67]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2013) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 44, pp. 116-119, Jul 2014.
- [68]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2014) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 45, pp. 43-48, Jul 2015.
- [69]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2015) Report," ACM SIGCOMM Computer Communication Review (CCR), Jul 2016.
- [70]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2015) Report," ACM SIGCOMM Computer Communication Review (CCR), Jul 2017.
- [71]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2015) Report," ACM SIGCOMM Computer Communication Review (CCR), Jul 2018.
- [72]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2015) Report," ACM SIGCOMM Computer Communication Review (CCR), Jan 2019.
- [73]
-
M. Luckie, "Scamper: a scalable and extensible packet prober for active measurement of the Internet," in ACM SIGCOMM Internet Measurement Conference (IMC), 2010.
- [74]
-
Brenden Kuerbis and Milton Mueller, "Get Ready for a Mixed World: Economic Factors Affecting IPv6 Deployment." https://ripe78.ripe.net/presentations/21-RIPE-Get-Ready-for-a-Mixed-World_-Economic-Factors-Affecting-IPv6-Deployment.pdf, presented at RIPE meeting.
- [75]
-
I. Livadariu, A. Elmokashfi, A. Dhamdhere, and kc claffy, "A first look at IPv4 transfer markets," in CoNEXT, 2013.
- [76]
-
A. Pitsillidis, C. Kanich, G. M. Voelker, K. Levchenko, and S. Savage, "Taster's Choice: A Comparative Analysis of Spam Feeds," in Proceedings of the 2012 Internet Measurement Conference, IMC '12, (New York, NY, USA), pp. 427-440, ACM, 2012.
- [77]
- L. Metcalf and J. M. Spring, "Blacklist ecosystem analysis: Spanning jan 2012 to jun 2014," in Proceedings of the 2Nd ACM Workshop on Information Sharing and Collaborative Security, WISCS '15, (New York, NY, USA), pp. 13-22, ACM, 2015.
Footnotes:
File translated from TEX by TTH, version 4.03.
On 13 Sep 2019, 23:17.