

DIBBs: Integrated Platform for Applied Network Data Analysis (PANDA): Proposal
An abbreviated version of the original proposal is shown below. For the full proposal for "DIBBs: Integrated Platform for Applied Network Data Analysis (PANDA)", please see the proposal in PDF.
Sponsored by:
")
Principal Investigators: kc claffy Bradley Huffaker Alberto DainottiAmogh DhamdhereAlistair King
Funding source: OAC-1724853 Period of performance: September 1, 2017 - August 31, 2022.
1 Introduction: Expanding the Reach and Impact of Internet Infrastructure Data
2 Existing Data Building Blocks to Integrate
2.1 Archipelago Active Internet Measurement Platform and Supporting Components
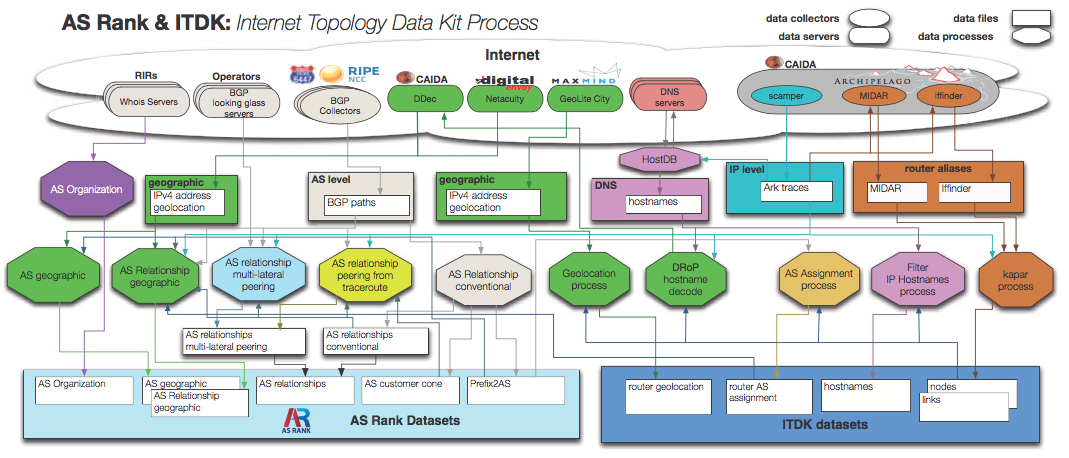
Figure 1: Internet topology data measurement, mining, and analysis lifecycle process for data CAIDA collects and/or curates. PANDA will strive for a more consistent and user-friendly accessible interface to these data sets.
2.2 AS Rank: Comparison of routing and economic relationships among ISPs
2.3 BGPStream: efficient framework for routing (BGP) data analysis
2.4 Periscope: Extending measurement coverage by leveraging operational infrastructure
2.5 MANIC: Mapping and Analysis of Interdomain Congestion
With shifting market power in the Internet ecosystem, links connecting access providers to their peers, transit providers and major content providers have become a potential point of discriminatory treatment. While the FCC has regulatory authority over those links, they have acknowledged they lack sufficient expertise to develop appropriate regulations thus far.2 As part of a NeTS project (§7), we developed a system to measure and analyze congestion on interconnection links [48]. The core idea of our technique is to send (TTL-limited) probes from a vantage point (VP) within a network, toward the near and the far end of an interdomain (border) link of that network, and to monitor diurnal patterns in the near and far-side time series. A persistently elevated RTT to the far end of the link, but no corresponding RTT elevation to the near side, is a signal of congestion at the interdomain link. The more daunting challenge is to identify these interdomain border links via active measurements from the edge of a network, which we also tackled for this project, with our current method implemented in our open-source bdrmap tool [49].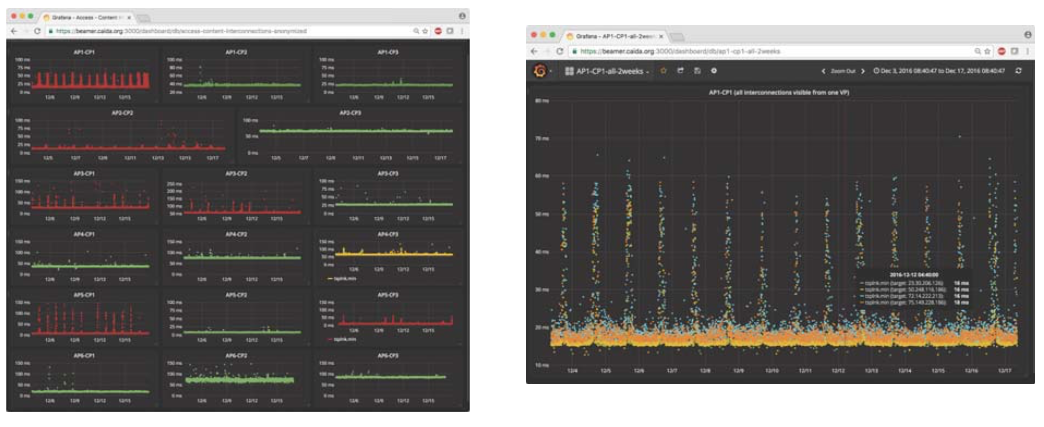
Figure 2: PANDA will enable linking of MANIC data with current topology data to allow querying of specific links in the topology, or visibility of topology surrounding link displayed in a specific graph.
2.6 Spoofer: Assessment of IP address validation best practices
3 Task 1: PANDA: Platform for Applied Network Data Analysis
3.1 Software development to scale performance and functionality for community use
-
Re-architect AS Rank to use HPC resources on the back end to improve scalability and performance. AS Rank has trouble meeting current demands, especially when professors decide to use it for interactive classroom use.5 We will re-architect AS Rank from the ground up to use XSEDE resources on the back end to support parallelization of real-time calculations on large topology graphs (hundreds of thousands of links). This task will include developing new intelligent indexing schemes such as those used in Henya (for IP-level path information) to create a highly efficient AS path database backend. A more efficient, HPC-based design will allow computations not possible with the current system, e.g., show all paths visible for a given AS, show which observed paths informed a given relationship inference. It will also allow tracking changes to AS paths, relationships, and customer cone sizes over time. We will extend the database to compute and store not just the size of a customer cone, but the set of ASes in the cone, to enable comparisons of customer cone diversity across providers and regions. Finally, we will improve AS-level visualizations to highlight structure from the perspective of a given AS, which users find engaging.
-
Unify scalable border mapping techniques. In collaboration with UPenn, we will combine mapping techniques from our own bdrmap [49] and UPenn's MAP-IT [56] tools (both recently published in the same session at IMC). This development will allow us to create a unified border mapping module which researchers can interactively run on large archives of traceroute data, including RIPE Atlas and Periscope, to increase observation of locally scoped peering.
-
Scale up the MANIC functionality to integrate additional vantage points, border mapping, and geolocation capabilities. The MANIC platform currently uses Ark vantage points to measure congestion on interdomain links of a network from within that network. MANIC's archive of performance data is currently at 8TB of data, increasing at about 100GB/month, but interest in expanding this platform will amplify this growth. We will integrate Periscope and RIPE Atlas vantage points to provide a view of an interconnection link from the other direction, or in some cases to allow comparative views of a given interconnect from different locations. Even more exciting, the U.S. FCC has also asked us (but has no funding to support) to expand our data collection infrastructure to include the FCC-SamKnows (Measure Broadband America) deployment of home routers, which provides thousands of additional VPs in the U.S. from which to measure interconnection. This expansion would increase storage requirements to 1TB/month. Additionally we will integrate geolocation information to enable systematic analysis of congestion inferences between networks [57], including integration of our facility-level information [45], i.e., in which building an interconnection occurs. We will rearchitect the influxDB database instance to work on a cluster of XSEDE nodes, so that it can scale to multiple cores and support many concurrent users and queries. Fortunately, the tens of thousands of time-series we accumulate by measuring performance across each observed interconnect are highly amenable to parallelization.
3.2 Create software modules to link components to each other and external software
-
Implement links between archived and real-time measurements, and between AS-level and IP-level measurements. As Archipelago evolves6 we will enable users to easily transition from querying archived measurements to requesting on-demand measurements in real-time, or vice-versa. That is, users will be able to compare historical to current characteristics of paths. We will also add support to link an IP-level view to an ISP (AS)-level view, so that when one executes a measurement, it will be easy to see all archived and derivative data related to all networks crossed across the probed path.
-
Integrate the use of BGPStream consistently for all of PANDA's components. We will implement bindings to the main BGPStream C library to facilitate use by external software modules, e.g., for route hijacking and outage detection. We will make available distribution-specific packages to simplify installation, including Ubuntu, Debian, FreeBSD, and CentOS.
-
Enable Periscope to leverage other software platforms. For faster resource allocation, tighter control of network resources, and resilience to failures, we will enable Periscope to use both Ark and RIPE Atlas nodes as part of its querying underlay. Intelligent allocation of querying can conserve the Periscope querying budget for use with measurements that only its underlying LGs can satisfy, We will also integrate Periscope as a BGPStream broker [35] to enable consumption of Periscope BGP data through the BGPStream APIs.7
-
Cross-correlate MANIC data output to other measurement projects and data sets. Policy makers who interpret congestion data also care about the business relationships between ASes. We will integrate AS-relationship data from our AS-rank system to allow users to slice the congestion data according to the inferred business relationship between networks. Other projects are collecting different sorts of data that can provide evidence of performance degradations [57], e.g. the video quality reports and throughput/latency measurements from the FCC Measuring Broadband America platform [58]. We will explore how to compare such data sets to enrich our view of interconnection, while also making the data more accessible and usable to researchers and policy makers.
3.3 Increase community accessibility of unified platform and underlying components

Figure 3: Mockup of Panda interface. Users would start with screen A , enter a query, and progress to a context-based screen based on query type, e.g., if they specify AS 174, they will see an interface similar to B. Underlined words represent hyperlinks to pages with additional details. For example B's congestion 6 link (lower right of B) would take the user to screen D which would show information for congestion on six links observed by PANDA components.
-
Improve usability of the ITDK. Based on feedback from several of the target communities, we will create a simplified version that removes complex artifacts in the data, e.g., multiple origin ASes, AS loops and sets, hyperlinks [31], in order to render it amenable to processing by basic graph database tools. We will provide documentation to explain inferential implications of the simplifications. We will also create an "economist-friendly" version annotating the data in different ways (company names in addition to network numbers) to support economics and policy use of the data.
- On request, provide data products in additional easier-to-use, domain-specific formats; for example, JSON, standard graph formats, and input formats of network simulators. We may either offer our data converted to these forms or provide custom tools for doing so and thus reduce the impedance mismatch that currently hinders data exchange and research.
-
Create user-friendly interface to source address validation (SAV) compliance information accessible to operators and policy-makers via the PANDA gateway. First, we will integrate published information on which networks are present at each IXP to report the SAV compliance state of networks at the IXPs where we have test results. This information will allow IXP members to adopt defensive practices against non-compliant networks if it chooses to be present at the IXP. Second, we will integrate public BGP information on the stability of edge network address space, to enable analysis of the feasibility of deploying static access control lists as a form of compliance with SAV best practices. [53].8
4 Task 2: Support for and collaboration with multiple disciplines
-
Dedicated staff time to support collaborations with economists and policymakers. We have allotted significant staff and PI time to enrich existing and generate new collaborations among policy analysts, economists and measurement experts, and using these collaborations to evolve the design of user interface components of PANDA to better serve those targeted communities.
-
Workshops focused on engagement with PANDA system. Our two annual workshop series - AIMS in its 8th year and WIE its 7th - have established solid communities of collaborators in technical and social science fields, respectively. The Active Internet Measurement Systems workshop series (funded through Feb 2018 by CRI) is a forum for stakeholders in Internet active measurement projects, typically networking and security researchers, to explore technical and policy challenges and opportunities to maximize the scientific and operational benefit of deployed infrastructure and gathered measurements [62,63,64,65,66,67,68,69]. The Workshop on Internet Economics (WIE) series brings together researchers, Internet service providers (ISPs), economists, regulators, lawyers, and other stakeholders to inform and debate current and emerging policy issues [70,71,72,73,74,75]. We will expand these workshop series, and promote more cross-fertilization and collaboration across the communities. We will use these workshops to stimulate use of
PANDA in multi-disciplinary collaborations, introduce new capabilities of PANDA, including hands-on tutorials to engage users, and share experiences with classroom use of PANDA.
- We will distribute a written survey, at the workshops and via a larger panda-interest at caida.org community email list, soliciting feedback on presented capabilities and plans, and publish anonymized summaries of the surveys each year. We will also socialize the new platform at other community workshops and conferences where the lack of empirical data is a recognized gap.
- We will develop and maintain an online community resource of material, including tutorials on how to use PANDA and its components, summaries of data-gathering efforts from different stakeholders, and a wiki/forum for independent analyses of (sometimes contradicting) results of these studies, their limitations and implications for research on measurement, economics, policy, and future network architectures. We will specifically target a portion of this resource for integration into course curriculum and student projects.
- An external advisory board led by David Clark at MIT will enrich linkages between PANDA and targeted communities, identify emerging national and international issues that merit empirical attention, and suggest data sets and analysis to inform policy-making. This board will pursue vehicles such as NSF's RCN program to support outreach to other communities, e.g., TPRC, and will develop paths to sustainability beyond the DIBBS project, including possible foundation support.
5 Task 3: Extensibility and adaptation to new opportunities
Comprehensive DNS measurements.
In the OpenINTEL project, jointly
operated by SURFnet and SIDN Labs, researchers from the Univeristy
of Twente (Netherlands) conduct large scale active measurements of
the global Domain Name System (DNS) [76] collecting daily snapshots
that currently cover over 60% of the DNS name space. By adding such
comprehensive DNS data to PANDA, it will become possible to associate
network behavior observed at the IP protocol level with the human
view of the Internet in the form of domain names. This new capability
will enable all targeted communities to accelerate inquiry as well as
pursue new questions (since DNS data can change over time and
researchers have no other means to map historical topology data to
historical DNS data from the same time).
6 Benefits to Research Communities
6.1 Networking Research Community
6.2 Security and Stability Research Community
6.3 Economics Research Community
6.4 Public policy and legal research community
6.5 Collaborations and Synergies among Communities
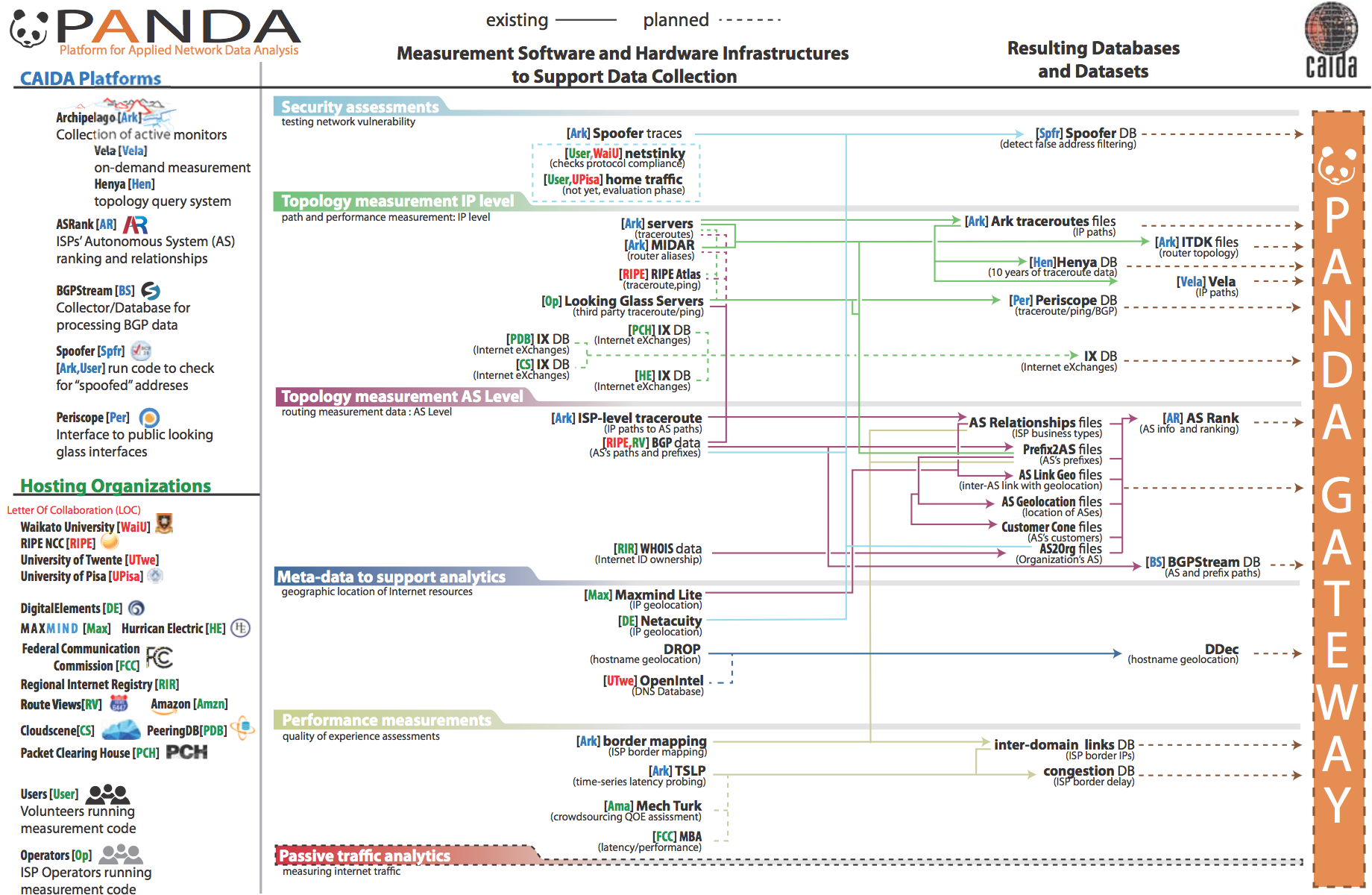
Figure 4: PANDA project components: data infrastructure building blocks
References
- [1]
-
National Science Foundation, "A Vision and Strategy for software for science, engineering, and education cyberinfrastructure framework for the 21st century," 2012. NSF 12-113.
- [2]
-
"CAIDA Tools - Overview of CAIDA Software Tools." https://catalog.caida.org/software.
- [3]
-
Overview of CAIDA's Data. https://catalog.caida.org/search?query=types=dataset%20caida.
- [4]
-
Center for Applied Internet Data Analysis, "Archipelago Measurement Infrastructure." https://www.caida.org/projects/ark.
- [5]
-
Center for Applied Internet Data Analysis, "Macroscopic Topology Measurements." Research Project. https://www.caida.org/projects/macroscopic/.
- [6]
-
http://www.raspberrypi.org/.
- [7]
-
M. Luckie, Y. Hyun, and B. Huffaker, "Traceroute probe method and forward IP path inference," in ACM SIGCOMM Internet measurement Conference (IMC), Oct 2008.
- [8]
-
P. Mérindol, B. Donnet, J.-J. Pansiot, M. Luckie, and Y. Hyun, "MERLIN: MEasure the Router Level of the INternet," in Euro-nf Conference on Next Generation Internet (NGI), June 2011.
- [9]
-
K. Keys, Y. Hyun, M. Luckie, and k. claffy, "Internet-Scale IPv4 Alias Resolution with MIDAR," IEEE/ACM Transactions on Networking, vol. 21, Apr 2013.
- [10]
-
R. Beverly, W. Brinkmeyer, M. Luckie, and J. Rohrer, "IPv6 Alias Resolution via Induced Fragmentation," in Passive and Active Network Measurement Conference (PAM), Mar 2013.
- [11]
-
M. Luckie, R. Beverly, W. Brinkmeyer, and k. claffy, "Speedtrap: Internet-scale ipv6 alias resolution," in ACM SIGCOMM Internet measurement Conference (IMC), Oct 2013.
- [12]
-
P. Marchetta, W. de Donato, and A. Pescapé, "Detecting third-party addresses in traceroute traces with IP timestamp option," in PAM, pp. 21-30, Apr. 2013.
- [13]
-
M. Luckie and k. claffy, "A Second Look at Detecting Third-Party Addresses in Traceroute Traces with the IP Timestamp Option," in Passive and Active Network Measurement Workshop (PAM), vol. 8362, pp. 46-55, Mar 2014.
- [14]
-
R. Beverly, A. Berger, Y. Hyun, and k. claffy, "Understanding the efficacy of deployed Internet source address validation filtering," in ACM SIGCOMM Internet measurement conference (IMC), 2009.
- [15]
-
kc claffy, "CAIDA participation in IPv6 day," June 2011. https://blog.caida.org/best_available_data/2011/06/05/caida-participation-in-ipv6-day/.
- [16]
-
"Vela: On-Demand Topology Measurement Service." https://www.caida.org/projects/ark/vela/.
- [17]
-
Center for Applied Internet Data Analysis (CAIDA), "The IPv4 Routed /24 Topology Dataset." https://www.caida.org/catalog/datasets/ipv4_routed_24_topology_dataset/.
- [18]
-
Young Hyun, "Henya: large-scale Internet topology query system," 2016. https://www.caida.org/tools/utilities/henya/.
- [19]
-
B. Huffaker, K. Keys, M. Fomenkov, and K. Claffy, "AS-to-Organization Dataset." https://www.caida.org/archive/as2org.
- [20]
-
Y. Hyun, "Henya: CAIDA's Internet Topology Query System Tool," 2016. https://www.youtube.com/watch?v=jg7CgLCMtgY.
- [21]
-
Center for Applied Internet Data Analysis (CAIDA), "AS links." https://www.caida.org/catalog/datasets/ipv4_routed_topology_aslinks_dataset.
- [22]
-
Center for Applied Internet Data Analysis (CAIDA), "Prefix to AS mappings." https://www.caida.org/catalog/datasets/routeviews-prefix2as/.
- [23]
-
Center for Applied Internet Data Analysis (CAIDA), "AS Taxonomy." https://catalog.caida.org/dataset/2006_pam_as_taxonomy.
- [24]
-
CAIDA, "AS links annotated with AS relationships dataset." https://www.caida.org/catalog/datasets/as-relationships.
- [25]
-
CAIDA's Macroscopic Internet Topology Data Kit (ITDK). https://www.caida.org/catalog/datasets/internet-topology-data-kit/.
- [26]
-
B. Huffaker, A. Dhamdhere, M. Fomenkov, and k. claffy, "Toward topology dualism: Improving the accuracy of AS annotations for routers," in Passive and Active Network Measurement Conference (PAM), Apr. 2010.
- [27]
-
K. Keys, "Internet-Scale IP Alias Resolution Techniques," ACM SIGCOMM Computer Communication Review (CCR), vol. 40, pp. 50-55, Jan 2010.
- [28]
-
H. Madhyastha, T. Isdal, M. Piatek, C. Dixon, T. Anderson, A. Krishnamurthy, and A. Venkataramani, "iPlane: an information plane for distributed services," in Symposium on Operating Systems Design and Implementation (OSDI), 2006.
- [29]
-
R. Oliveira, "UCLA's IRL Internet Topology Collection," July 2009. http://irl.cs.ucla.edu/topology/.
- [30]
-
P. Mahadevan, D. Krioukov, M. Fomenkov, B. Huffaker, X. Dimitropoulos, and kc claffy, "Lessons from three views of the internet topology: Technical report," tech. rep., UC, San Diego, 2005. https://catalog.caida.org/paper/2005_tr_2005_02.
- [31]
-
B. Huffaker, M. Fomenkov, and k. claffy, "Internet Topology Data Comparison," tech. rep., Center for Applied Internet Data Analysis (CAIDA), May 2012.
- [32]
-
B. Huffaker, M. Fomenkov, and k. claffy, "Statistical implications of augmenting a BGP-inferred AS-level topology with traceroute-based inferences - Technical Report," tech. rep., Center for Applied Internet Data Analysis (CAIDA), Nov 2016.
- [33]
-
Center for Applied Internet Data Analysis (CAIDA), "As rank." https://asrank.caida.org/.
- [34]
-
M. Luckie, B. Huffaker, A. Dhamdhere, V. Giotsas, and k. claffy, "AS Relationships, Customer Cones, and Validation," in ACM SIGCOMM Internet Measurement Conference (IMC), Oct 2013.
- [35]
-
C. Orsini, A. King, D. Giordano, V. Giotsas, and A. Dainotti, "BGPStream: a software framework for live and historical BGP data analysis," in Internet Measurement Conference (IMC), Nov 2016.
- [36]
-
CAIDA, "CAIDA BGP Hackathon 2016." https://www.caida.org/workshops/bgp-hackathon/1602/.
- [37]
-
B. Zhang, R. Liu, D. Massey, and L. Zhang, "Collecting the Internet AS-level Topology," ACM SIGCOMM CCR, vol. 35, Jan. 2005.
- [38]
-
B. Augustin, B. Krishnamurthy, and W. Willinger, "IXPs: mapped?," in Proceedings of the 9th ACM SIGCOMM conference on Internet measurement conference, IMC '09, pp. 336-349, 2009.
- [39]
-
Y. He, G. Siganos, M. Faloutsos, and S. Krishnamurthy, "Lord of the Links: A Framework for Discovering Missing Links in the Internet Topology," IEEE/ACM Transactions on Networking, vol. 17, no. 2, pp. 391-404, 2009.
- [40]
-
A. Khan, T. Kwon, H.-c. Kim, and Y. Choi, "AS-level Topology Collection Through Looking Glass Servers," in IMC '13, 2013.
- [41]
-
V. Giotsas, S. Zhou, M. Luckie, and k. claffy, "Inferring Multilateral Peering," in CoNEXT '13, 2013.
- [42]
-
X. Shi, Y. Xiang, Z. Wang, X. Yin, and J. Wu, "Detecting Prefix Hijackings in the Internet with Argus," in IMC '12, 2012.
- [43]
-
V. Giotsas, "Periscope: tool and API," 2016. https://catalog.caida.org/software/periscope.
- [44]
-
V. Giotsas, A. Dhamdhere, and k. claffy, "Periscope: Unifying Looking Glass Querying," in Passive and Active Network Measurement Workshop (PAM), Mar 2016.
- [45]
-
V. Giotsas, G. Smaragdakis, B. Huffaker, M. Luckie, and k. claffy, "Mapping Peering Interconnections to a Facility," in ACM SIGCOMM Conference on emerging Networking EXperiments and Technologies (CoNEXT), Dec 2015.
- [46]
-
K. Claffy, A. Dhamdhere, D. Clark, and S. Bauer, "First amended report of at&t independent measurement expert: Reporting requirements and measurement methods," August 2016. https://ecfsapi.fcc.gov/file/108042516812991/MB\%20Dkt\%2014-90\%20AT&T\%20Inc.\%20First\%20Amended\%20IME\%20Report\%20ECFS.PDF, also available at https://catalog.caida.org/.
- [47]
-
kc claffy, "Measuring internet interconnection performance metrics: an exercise to inform public policy," February 2016. https://catalog.caida.org/presentation/2016_measuring_internet_interconnection_nanog.
- [48]
-
Matthew Luckie and Amogh Dhamdhere and David Clark and Bradley Huffaker and kc claffy, "Challenges in Inferring Internet Interdomain Congestion," in ACM SIGCOMM Internet measurement Conference (IMC), 2014.
- [49]
-
M. Luckie, A. Dhamdhere, B. Huffaker, D. Clark, and k. claffy, "bdrmap: Inference of Borders Between IP Networks," in Internet Measurement Conference (IMC), Nov 2016.
- [50]
-
S. Sundaresan, S. Burnett, N. Feamster, and W. De Donato, "BISmark: a testbed for deploying measurements and applications in broadband access networks," in USENIX Annual Technical Conference (USENIX ATC 14), 2014.
- [51]
-
Matthew Luckie, Ken Keys, Ryan Koga, Rob Beverly, kc claffy, "Spoofer source address validation measurement system," 2016. http://spoofer.caida.org.
- [52]
-
P. Ferguson and D. Senie, "Network ingress filtering: Defeating denial of service attacks which employ IP source address spoofing," May 2000. IETF BCP38.
- [53]
-
F. Baker and P. Savola, "Ingress filtering for multihomed networks," Mar. 2004. IETF BCP84.
- [54]
-
E. Kenneally and K. Claffy, "Dialing Privacy and Utility: A Proposed Data-sharing Framework to Advance Internet Research," IEEE Security and Privacy (S&P), July 2010.
- [55]
-
C. for Applied Internet Data Analysis, "UCSD Network Telescope," 2010. https://www.caida.org/data/passive/network_telescope.
- [56]
-
A. Marder and J. M. Smith, "Map-it: Multipass accurate passive inferences from traceroute," in Proceedings of the 2016 ACM on Internet Measurement Conference, IMC '16, ACM, 2016.
- [57]
-
k. claffy, D. Clark, S. Bauer, and A. Dhamdhere, "Policy challenges in mapping Internet interdomain congestion," in Telecommunications Policy Research Conference (TPRC), Oct 2016.
- [58]
-
"Measuring Broadband America.." https://www.fcc.gov/general/measuring-broadband-america.
- [59]
-
"Science Gateways Community Institute." https://sciencegateways.org/.
- [60]
-
"What is a Science Gateways: The Basics ." https://sciencegateways.org/new-to-gateways.
- [61]
-
B. Huffaker, "Interactive Access to Internet Topology Data," 2016. https://catalog.caida.org/presentation/2016_interactive_access_internet_topology_gateways.
- [62]
-
k. claffy, M. Fomenkov, E. Katz-Bassett, R. Beverly, B. Cox, and M. Luckie, "The Workshop on Active Internet Measurements (AIMS) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 39, Oct 2009.
- [63]
-
kc claffy, E. Aben, J. Augé, R. Beverly, F. Bustamante, B. Donnet, T. Friedman, M. Fomenkov, P. Haga, M. Luckie, and Y. Shavitt, "The 2nd Workshop on Active Internet Measurements (AIMS-2) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 40, Oct. 2010.
- [64]
-
kc claffy, "The 3rd Workshop on Active Internet Measurements (AIMS-3) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 41, July 2011.
- [65]
-
kc claffy, "The 4th Workshop on Active Internet Measurements (AIMS-4) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 42, Jul 2012.
- [66]
-
kc claffy, "The 5th Workshop on Active Internet Measurements (AIMS-5) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 43, Jul 2013.
- [67]
-
kc claffy, "The 6th Workshop on Active Internet Measurements (AIMS-6) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 44, Oct 2014.
- [68]
-
kc claffy, "The 7th Workshop on Active Internet Measurements (AIMS-7) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 46, Jan 2015. https://catalog.caida.org/paper/2016_aims2015_report.
- [69]
-
kc claffy, "The 8th Workshop on Active Internet Measurements (AIMS-8) Report," ACM SIGCOMM Computer Communication Review (CCR), Oct 2016. https://catalog.caida.org/paper/2016_aims2016_report.
- [70]
-
k. claffy, "Workshop on Internet Economics (WIE2011) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 40, Apr 2010.
- [71]
-
k. claffy, "Workshop on Internet Economics (WIE2011) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 42, pp. 110-114, Apr 2012.
- [72]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2012) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 43, pp. 95-100, Jul 2013.
- [73]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2013) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 44, pp. 116-119, Jul 2014.
- [74]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2014) Report," ACM SIGCOMM Computer Communication Review (CCR), vol. 45, pp. 43-48, Jul 2015.
- [75]
-
k. claffy and D. Clark, "Workshop on Internet Economics (WIE2015) Report," ACM SIGCOMM Computer Communication Review (CCR), Jul 2016.
- [76]
-
R. van Rijswijk-Deij, M. Jonker, A. Sperotto, and A. Pras, "A High-Performance, Scalable Infrastructure for Large-Scale Active DNS Measurements," IEEE Journal on Selected Areas in Communications, vol. 34, no. 7, 2016.
- [77]
-
U. Pisa, "NTOP traffic monitoring software." ntop.org.
- [78]
-
"CAIDA Annual Report," 2015. https://www.caida.org/about/annualreports/2015/#data.
- [79]
-
Center for Applied Internet Data Analysis (CAIDA), "Papers Published (by non-CAIDA Authors Using CAIDA Datasets." https://www.caida.org/data/publications/.
- [80]
-
"CAIDA papers." https://www.caida.org/publications/.
- [81]
-
G. Nomikos and X. A. Dimitropoulos, "traIXroute: Detecting IXPs in traceroute paths," in PAM, 2016.
- [82]
-
I. Cunha, R. Teixeira, D. Veitch, and C. Diot, "Predicting and tracking Internet path changes," in ACM SIGCOMM, 2011.
- [83]
-
U. Javed, I. Cunha, D. R. Choffnes, E. Katz-Bassett, T. Anderson, and A. Krishnamurthy, "PoiRoot: Investigating the root cause of interdomain path changes," in ACM SIGCOMM, August 2013.
- [84]
-
E. Katz-Bassett, C. Scott, D. R. Choffnes, I. Cunha, V. Valancius, N. Feamster, H. V. Madhyastha, T. E. Anderson, and A. Krishnamurthy, "LIFEGUARD: practical repair of persistent route failures," in ACM SIGCOMM, 2012.
- [85]
-
Y. Shavitt and N. Zilberman, "Improving IP Geolocation by Crawling the Internet PoP Level Graph," in Networking, 2013.
- [86]
-
Y. Shavitt and N. Zilberman, "A Structural Approach for PoP Geolocation," Proceedings of the 2010 IEEE INFOCOM Conference, 2010.
- [87]
-
A. H. Rasti, N. Magharei, R. Rejaie, and W. Willinger, "Eyeball ASes: from geography to connectivity," in ACM SIGCOMM Internet Measurement Conference (IMC), 2010.
- [88]
-
Z. Hu and J. Heidemann, "Towards Geolocation of Millions of IP Addresses," in ACM SIGCOMM Internet Measurement Conference (IMC), 2012.
- [89]
-
Y. Wang, D. Burgener, M. Flores, A. Kuzmanovic, and C. Huang, "Towards street-level client-independent IP geolocation," in USENIX Symposium on Networked Systems Design & Implementation (NSDI), 2011.
- [90]
-
B. Huffaker, M. Fomenkov, and kc claffy, "Geocompare: a comparison of public and commercial geolocation databases," tech. rep., Center for Applied Internet Data Analysis, 2011. https://catalog.caida.org/paper/2011_geocompare_tr.
- [91]
-
I. Livadariu, A. Elmokashfi, A. Dhamdhere, and kc claffy, "A first look at IPv4 transfer markets," in CoNEXT, 2013.
- [92]
-
Alberto Dainotti and Phillipa Gill, "NSF CNS-1423659. HIJACKS: Detecting and Characterizing Internet Traffic Interception based on BGP Hijacking," 2014. https://www.caida.org/funding/hijacks/.
- [93]
-
CAIDA, "AS Classification: method for classifying ASes according to business type," 2016. https://www.caida.org/catalog/datasets/as-classification/.
- [94]
-
G. Huston, "The death of transit," October 2016. https://blog.apnic.net/2016/10/28/the-death-of-transit/.
- [95]
-
Mark Jamison, "Do We Need the FCC?," Tech Policy Daily, December 2016. http://www.techpolicydaily.com/communications/do-we-need-the-fcc/.
- [96]
-
W. Lehr, E. Kenneally, and S. Bauer, "The Road to an Open Internet is Paved with Pragmatic Disclosure and Transparency Policies," in Telecommunications Policy Research Conference (TPRC), Sep 2015.
- [97]
-
k. claffy, D. Clark, S. Bauer, and A. Dhamdhere, "Policy challenges in mapping Internet interdomain congestion," in Telecommunications Policy Research Conference (TPRC), Oct 2016.
- [98]
-
Rob Frieden, "Case Studies in Abandoned Empiricism and the Lack of Peer Review at the Federal Communications Commission," August 2009. https://ssrn.com/abstract=1456516.
- [99]
-
S. Elaluf-Calderwood and J. Liebenau, "Idea to Retire: Internet without policy metrics," March 2016. https://www.brookings.edu/blog/techtank/2016/03/02/idea-to-retire-internet-without-policy-metrics/.
Footnotes:
File translated from TEX by TTH, version 4.03.
On 7 Aug 2017, 12:44.